现在市面上有各种各样的智能音箱,那他们的对话功能是怎么实现的呢?
通常情况下文本类内容的需求都是采用类似搜索引擎的文本相似度检索方式;其他非文本类精准需求例如定个闹铃/听个歌曲等,需要对query进行更深度的识别和解析才能更好的满足。
本文针对后者,介绍一种基于规则推导的query结构分析方法,它基于Trie Tree,实现对用户提问query的需求识别和问题的结构化解析。我们称这类模块为DA,通常包含需求识别(trigger)、需求解析(parser)、需求发现(discovery)等。
TrieTree简介
- 单词查找树、键树,核心思想是空间换时间。
- 性质:根节点不包含字符,除根节点之外的每个节点仅包含一个字符;
- 从根节点到某一个节点,路径上经过的字符链接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符。
- 举例:下图中红点分别表示字符串abc、abcd、abd、b、bcd、efg、hii.

DA实现方法
需求分类(trigger)
即识别用户query需求的大分类。例如用户问“哪个恐龙跑的最快”是“动物”需求,“宝马五系多少钱”是“汽车”需求,这个需求的粒度可以根据识别需求再细分。
需求识别常用的方法包括模糊匹配、精准匹配、正则匹配、机器学习模型识别等,因实现比较简单,这里不再赘述。
需求解析(parser)
即解析出用户query中的关键信息。例如用户问“北京到上海机票”是“出行需求”,解析模块需要能解析出[from:北京][to:上海][type:airplane],以便于从数据中检索北京到上海的机票信息给用户。
实现思路
基于trie树来实现模式匹配。每一个节点代表状态,叶子节点代表模板匹配成功,并作为解析转移条件。
每个需求分类下需要构建两棵Trie树:模板树pattern和字典树term。字典树包含所有term词槽及对应的词典集合,包含个性化词槽(例如城市city.dict、交通方式type.dict等)+通用词槽(例如杂质词ignore.dict、同义词synonym.dict等);模版树是term词槽的拼装组合规则,例如[city][ignore][city][type]。
当query进入parser模块时,首先进入模版树查找词槽名,根据词槽名到对应字典树内进行query中词槽值的匹配,如果匹配成功,则进入模版树的下一个节点重复上一过程,否则则跳出当前模版树开始下一模版的匹配过程。
模版树/词典树,及解析过程
以用户问“哪个恐龙跑的最快?”为例:
trigger识别结果: [{‘type’: ‘animal-dinosaur’, ‘term’: {‘恐龙’: 1.0}}]
parser解析过程:(模版树与字典树交错进行)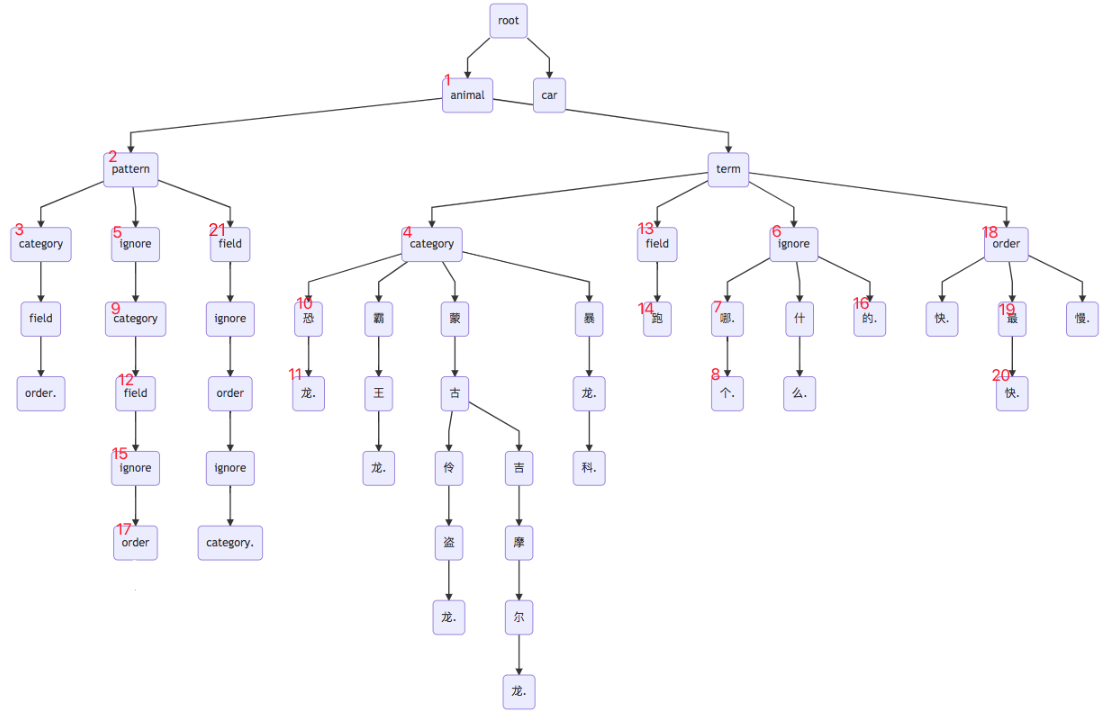
parser解析结果:
[{‘pattern’: ‘[ignore][category][field][ignore][order][ignore]’, ‘parser’: [(‘ignore’, ‘哪个’), (‘category’, ‘恐龙’), (‘field’, ‘跑’), (‘ignore’, ‘的’), (‘order’, ‘最快’), (‘ignore’, ‘?’)]}]
需求发现(discovery)
基于词槽的方式严重依赖词典的更新,而由人工保证词典更新是不现实的,例如新车上市,新名词的出现。这就依赖一个词槽词典的自动发现机制,例如搜索引擎中,某个新车上市,搜索这个车名的点调结果里,用户总是点击汽车之家的车系页,那么发现引擎就可以通过学习自动把这个车名补充到“车系”这个词槽的词典里,以实现da的自动发现和识别。
实例
# 用python实现了一个简单的da模块 https://github.com/yanjingang/pydp
pip install pydp
# 使用方法
da = Da(dict_path=CUR_PATH + "/data/da/") #DA模版和词典配置路径
# 意图分类
res = da.get_trigger("哪个恐龙跑的最快?")
#res = da.get_trigger("宝马3系报价")
print("trigger: {}".format(res))
# 意图分类下的query解析
res = da.get_parser(res[0]['type'], "哪个恐龙跑的最快?")
#res = da.get_parser(res[0]['type'], "宝马3系报价")
print("parser: {}".format(res))
*注:配置文件目录规则及格式参考 https://github.com/yanjingang/pydp/tree/master/dp/data/da
yan 2019.6.12 23:56
