概述
通用图像分类公开的标准数据集常用的有CIFAR、ImageNet、COCO等,常用的细粒度图像分类数据集包括CUB-200-2011、Stanford Dog、Oxford-flowers等。其中ImageNet数据集规模相对较大,大量研究成果基于ImageNet。ImageNet数据从2010年来稍有变化,常用的是ImageNet-2012数据集,该数据集包含1000个类别:训练集包含1,281,167张图片,每个类别数据732至1300张不等,验证集包含50,000张图片,平均每个类别50张图片。
由于ImageNet数据集较大,下载和训练较慢,为了方便快速学习图像分类,我们使用CIFAR10数据集。本文讲解如何将数据集反向重建为rgb彩色图片。
cifar10数据集共有60000张彩色图像,图像大小是3通道的32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。抽剩下的就随机排列组成了训练批。注意一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图。
数据的下载:共有三个版本:
python: http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
MATLAB: http://www.cs.toronto.edu/~kriz/cifar-10-matlab.tar.gz
bin: http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz
下图是从每个类别中随机抽取了10张图片,展示了所有的类别。

解析
我们下载python版本的数据集 cifar-10-python.tar.gz 并解压,可以看到有5个trainbatch文件,1个testbatch文件:
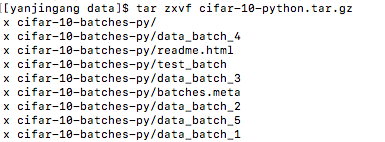
文件使用pickle格式压缩,所以需要使用python的pickle库进行读取:
import cPickle
data = {}
with open(file, 'rb') as fo:
data = cPickle.load(fo)
print(data.keys())
#data是个dict,包含图片像素数据data和对应label数据{'data':[],'labels':[],'...'}完整的读取并生成train/test图片的代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
File: read_cifar10.py
Desc: 读取cifar10数据集的图片和label,并生成以序号+label命名的图片
Author:yanjingang(yanjingang@mail.com)
Date: 2018/12/25 23:12
Cmd: nohup python read_cifar10.py >log/read_cifar10.log &
"""
import os
import random
import platform
import numpy
import subprocess
from PIL import Image
import utils
import cPickle
# cifar10训练集目录 from: http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
cifar10_path = './data/cifar-10-batches-py/'
train_batchs = [
cifar10_path + 'data_batch_1',
cifar10_path + 'data_batch_2',
cifar10_path + 'data_batch_3',
cifar10_path + 'data_batch_4',
cifar10_path + 'data_batch_5'
]
test_batchs = [cifar10_path + 'test_batch']
# 读取出的图片存放位置
output_path = './data/'
# label含义
label_list = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
def reader_cifar10(batchs, path='train'):
"""读取cifar10数据集的图片和label,并生成以序号-label-labelname命名的图片"""
id = 0 # 图片集序号
for file in batchs:
data = {}
with open(file, 'rb') as fo:
data = cPickle.load(fo)
print(data.keys())
# print(data['data'])
for i in xrange(len(data['data'])): # 遍历图片像素数据
id += 1
# 读取单张图片数据
img = data['data'][i]
label = data['labels'][i]
label_name = label_list[label]
print(img)
print(len(img))
print(str(label) + ' : ' + label_name)
# 重建rgb彩色图片
img = img.reshape(3, 32, 32)
print(img)
print(img.shape)
r = Image.fromarray(img[0]).convert('L')
g = Image.fromarray(img[1]).convert('L')
b = Image.fromarray(img[2]).convert('L')
new_img = Image.merge('RGB', (r, g, b))
# 保存图片(序号-label-labelname.png)
utils.mkdir(output_path + path)
save_file = output_path + path + '/' + str(id) + '-' + str(label) + '-' + label_name + '.png'
new_img.save(save_file)
print save_file
# if id > 10:
# break
# break
if __name__ == '__main__':
# 读取训练集
# reader_cifar10(train_batchs, path='train')
# 读取测试集
reader_cifar10(test_batchs, path='test')
单图片日志:

*注:可以看到单img像素数据是一个3072长度的一维数组,先reshape成3*32*32的r/g/b数据格式再merge成一张彩图。
生成的本地图片: 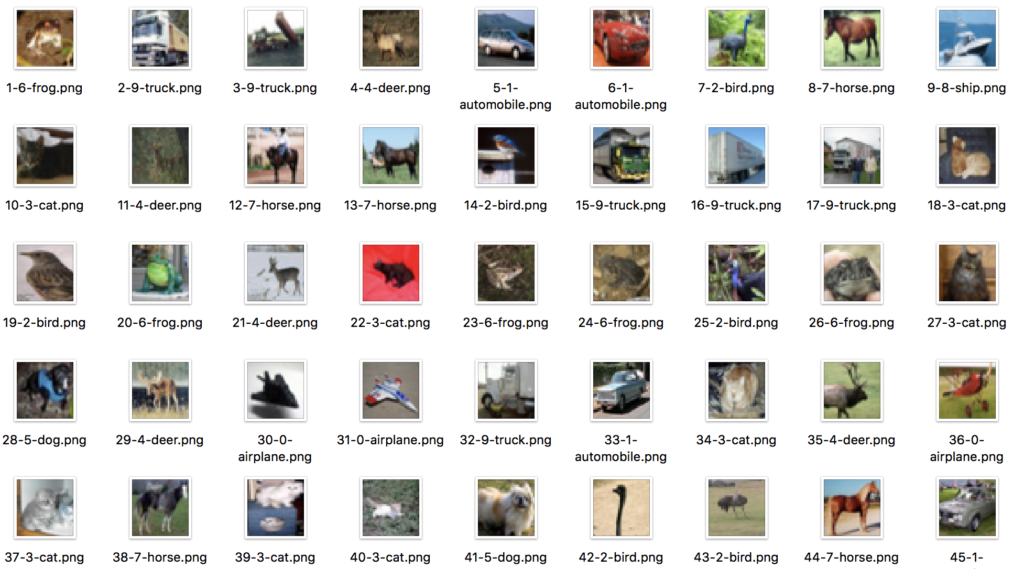
yan 18.12.25 23:36
参考:https://blog.csdn.net/jinxiaonian11/article/details/80192161
