概述
前段时间尝试了手写数字的识别,因为模型是使用比较干净的黑底白字图片训练的,直接拿拍的手写照片识别效果不太好,无论是拍照时光线的明暗不均匀、笔的粗细、纸张的边缘等都对模型识别有很大影响,所以当时在模型识别前做了大量的图片预处理工作才使实际的应用准确率得到提升。难道图片的识别都要做如此复杂的预处理吗?
本文以猫狗的分类识别为例,给大家讲解一下如何直接使用带有大量干扰背景的彩色图片训练一个能识别图片是猫还是狗的模型。

数据准备
训练数据采用kaggle大数据竞赛平台上的dog vs cat数据集,可以从kaggle下载:
https://www.kaggle.com/c/dogs-vs-cats
由于kaggle的test数据集没有label,所以把训练集中的*0.jpg作为测试集。训练集示例:
模型介绍
图像识别领域大量的研究成果都是建立在PASCAL VOC、ImageNet等公开的数据集上,很多图像识别算法通常在这些数据集上进行测试和比较。PASCAL VOC是2005年发起的一个视觉挑战赛,ImageNet是2010年发起的大规模视觉识别竞赛(ILSVRC)的数据集,在本章中我们基于这些竞赛的一些论文介绍图像分类模型。
在2012年之前的传统图像分类方法可以用背景描述中提到的三步完成,但通常完整建立图像识别模型一般包括底层特征学习、特征编码、空间约束、分类器设计、模型融合等几个阶段。
1). 底层特征提取: 通常从图像中按照固定步长、尺度提取大量局部特征描述。常用的局部特征包括SIFT(Scale-Invariant Feature Transform, 尺度不变特征转换) [1]、HOG(Histogram of Oriented Gradient, 方向梯度直方图) [2]、LBP(Local Bianray Pattern, 局部二值模式) [3] 等,一般也采用多种特征描述子,防止丢失过多的有用信息。
2). 特征编码: 底层特征中包含了大量冗余与噪声,为了提高特征表达的鲁棒性,需要使用一种特征变换算法对底层特征进行编码,称作特征编码。常用的特征编码包括向量量化编码 [4]、稀疏编码 [5]、局部线性约束编码 [6]、Fisher向量编码 [7] 等。
3). 空间特征约束: 特征编码之后一般会经过空间特征约束,也称作特征汇聚。特征汇聚是指在一个空间范围内,对每一维特征取最大值或者平均值,可以获得一定特征不变形的特征表达。金字塔特征匹配是一种常用的特征聚会方法,这种方法提出将图像均匀分块,在分块内做特征汇聚。
4). 通过分类器分类: 经过前面步骤之后一张图像可以用一个固定维度的向量进行描述,接下来就是经过分类器对图像进行分类。通常使用的分类器包括SVM(Support Vector Machine, 支持向量机)、随机森林等。而使用核方法的SVM是最为广泛的分类器,在传统图像分类任务上性能很好。
这种方法在PASCAL VOC竞赛中的图像分类算法中被广泛使用 [18]。NEC实验室在ILSVRC2010中采用SIFT和LBP特征,两个非线性编码器以及SVM分类器获得图像分类的冠军 [8]。
Alex Krizhevsky在2012年ILSVRC提出的CNN模型 [9] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet。这也是首次将深度学习用于大规模图像分类中。从AlexNet之后,涌现了一系列CNN模型,不断地在ImageNet上刷新成绩,如下图展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,降到了3.5%附近。而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
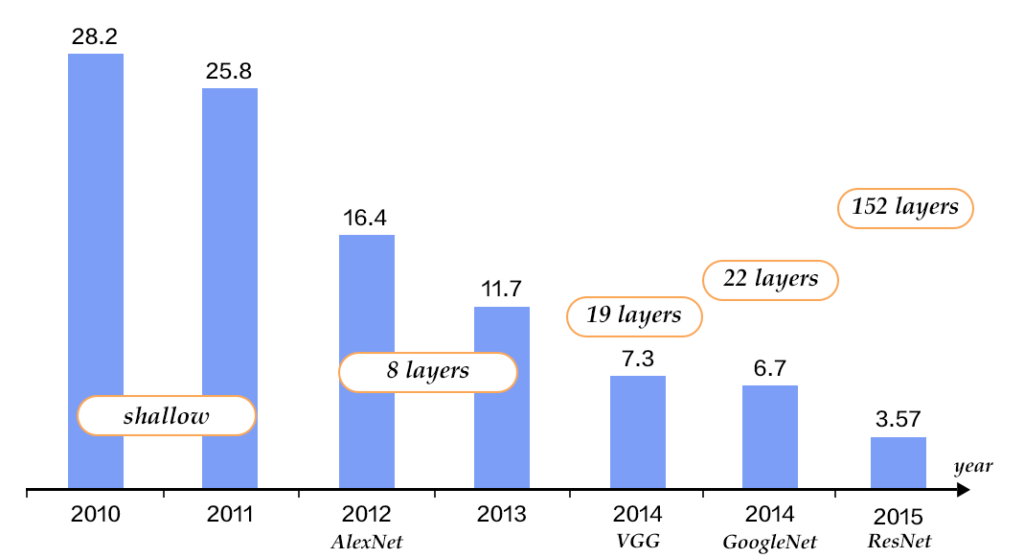
ILSVRC图像分类Top-5错误率
CNN
传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数,一个典型的卷积神经网络如图所示,我们先介绍用来构造CNN的常见组件。

CNN网络示例
- 卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。
- 池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
- 全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。
- 非线性变化: 卷积层、全连接层后面一般都会接非线性变化层,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。
- Dropout [10] : 在模型训练阶段随机让一些隐层节点权重不工作,提高网络的泛化能力,一定程度上防止过拟合。
另外,在训练过程中由于每层参数不断更新,会导致下一次输入分布发生变化,这样导致训练过程需要精心设计超参数。如2015年Sergey Ioffe和Christian Szegedy提出了Batch Normalization (BN)算法 [14] 中,每个batch对网络中的每一层特征都做归一化,使得每层分布相对稳定。BN算法不仅起到一定的正则作用,而且弱化了一些超参数的设计。经过实验证明,BN算法加速了模型收敛过程,在后来较深的模型中被广泛使用。
接下来我们主要介绍VGG,GoogleNet和ResNet网络结构。
VGG
牛津大学VGG(Visual Geometry Group)组在2014年ILSVRC提出的模型被称作VGG模型 [11] 。该模型相比以往模型进一步加宽和加深了网络结构,它的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,下图展示一个16层的网络结构。VGG模型结构相对简洁,提出之后也有很多文章基于此模型进行研究,如在ImageNet上首次公开超过人眼识别的模型[19]就是借鉴VGG模型的结构。
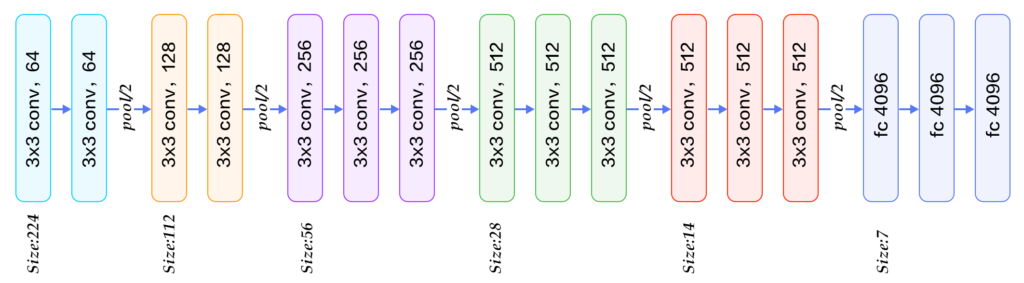
基于ImageNet的VGG16模型
GoogleNet
GoogleNet [12] 在2014年ILSVRC的获得了冠军,在介绍该模型之前我们先来了解NIN(Network in Network)模型 [13] 和Inception模块,因为GoogleNet模型由多组Inception模块组成,模型设计借鉴了NIN的一些思想。
NIN模型主要有两个特点:
- 引入了多层感知卷积网络(Multi-Layer Perceptron Convolution, MLPconv)代替一层线性卷积网络。MLPconv是一个微小的多层卷积网络,即在线性卷积后面增加若干层1×1的卷积,这样可以提取出高度非线性特征。
- 传统的CNN最后几层一般都是全连接层,参数较多。而NIN模型设计最后一层卷积层包含类别维度大小的特征图,然后采用全局均值池化(Avg-Pooling)替代全连接层,得到类别维度大小的向量,再进行分类。这种替代全连接层的方式有利于减少参数。
Inception模块如下图所示,图(a)是最简单的设计,输出是3个卷积层和一个池化层的特征拼接。这种设计的缺点是池化层不会改变特征通道数,拼接后会导致特征的通道数较大,经过几层这样的模块堆积后,通道数会越来越大,导致参数和计算量也随之增大。为了改善这个缺点,图(b)引入3个1×1卷积层进行降维,所谓的降维就是减少通道数,同时如NIN模型中提到的1×1卷积也可以修正线性特征。
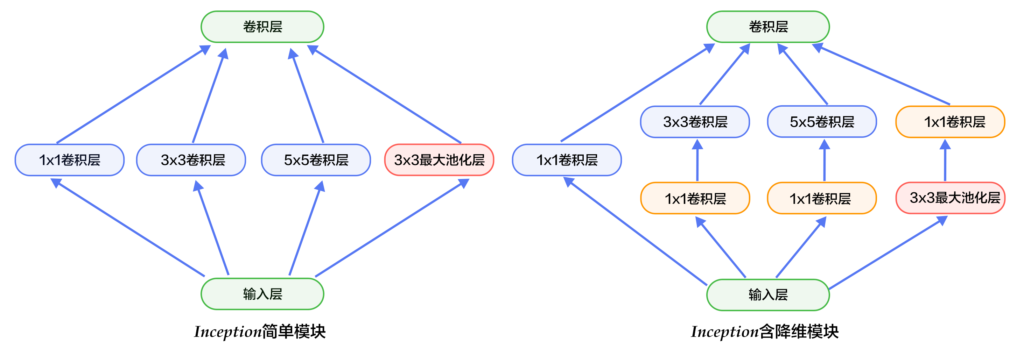
Inception模块
GoogleNet由多组Inception模块堆积而成。另外,在网络最后也没有采用传统的多层全连接层,而是像NIN网络一样采用了均值池化层;但与NIN不同的是,池化层后面接了一层到类别数映射的全连接层。除了这两个特点之外,由于网络中间层特征也很有判别性,GoogleNet在中间层添加了两个辅助分类器,在后向传播中增强梯度并且增强正则化,而整个网络的损失函数是这个三个分类器的损失加权求和。
GoogleNet整体网络结构如下图所示,总共22层网络:开始由3层普通的卷积组成;接下来由三组子网络组成,第一组子网络包含2个Inception模块,第二组包含5个Inception模块,第三组包含2个Inception模块;然后接均值池化层、全连接层。
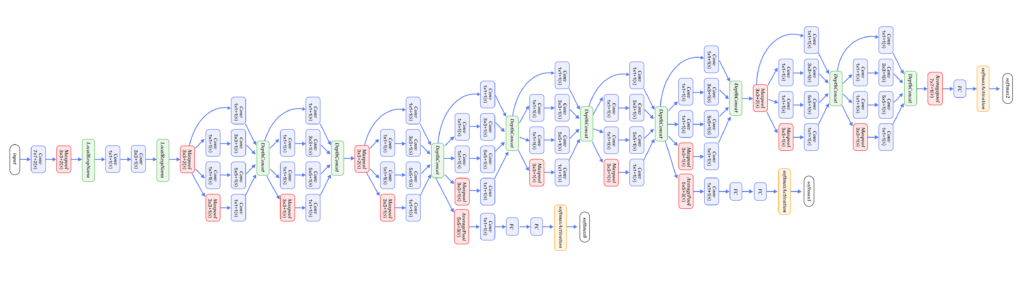
GoogleNet
上面介绍的是GoogleNet第一版模型(称作GoogleNet-v1)。GoogleNet-v2 [14] 引入BN层;GoogleNet-v3 [16] 对一些卷积层做了分解,进一步提高网络非线性能力和加深网络;GoogleNet-v4 [17] 引入下面要讲的ResNet设计思路。从v1到v4每一版的改进都会带来准确度的提升,介于篇幅,这里不再详细介绍v2到v4的结构。
ResNet
ResNet(Residual Network) [15] 是2015年ImageNet图像分类、图像物体定位和图像物体检测比赛的冠军。针对训练卷积神经网络时加深网络导致准确度下降的问题,ResNet提出了采用残差学习。在已有设计思路(BN, 小卷积核,全卷积网络)的基础上,引入了残差模块。每个残差模块包含两条路径,其中一条路径是输入特征的直连通路,另一条路径对该特征做两到三次卷积操作得到该特征的残差,最后再将两条路径上的特征相加。
残差模块如下图所示,左边是基本模块连接方式,由两个输出通道数相同的3×3卷积组成。右边是瓶颈模块(Bottleneck)连接方式,之所以称为瓶颈,是因为上面的1×1卷积用来降维(图示例即256->64),下面的1×1卷积用来升维(图示例即64->256),这样中间3×3卷积的输入和输出通道数都较小(图示例即64->64)。
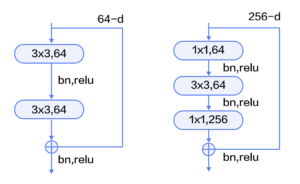
残差模块
下图展示了50、101、152层网络连接示意图,使用的是瓶颈模块。这三个模型的区别在于每组中残差模块的重复次数不同(见图右上角)。ResNet训练收敛较快,成功的训练了上百乃至近千层的卷积神经网络。
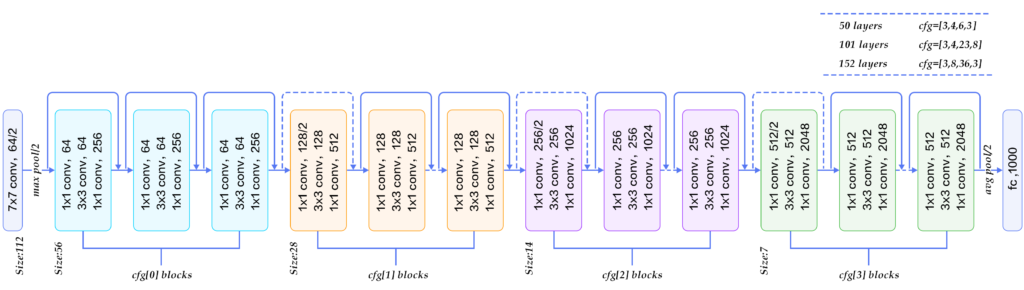
基于ImageNet的ResNet模型
本文使用paddle提供的resnet模型进行猫狗识别的训练。
训练
训练代码代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
File: train.py
Desc: 猫狗分类模型(resnet|vgg)
Author:yanjingang(yanjingang@mail.com)
Date: 2018/12/26 23:34
Cmd: python train.py
"""
from __future__ import print_function
import sys
import os
import paddle
import paddle.fluid as fluid
from paddle.fluid.contrib.trainer import *
from paddle.fluid.contrib.inferencer import *
import numpy
# PATH
CUR_PATH = os.path.dirname(os.path.abspath(__file__))
BASE_PATH = os.path.realpath(CUR_PATH + '/../../../')
sys.path.append(BASE_PATH)
# print(CUR_PATH, BASE_PATH)
from machinelearning.lib.resnet import resnet_cifar10
from machinelearning.lib import utils
def image_classification_network():
"""定义图像分类输入层及网络结构: resnet or vgg"""
# 输入层:The image is 32 * 32 with RGB representation.
data_shape = [3, 32, 32]
images = fluid.layers.data(name='img', shape=data_shape, dtype='float32')
# 网络模型
# resnet
predict = resnet_cifar10(images, 32)
# vgg
# predict = vgg_bn_drop(images) # un-comment to use vgg net
return predict
def optimizer_program():
"""定义优化器"""
return fluid.optimizer.Adam(learning_rate=0.001)
def train_network():
"""定义训练输入层、网络结果、label数据层、损失函数等训练参数"""
# 定义输入img层及网络结构resnet
predict = image_classification_network()
# 定义训练用label数据层
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
# 定义训练损失函数cost
cost = fluid.layers.cross_entropy(input=predict, label=label)
avg_cost = fluid.layers.mean(cost)
# accuracy用于在迭代过程中print
accuracy = fluid.layers.accuracy(input=predict, label=label)
return [avg_cost, accuracy]
# label名称
label_list = ["cat", "dog"]
def train(use_cuda, params_dirname="model"):
"""开始训练"""
if use_cuda and not fluid.core.is_compiled_with_cuda():
return
BATCH_SIZE = 128
EPOCH_NUM = 10 # Best pass is 6, classification accuracy is 83.51%
# 定义训练和测试数据batch reader
train_reader = paddle.batch(
paddle.reader.shuffle(
utils.image_reader_creator(CUR_PATH + '/data/train/', 32, 32, rgb=True, reshape1=True, label_split_midline=-1,
label_list=label_list) # 自己读取images
, buf_size=50000),
batch_size=BATCH_SIZE)
test_reader = paddle.batch(
utils.image_reader_creator(CUR_PATH + '/data/test/', 32, 32, rgb=True, reshape1=True, label_split_midline=-1,
label_list=label_list) # 自己读取images
, batch_size=BATCH_SIZE)
# 定义event_handler,输出训练过程中的结果
lists = []
def event_handler(event):
if isinstance(event, EndStepEvent):
if event.step % 100 == 0:
print("\nPass %d, Batch %d, Cost %f, Acc %f" %
(event.step, event.epoch, event.metrics[0],
event.metrics[1]))
else:
sys.stdout.write('.')
sys.stdout.flush()
if isinstance(event, EndEpochEvent):
avg_cost, accuracy = trainer.test(
reader=test_reader, feed_order=['img', 'label'])
print('\nTest with Pass {0}, Loss {1:2.2}, Acc {2:2.2}'.format(
event.epoch, avg_cost, accuracy))
if params_dirname is not None:
trainer.save_params(params_dirname)
# 保存训练结果损失情况
lists.append((event.epoch, avg_cost, accuracy))
# 创建训练器(train_func损失函数; place是否使用gpu; optimizer_func优化器)
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
trainer = Trainer(train_func=train_network, optimizer_func=optimizer_program, place=place)
# 开始训练模型
trainer.train(
reader=train_reader,
num_epochs=EPOCH_NUM,
event_handler=event_handler,
feed_order=['img', 'label'])
# 找到训练误差最小的一次结果(trainer.save_params()自动做了最优选择,这里只是为了验证EPOCH_NUM设置几次比较合理)
best = sorted(lists, key=lambda list: float(list[1]))[0]
print('Best pass is %s, testing Avgcost is %s' % (best[0], best[1]))
print('The classification accuracy is %.2f%%' % (float(best[2]) * 100))
def infer(use_cuda, params_dirname="model"):
"""使用模型测试"""
if use_cuda and not fluid.core.is_compiled_with_cuda():
return
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
inferencer = Inferencer(infer_func=image_classification_network, param_path=params_dirname, place=place)
img = utils.load_rgb_image(CUR_PATH + '/data/kaggle_infer/5.jpg')
# 预测
results = inferencer.infer({'img': img})
print("infer results: %s" % label_list[numpy.argmax(results[0])])
if __name__ == '__main__':
use_cuda = False
# train
train(use_cuda=use_cuda)
# infer
infer(use_cuda=use_cuda)
训练迭代了10轮,第6轮结果最优,模型保存到了./model目录内。
使用训练好的模型进行预测的代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
File: infer.py
Desc: 图像分类预测(resnet|vgg)
Author:yanjingang(yanjingang@mail.com)
Date: 2018/12/26 22:11
Cmd: python infer.py ./data/kaggle_infer/1.jpg
"""
from __future__ import print_function
import sys
import os
import getopt
import paddle.fluid as fluid
from paddle.fluid.contrib.trainer import *
from paddle.fluid.contrib.inferencer import *
import numpy
# PATH
CUR_PATH = os.path.dirname(os.path.abspath(__file__))
BASE_PATH = os.path.realpath(CUR_PATH + '/../../../')
sys.path.append(BASE_PATH)
#print(CUR_PATH, BASE_PATH)
from machinelearning.lib import utils
from machinelearning.lib import logger
from machinelearning.image.dog_cat import train as dogcat_train
# label名称
label_list = ["cat", "dog"]
def infer(img_file='', params_dirname=CUR_PATH, use_cuda=False):
"""使用模型测试"""
if use_cuda and not fluid.core.is_compiled_with_cuda():
return 1, 'compiled is not with cuda', {}
if img_file == '':
return 1, 'file_name is empty', {}
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
logger.debug('param_path:' + params_dirname + '/model')
inferencer = Inferencer(infer_func=dogcat_train.image_classification_network, param_path=params_dirname + '/model', place=place)
# 预测
img = utils.load_rgb_image(img_file)
# print(img.shape)
result = inferencer.infer({'img': img})
result = numpy.where(result[0][0] > 0.05, result[0][0], 0) # 概率<5%的直接设置为0
print(result)
label = numpy.argmax(result)
label_name = label_list[label]
weight = result[label]
print("*img: %s" % img_file)
print("*label: %d" % label)
print("*label_name: %s" % label_name)
print("*label weight: %f" % weight)
return 0, '', {'img': img_file, 'label': label, 'label_name': label_name, 'weight': str(weight)}
def kaggle_infer(kaggle_path=CUR_PATH + '/data/kaggle_infer/'):
"""
kaggle测试集预测
cat kaggle_infer.ori.csv|sort -n >kaggle_infer.csv
"""
# kaggle label (0:cat, 1:dog)
kaggle_labes = [
1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0,
0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1,
1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0,
]
succ = 0
errs = []
print(len(kaggle_labes))
# res file
fo = open(kaggle_path[:-1] + '.ori.csv', "w")
fo.write("id,label\n")
# test infer
imgs = os.listdir(kaggle_path)
for i in xrange(len(imgs)):
# print(imgs[i])
id = int(imgs[i].split('.')[0])
label = -1
label_name = ''
weight = 0.0
ret, msg, res = infer(kaggle_path + imgs[i])
# print(res)
if ret == 0:
label = res['label']
label_name = res['label_name']
weight = res['weight']
# acc手工标注准确率自动检查
if id <= len(kaggle_labes):
if label == kaggle_labes[id - 1]:
succ += 1
else:
errs.append(id)
line = str(id) + "," + str(label) + "," + str(label_name) + "," + str(weight) + "\n"
print("*kaggle_infer: " + line)
fo.write(line)
# break
# acc print
print("*kaggle_infer acc : " + str(succ / len(kaggle_labes)) + "\t errs:" + str(errs))
fo.close()
if __name__ == '__main__':
"""infer test"""
img_file = CUR_PATH + '/data/kaggle_infer/5.jpg'
opts, args = getopt.getopt(sys.argv[1:], "p:", ["file_name="])
if len(args) > 0 and len(args[0]) > 4:
img_file = args[0]
# infer
ret = infer(img_file)
print(ret)
# kaggle test infer
# kaggle_infer()单图预测:


识别出是猫,概率98.36%。

![]()
识别出是狗,概率98.72%
做了个微信小程序,直接拍照方便点,不用手动上传了…
晓晖家的猫:

地库车顶上的猫:

邻居家的狗:

另一个邻居家的狗:

yan 2018.12.29 15:37
参考:http://www.paddlepaddle.org/documentation/book/zh/develop/03.image_classification/index.cn.html
