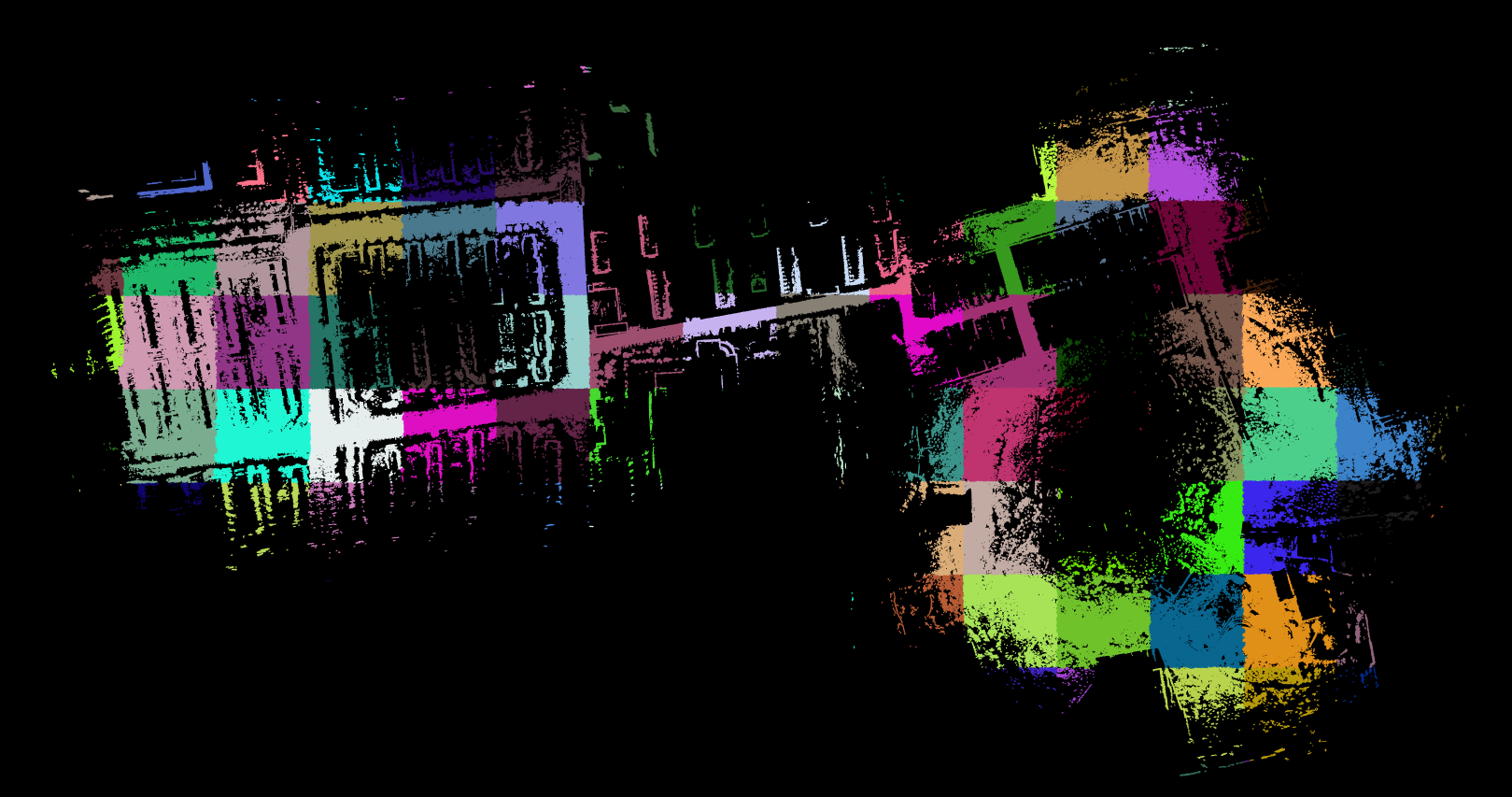
遇到采集的地图范围较大时,生成的点云地图也会比较大,例如我采集建图并进行0.1降采样的数据,PCD点云大约900M,这么大的点云points_map_loader是无法一次性加载并pub到topic给rviz展示的,必须进行点云分割和动态分块加载。本文就带大家一起尝试下解决方法。
遇到采集的地图范围较大时,生成的点云地图也会比较大,例如我采集建图并进行0.1降采样的数据,PCD点云大约900M,这么大的点云points_map_loader是无法一次性加载并pub到topic给rviz展示的,必须进行点云分割和动态分块加载。本文就带大家一起尝试下解决方法。

上一次,我们使用Autoware成功进行了ndt定位和导航,但是GNSS初始定位以及修正功能没有正常生效。行走途中遇到剧烈颠簸、非常狭小的空间、遮挡严重、或其他ndt局部定位特征不足时,ndt_matching会找不到自己位置导致定位飞。

上一次,我们使用lio-sam、ndt-mapping分别尝试构建小区和公园的地图,今天我们继续下一步,地图来进行定位和导航的验证。
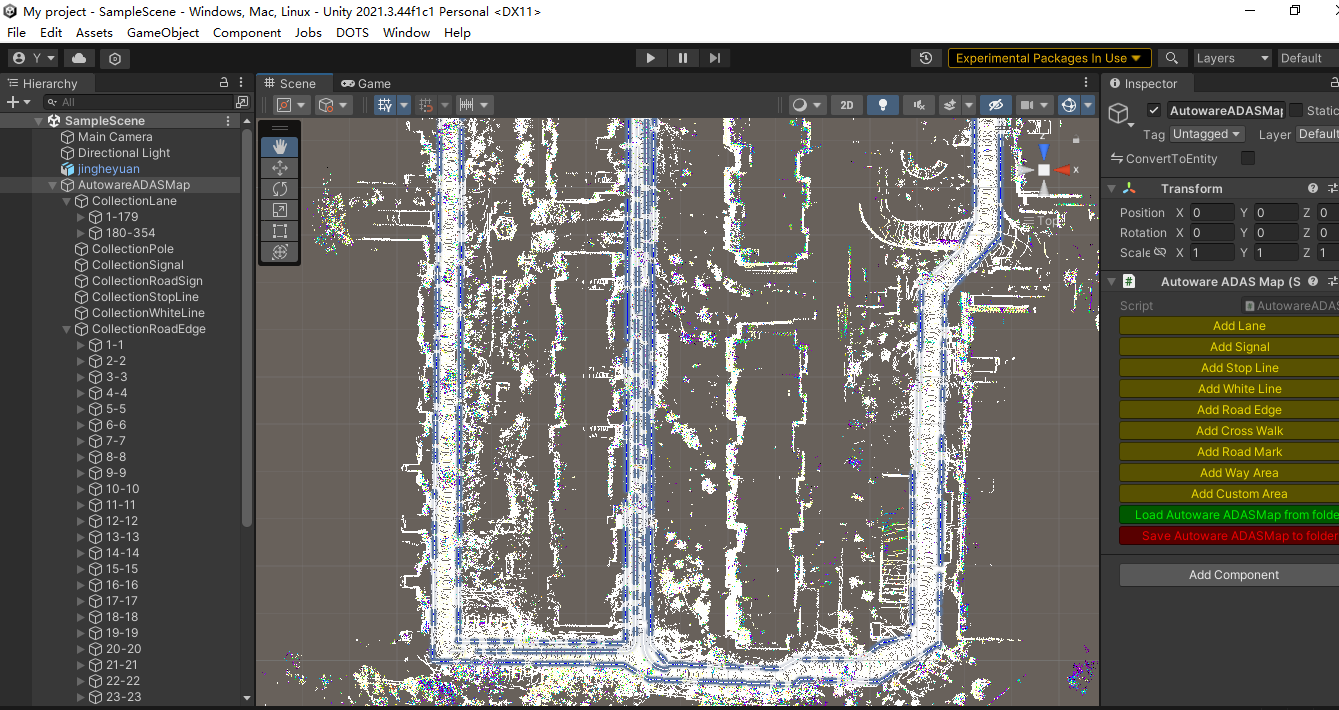
上一次,我们使用ndt-mapping构建了一个PCD点云地图,在开始Autoware的导航之前,单靠点云地图是不够的,我们需要先绘制矢量地图,来约束可行驶的区域、方向等,然后再继续导航环节的验证。
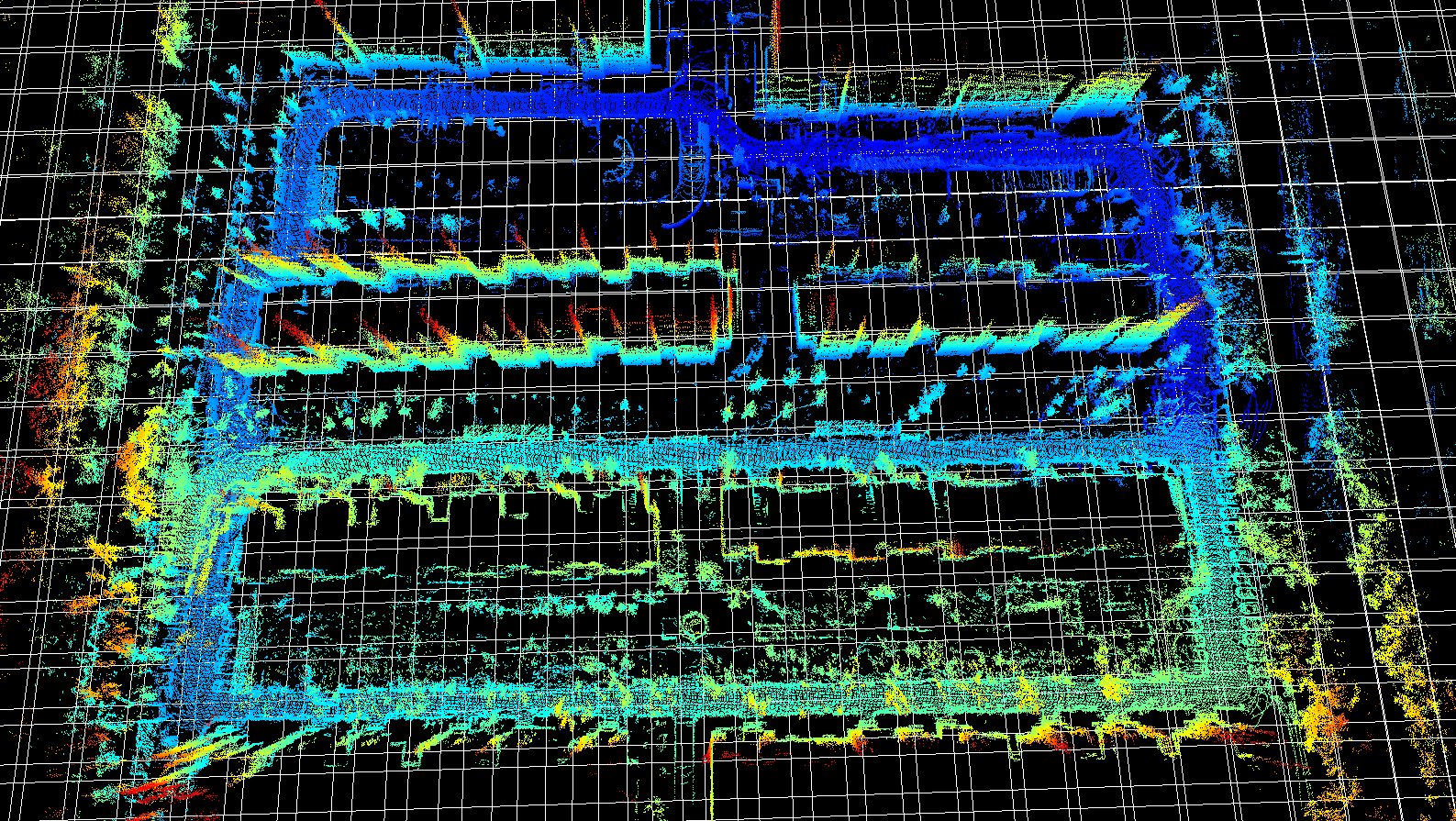
LIO-SAM对输入的点云/imu数据太敏感,道路距离过窄过宽都容易建图失败,在没有建筑物的公园基本用不了。因此本文尝试使用对特征点要求相对较少的ndt算法,来看看在小区或公园等场景的建图效果。
由于LIO-SAM在公园等树木多特征少的场景效果不太好,但NDT是集成在Autoware.ai 1.x版本里的,这里记录下部署编译过程。

今天新到一个G70 RTK定位模块,它支持多种卫星导航系统,包括中国BDS北斗,美国GPS,俄罗斯GLONASS、欧洲Galileo,日本QZSS卫星定位系统。G70内置RTCM更正,通过本地基站或网络 RTK设置中的虚拟参考站(VRS),可以支持厘米级定位。

今天开始尝试使用Lidar+IMU进行3D SLAM建图,本文记录下实验过程。
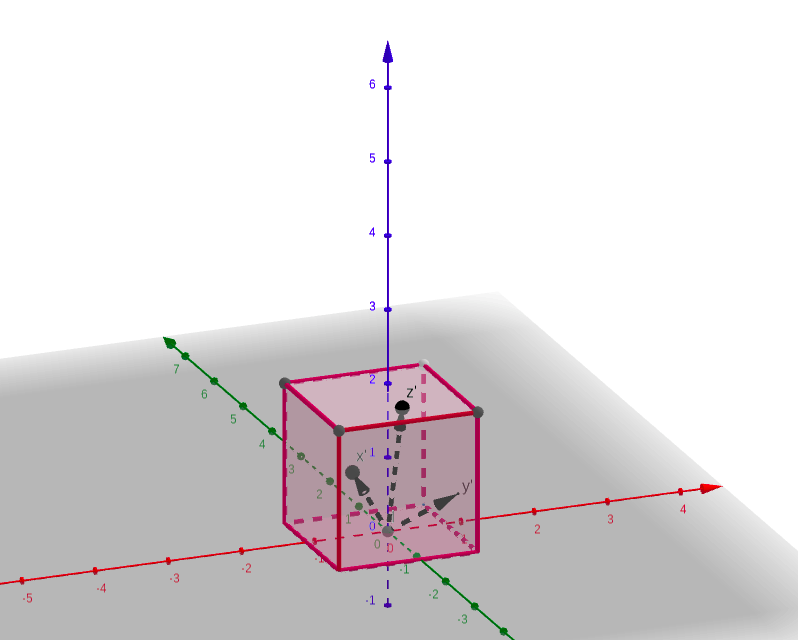
在使用LIO-SAM进行Lidar+IMU建图之前,需要做两个标定工作,IMU内参标定和Lidar-IMU外参标定。IMU内参标定,可以解决其固有的测量误差问题;Lidar和IMU的外参标定(以下简称“外参标定”)。外参标定的目的是获得激光雷达和IMU之间的位置转换关系,其中包括平移关系和旋转关系,分别对应最终输出结果中的平移向量与旋转矩阵。
今天新到一个九轴IMU – H30,它是一款高精度的姿态传感器,集成三轴 MEMS 陀螺仪、三轴 MEMS加速度计和三轴磁传感器,可以测量载体的三维姿态角度、加速度、角速度和磁场强度信息,实现 0.1°横滚、俯仰角测量精度和 0.5°无参考航向角、1°磁参考航向角测量精度,最大输出频率200HZ。
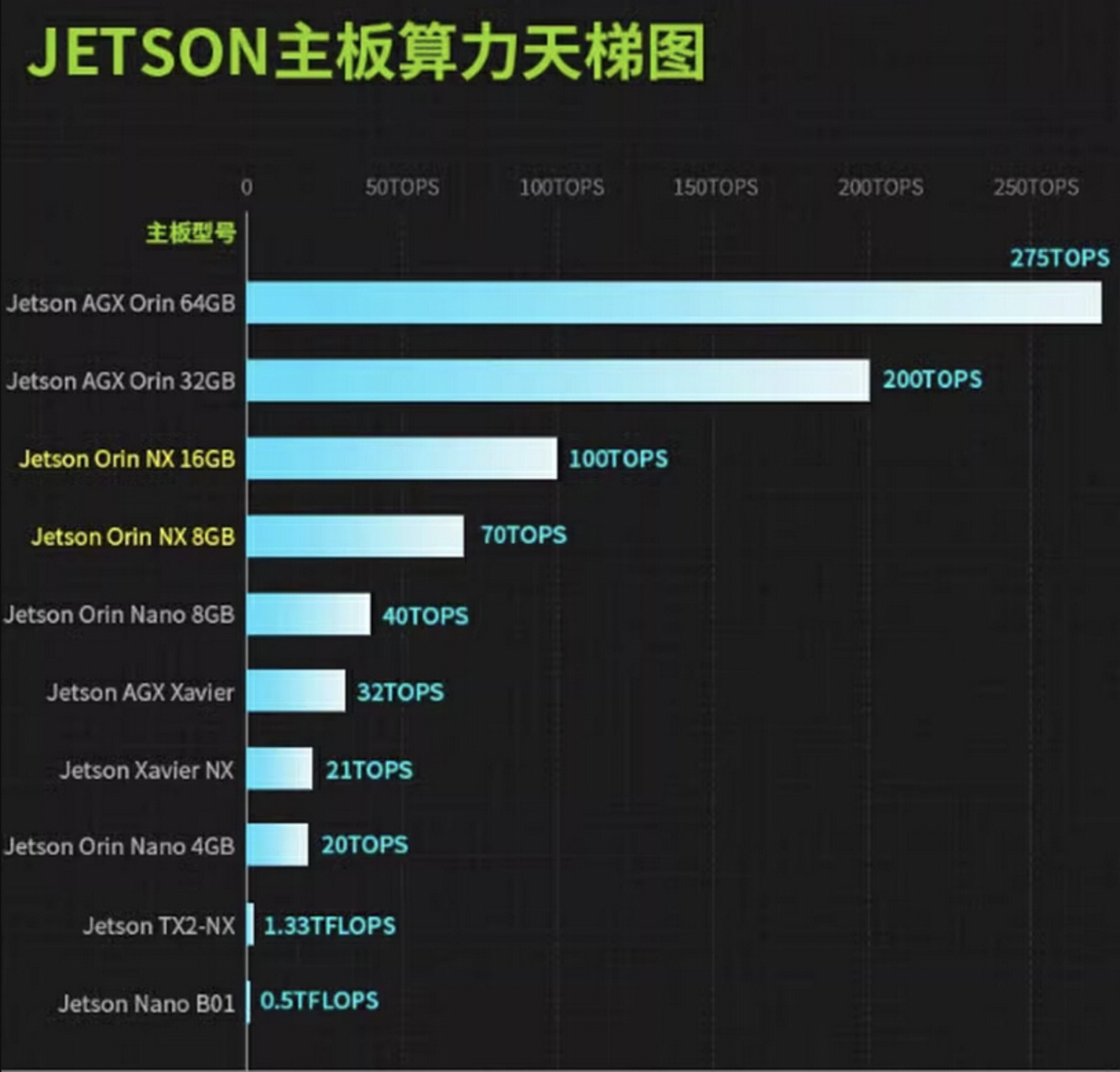
新到一块Nvidia Jetson AGX Orin 32G的板子,想压测下GPU性能时发现里边没有带CUDA,重新刷下机,记录下刷机过程。
在 Ubuntu22.04 + Orin Arm 中构建 tensorrt_common 时,出现未找到 TENSORRT_NVPARSERS_LIBRARY 变量错误。
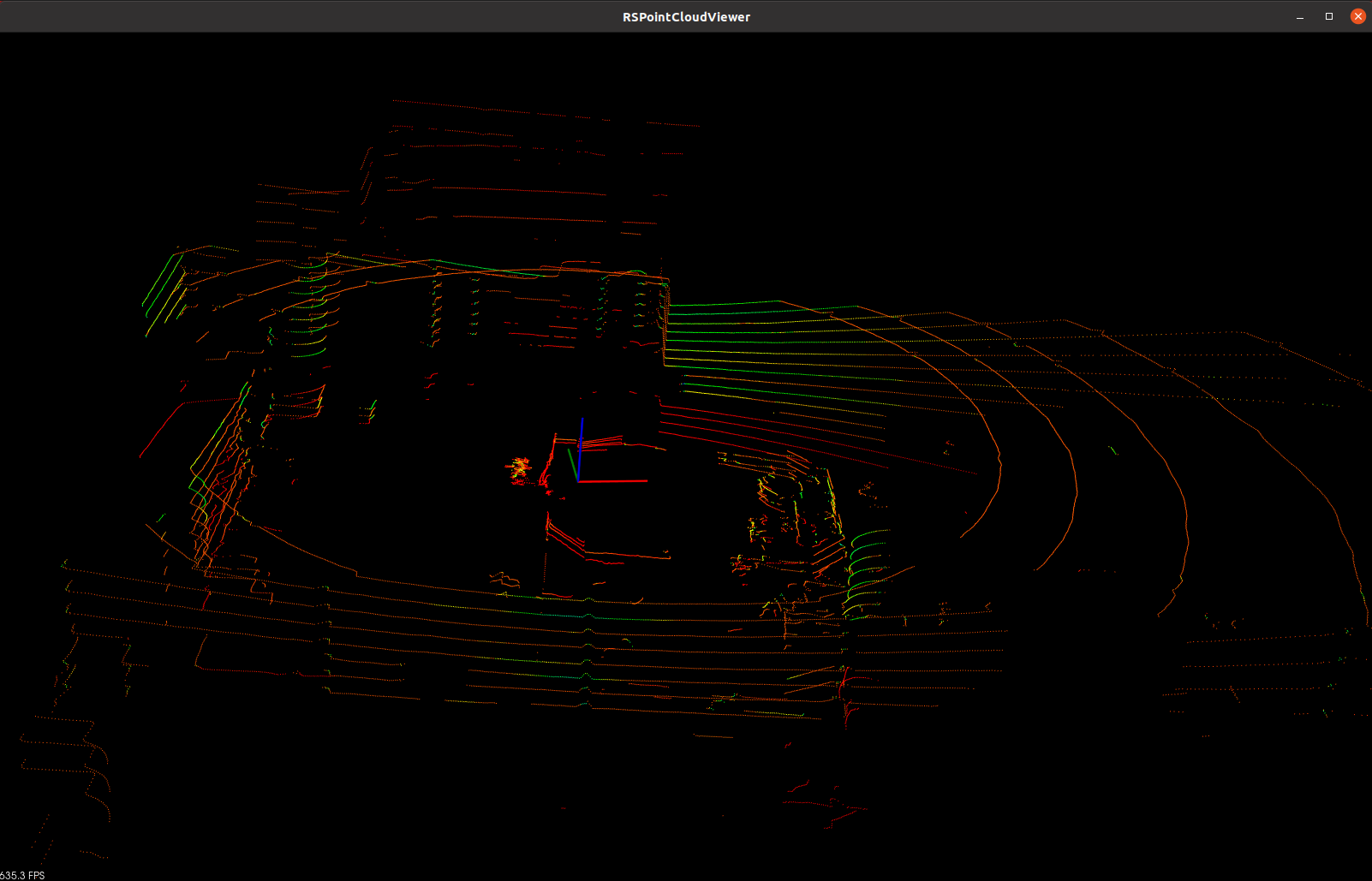
在Ubuntu 22.04上调试RS16的3D建图,发现ROS2无法正常显示点云,尝试使用官方的RSView工具也无法正常显示点云。
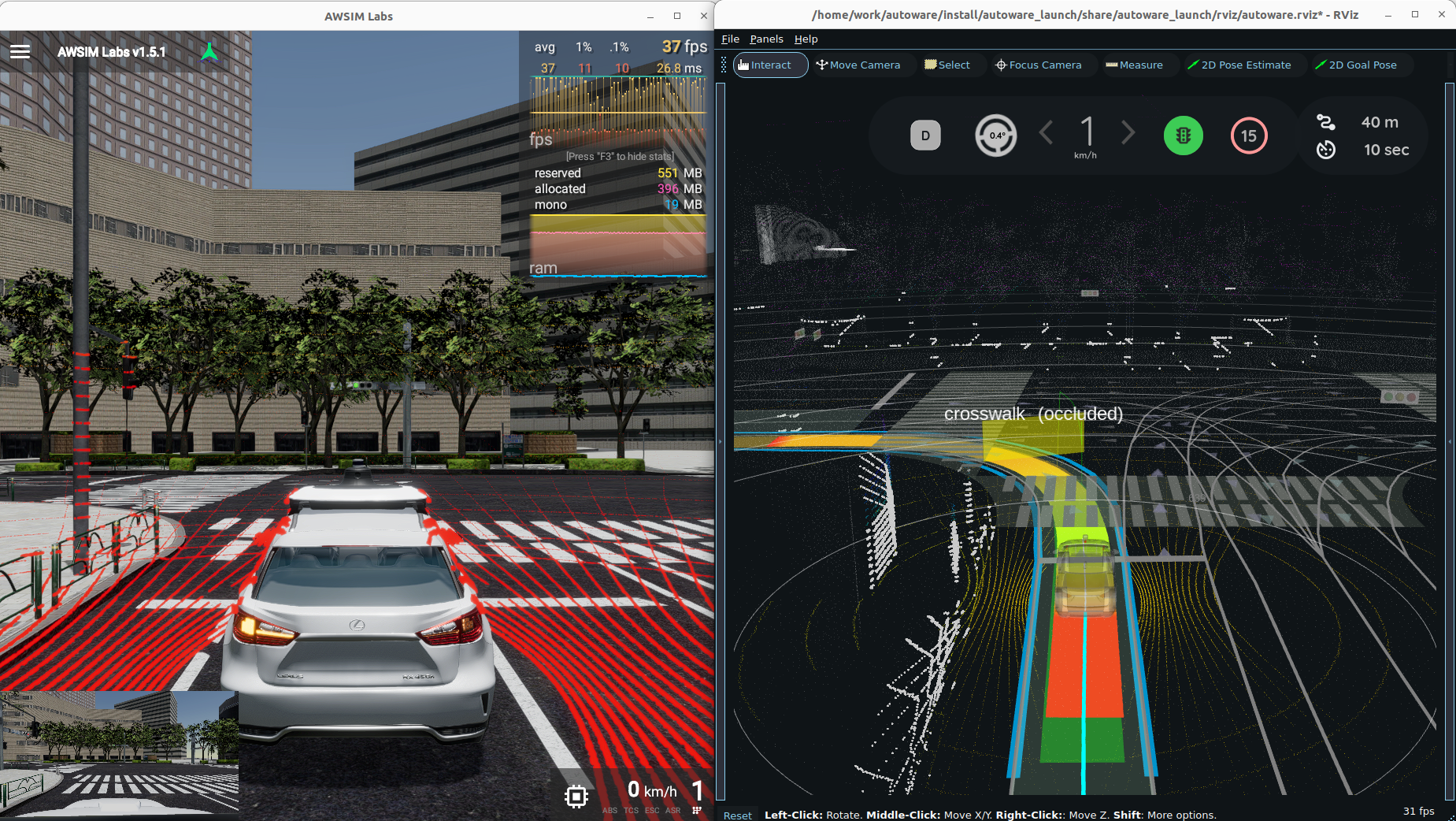
上次我们大概了解了Autoware是什么,以及它的基本原理。作为一个完备的自动驾驶框架,Autoware看起来很有吸引力,那么今天就带大家动手实践下,看它是不是像描述的那么好用。
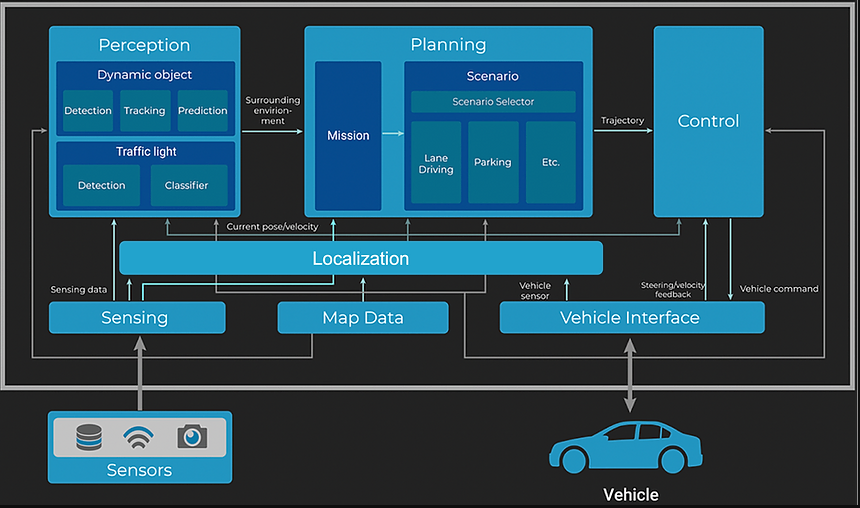
Autoware与Apollo类似,是2015年发布的开源自动驾驶项目,它基于机器人操作系统 ( ROS 2 ) ,包含Map Server、Sensor Drivers、Perception、Prediction、Localization、Planning、Control、Vehicle Interface、User Interface等完备的自动驾驶模块,对自动驾驶汽车在各种平台和应用程序上的商业部署起到了积极的推动作用。

2、机械底盘、线控底盘、滑板底盘与AGV、IGV、AMR
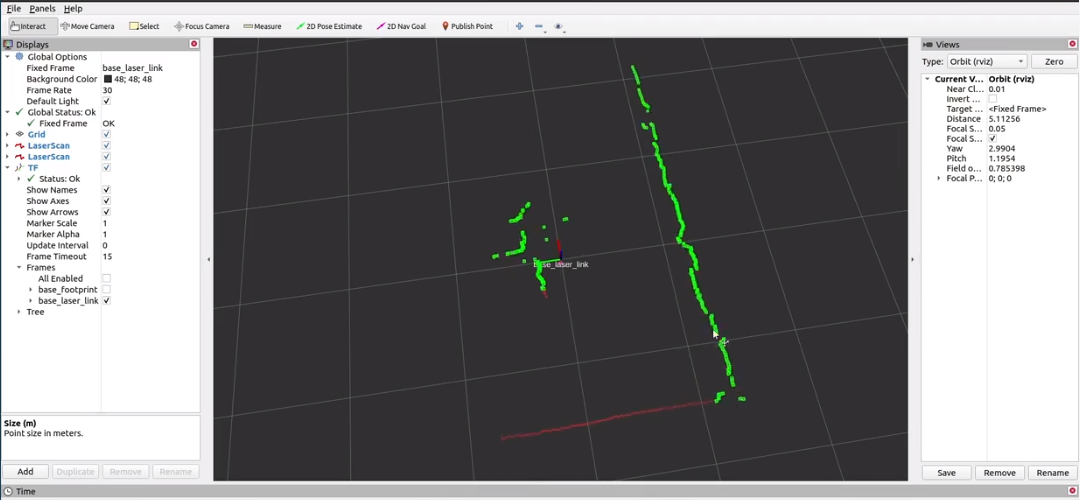
激光雷达通常可以检测360度等范围内的物体,但由于机械结构设计等原因,机器人本体可能会遮挡部分激光雷达扫描数据。如果将激光雷达原始点云直接用于建图或导航,则机器人本体的一部分会被当作障碍物导致建图或导航无法正常工作。

我们在使用SLAM建图后,为了提高显示及运行效果,通常需要对地图进行一些调整,比如点云毛刺清理、增加未知区域的边界防护等。本文主要讲解下如何对2D .gpm地图文件进行编辑修改的方法。
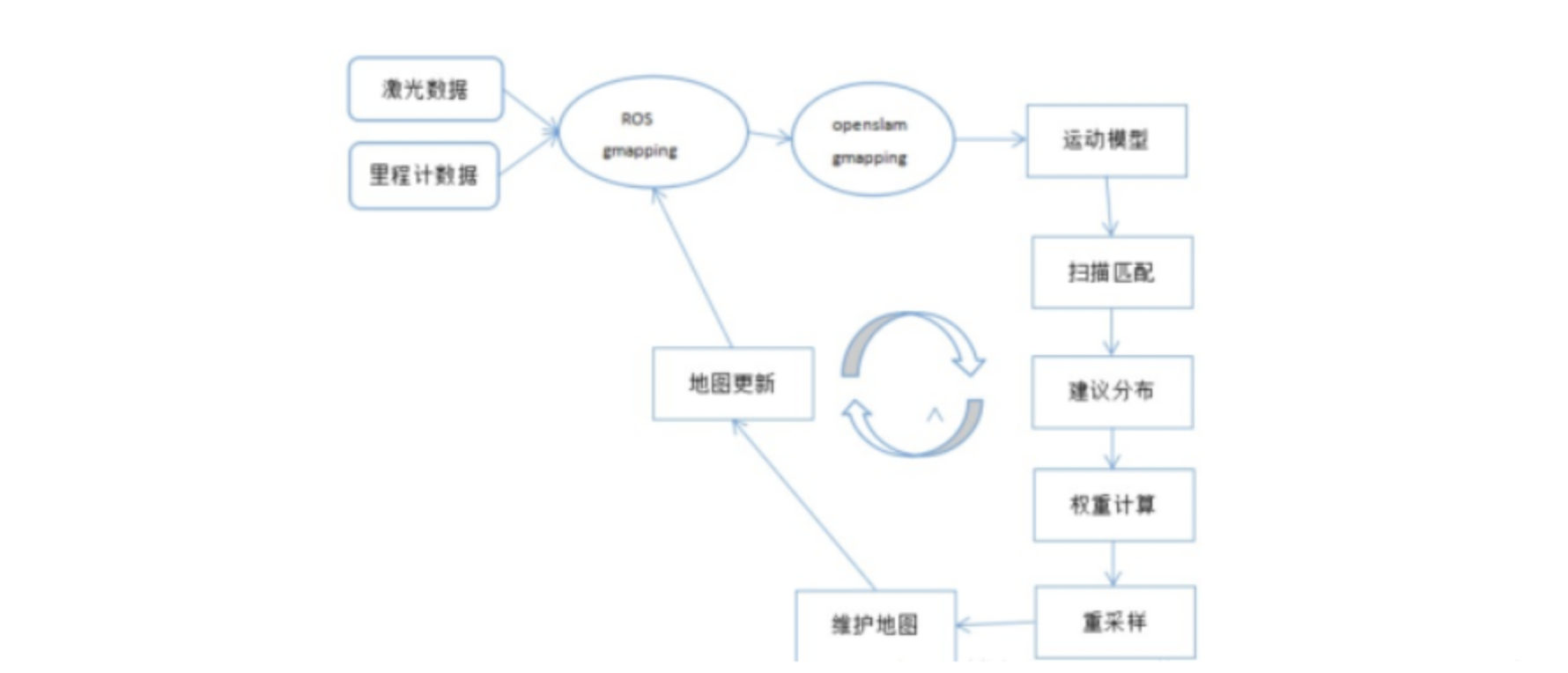
本文主要针对常见的2D建图算法Gmapping、Hector、Karto、Cartographer进行对比,以确定在室内小场景、室外大场景下使用哪种建图算法更为合适。
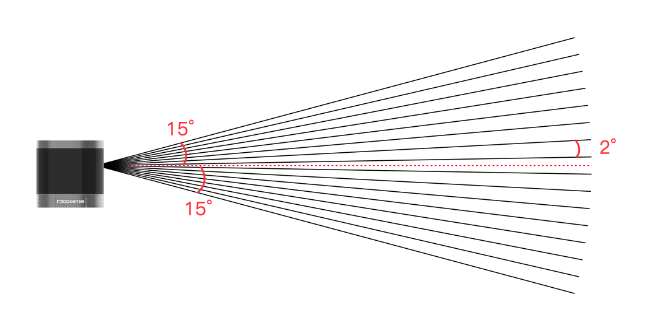
RS-LiDAR-16是速腾聚创推出的16线激光雷达,是一颗非常小型的激光雷达,主要面向无人驾驶汽车环境感知、机器人环境感知、无人机测绘等领域。RS16采用混合固态激光雷达方式,集合了16 个激光收发组件,最大探测距离150米,测量精度+/- 2cm以内。通过激光扫描反射提供三维空间点云数据及物体反射率,为定位、导航、避障等提供有力的保障。