
概述
前段时间尝试了手写数字的识别,因为模型是使用比较干净的黑底白字图片训练的,直接拿拍的手写照片识别效果不太好,无论是拍照时光线的明暗不均匀、笔的粗细、纸张的边缘等都对模型识别有很大影响,所以当时在模型识别前做了大量的图片预处理工作才使实际的应用准确率得到提升。难道图片的识别都要做如此复杂的预处理吗?
前段时间尝试了手写数字的识别,因为模型是使用比较干净的黑底白字图片训练的,直接拿拍的手写照片识别效果不太好,无论是拍照时光线的明暗不均匀、笔的粗细、纸张的边缘等都对模型识别有很大影响,所以当时在模型识别前做了大量的图片预处理工作才使实际的应用准确率得到提升。难道图片的识别都要做如此复杂的预处理吗?

通用图像分类公开的标准数据集常用的有CIFAR、ImageNet、COCO等,常用的细粒度图像分类数据集包括CUB-200-2011、Stanford Dog、Oxford-flowers等。其中ImageNet数据集规模相对较大,大量研究成果基于ImageNet。ImageNet数据从2010年来稍有变化,常用的是ImageNet-2012数据集,该数据集包含1000个类别:训练集包含1,281,167张图片,每个类别数据732至1300张不等,验证集包含50,000张图片,平均每个类别50张图片。
为了做车牌识别训练,先单独研究下怎么从照片里扣出车牌区域。
mark
MNIST 数据集是一个手写数字识别训练数据集,来自美国国家标准与技术研究所National Institute of Standards and Technology (NIST)。训练集 (training set) 由来自 250 个不同人手写的数字构成,其中 50% 是高中学生,50% 来自人口普查局 (the Census Bureau) 的工作人员。测试集(test set) 也是同样比例的手写数字数据。
前段时间忙了好一阵,终于有时间继续学习了,今天开始通过paddlepaddle的手写数字识别看一下简单的cnn图像识别模型是怎么训练出来的。
word embedding的意思是:给出一个文档,文档就是一个单词序列比如 “A B A C B F G”, 希望对文档中每个不同的单词都得到一个对应的向量(往往是低维向量)表示。
比如,对于这样的“A B A C B F G”的一个序列,也许我们最后能得到:A对应的向量为[0.1 0.6 -0.5],B对应的向量为[-0.2 0.9 0.7] (此处的数值只用于示意)
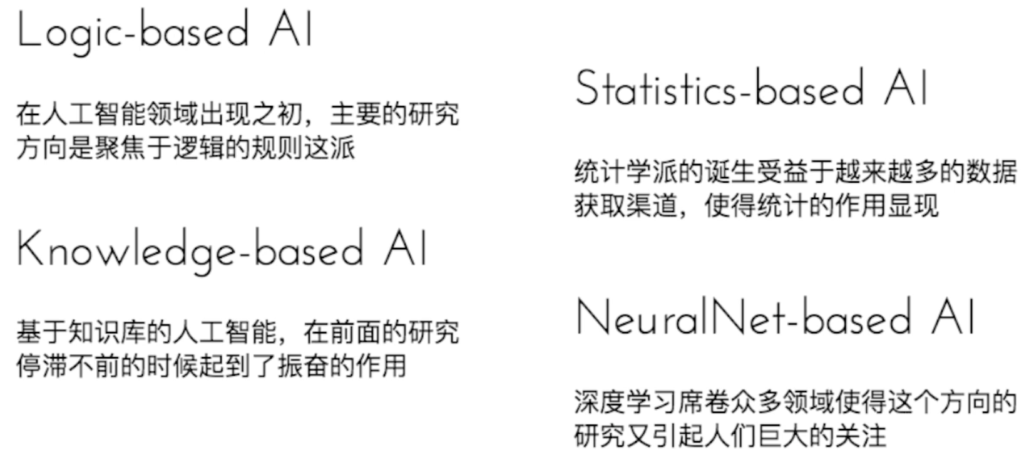
人工智能研究方向演变:规则->统计->知识->深度学习
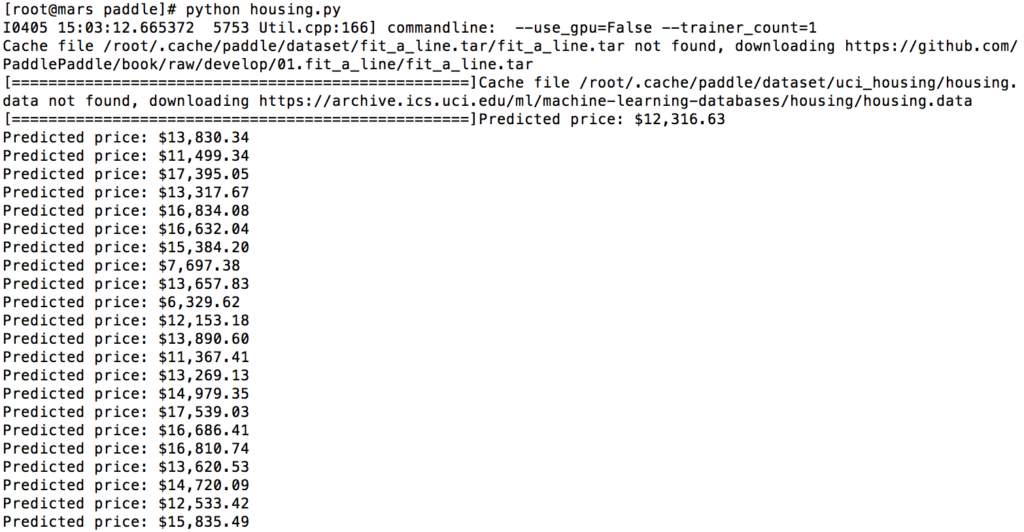
上次我们进行了简单的环境安装和模型应用尝试,今天开始通过paddlepaddle的房价预测看一下简单的线性回归有监督模型是怎么训练出来的。
官网:http://www.paddlepaddle.org/

2013年发布至今, Docker 一直广受瞩目,被认为可能会改变软件行业。