一、概述
儿子的国际象棋水平渐长,我已经逐渐下不过他了,作为陪练水平这么不堪怎么能行?!可是自己研究棋谱的时间有点少,自认成为棋协大师的概率比较低,想来想去还是参考AlphaGo Zero做个AI吧,一方面有可能训练出一个大师级的AI做儿子的陪练对棋艺的提升有所帮助,另一方面刚好自己也能顺便学习强化学习。
本文以我学习五子棋、国际象棋的强化学习过程为例,给大家讲解一下如何让机器在仅知道走子规则的情况下通过自我博弈成为下棋高手。
废话不多说了,撸袖子开干,先从Google的两篇论文和基础概念开始:
1、Google论文
a.Mastering the game of Go with deep neural networks and tree search 用深度神经网络和树搜索征服围棋
原文:原文 译文:译文
b.Mastering-Chess-and-Shogi-by-Self-Play-with-a-General-Reinforcement-Learning-Algorithm 用通用强化学习自我对弈,掌握国际象棋和将棋
原文:原文 译文:译文
2、强化学习原理
强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境中,每个状态为机器对当前环境的感知;机器只能通过动作来影响环境,当机器执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。综合而言,强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
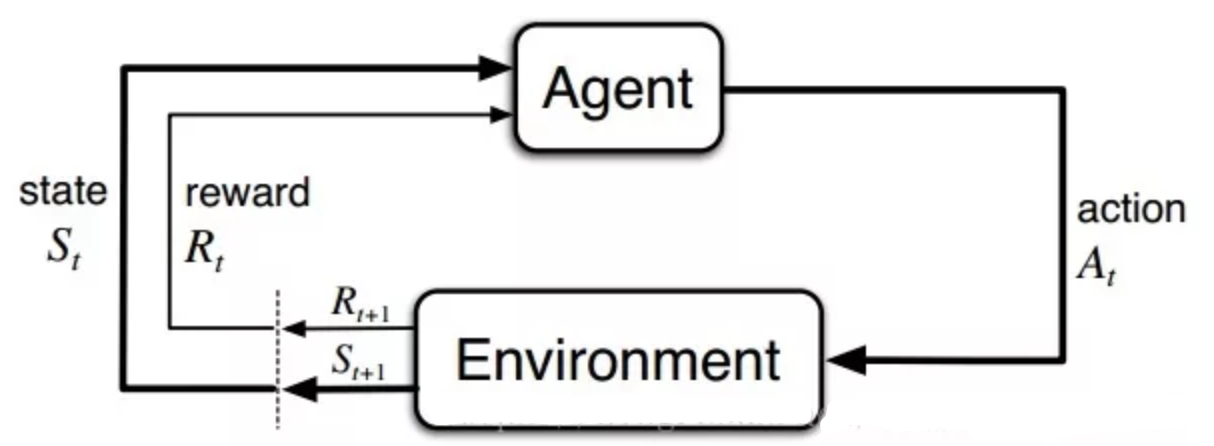
根据上图,agent(智能体)在进行某个任务时,首先与environment进行交互,产生新的状态state,同时环境给出奖励reward,如此循环下去,agent和environment不断交互产生更多新的数据。强化学习算法就是通过一系列动作策略与环境交互,产生新的数据,再利用新的数据去修改自身的动作策略,经过数次迭代后,agent就会学习到完成任务所需要的动作策略。
特点:
- 无特定数据,只有奖励信号
- 奖励信号不一定实时
- 主要研究时间序列的数据,而不是独立同分布的数据
- 当前行为影响后续数据
而深度强化学习使用了两个关键技术:
1、样本池(Experience Reply):将采集到的样本先放入样本池,然后从样本池中随机选出一条样本用于对网络的训练。这种处理打破了样本间的关联,使样本间相互独立。
2、固定目标值网络(Fixed Q-target):计算网络目标值需用到现有的Q值,现用一个更新较慢的网络专门提供此Q值。这提高了训练的稳定性和收敛性。
DQN在Atari games上用原始像素图片作为状态达到甚至超越人类专家的表现、通过左右互搏(self-play)等方式在围棋上碾压人类、大大降低了谷歌能源中心的能耗等等。当然DQN也有缺点,它是高维输入,低维输出的,当涉及到一次性输出连续动作时,即高维度输出,就束手无策了,DeepMind也在后续提出了DDPG。
根据前面知识可以意识到强化学习本身是非常通用了,智能体可以自己学习,如果和深度学习结合岂不是万能?错了,当前深度强化学习也有许多难点:
- 样本利用率低,需要长时间训练
- 很难设计奖励函数
- 对环境过拟合,比如去玩打砖块很擅长,却很难去适应俄罗斯方块
- 不稳定,函数对参数很敏感,参数的变动,模型会千差万别
未来可能方向:
- 与迁移学习结合,适应不同环境
- 硬件提升
- 融合更多的模型学习,充分利用样本
- 自主设定奖励函数
3、MCTS原理
mcts搜索树构建过程中黑白走子&反向传播示意图:
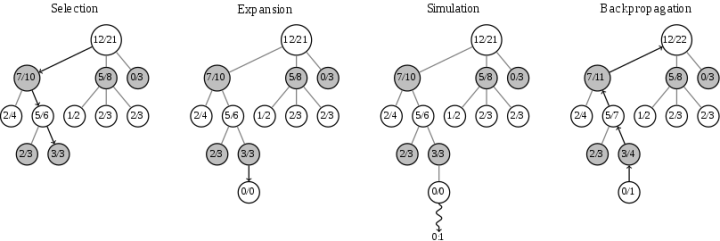
上图中每个节点代表一个局面。而 A/B 代表这个节点被访问 B 次,黑棋胜利了 A 次。例如一开始的根节点是 12/21,代表总共模拟了 21 次,黑棋胜利了 12 次。
我们将不断重复一个过程(很多万次):
- 选择(Selection)。从根节点往下走,每次都选一个“最值得看的子节点”(具体规则稍后说),直到来到一个叶子节点,如图中的 3/3 节点。
- 扩展(Expansion),我们给这个节点加上一个 0/0 子节点。
- 模拟(Simluation)。从上面这个新子节点开始,用快速走子策略(Rollout policy)模拟的后续对弈过程,直到博弈游戏结束,得到一个胜负结果。按照普遍的观点,快速走子策略适合选择一个棋力很弱但走子很快的策略。因为如果这个策略走得慢(比如用 AlphaGo 的策略网络走棋),虽然棋力会更强,结果会更准确,但由于耗时多了,在单位时间内的模拟次数就少了,所以不一定会棋力更强,有可能会更弱。这也是为什么我们一般只模拟一次,因为如果模拟多次,虽然更准确,但更慢。
- 反向传播(Backpropagation)。用模拟的结果输赢反向更新行动序列节点属性。例如第三步模拟的结果是 0/1(代表黑棋失败),那么就把这个节点的所有父节点加上 0/1。
纯mcts的非对称增长:

MCTS 执行一种非对称的树的适应搜索空间拓扑结构的增长。这个算法会更频繁地访问更加有趣的节点,并聚焦其搜索时间在更加相关的树的部分。
这使得 MCTS 更加适合那些有着更大的分支因子的博弈游戏,比如说 19X19 的围棋。这么大的组合空间会给标准的基于深度或者宽度的搜索方法带来问题,所以 MCTS 的适应性说明它(最终)可以找到那些更加优化的行动,并将搜索的工作聚焦在这些部分。
4、强化学习整体流程

5、策略模型与价值模型构建
网络结构使用ResNet卷积网络+残差模块,一个输入,两个输出(走子概率策略、盘面胜率评估)。
AlphaGo网络结构示例:

国际象棋的policy-value网络模型定义(keras):
def create_policy_value_net(self):
"""创建policy-value网络"""
# 输入层
#in_x = network = Input((4, self.board_width, self.board_height))
in_x = network = Input((4, 1, self.policy_infer_size))
# conv layers
network = Conv2D(filters=32, kernel_size=(3, 3), padding="same", data_format="channels_first", activation="relu", kernel_regularizer=l2(self.l2_const))(network)
network = Conv2D(filters=64, kernel_size=(3, 3), padding="same", data_format="channels_first", activation="relu", kernel_regularizer=l2(self.l2_const))(network)
network = Conv2D(filters=128, kernel_size=(3, 3), padding="same", data_format="channels_first", activation="relu", kernel_regularizer=l2(self.l2_const))(network)
# 走子策略 action policy layers
policy_net = Conv2D(filters=4, kernel_size=(1, 1), data_format="channels_first", activation="relu", kernel_regularizer=l2(self.l2_const))(network)
policy_net = Flatten()(policy_net)
# infer self.board_width * self.board_height action_probs
#self.policy_net = Dense(self.board_width * self.board_height, activation="softmax", kernel_regularizer=l2(self.l2_const))(policy_net)
self.policy_net = Dense(self.policy_infer_size, activation="softmax", kernel_regularizer=l2(self.l2_const))(policy_net)
# 盘面价值 state value layers
value_net = Conv2D(filters=2, kernel_size=(1, 1), data_format="channels_first", activation="relu", kernel_regularizer=l2(self.l2_const))(network)
value_net = Flatten()(value_net)
value_net = Dense(64, kernel_regularizer=l2(self.l2_const))(value_net)
# infer one current state score
self.value_net = Dense(1, activation="tanh", kernel_regularizer=l2(self.l2_const))(value_net)
# 创建网络模型
self.model = Model(in_x, [self.policy_net, self.value_net])
# 返回走子策略和价值概率
def policy_value(state_input):
state_input_union = np.array(state_input)
#print(state_input_union)
results = self.model.predict_on_batch(state_input_union)
return results
self.policy_value = policy_value二、实现
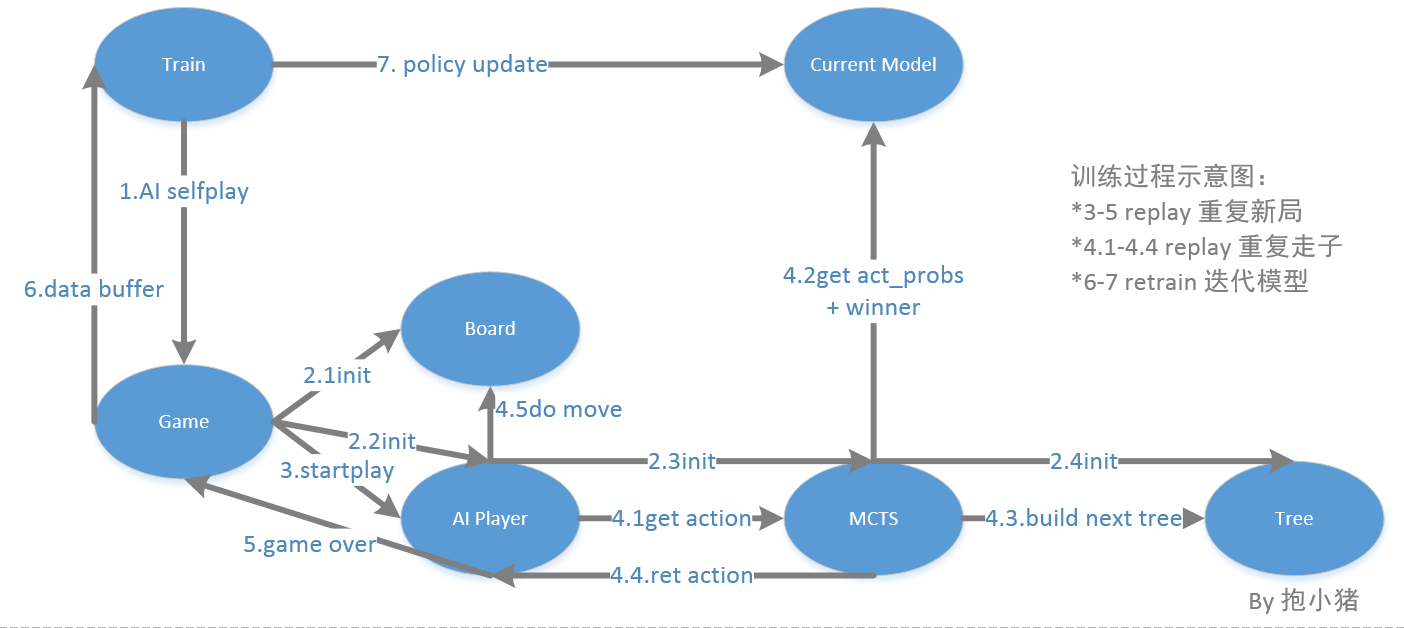
训练过程示意图:
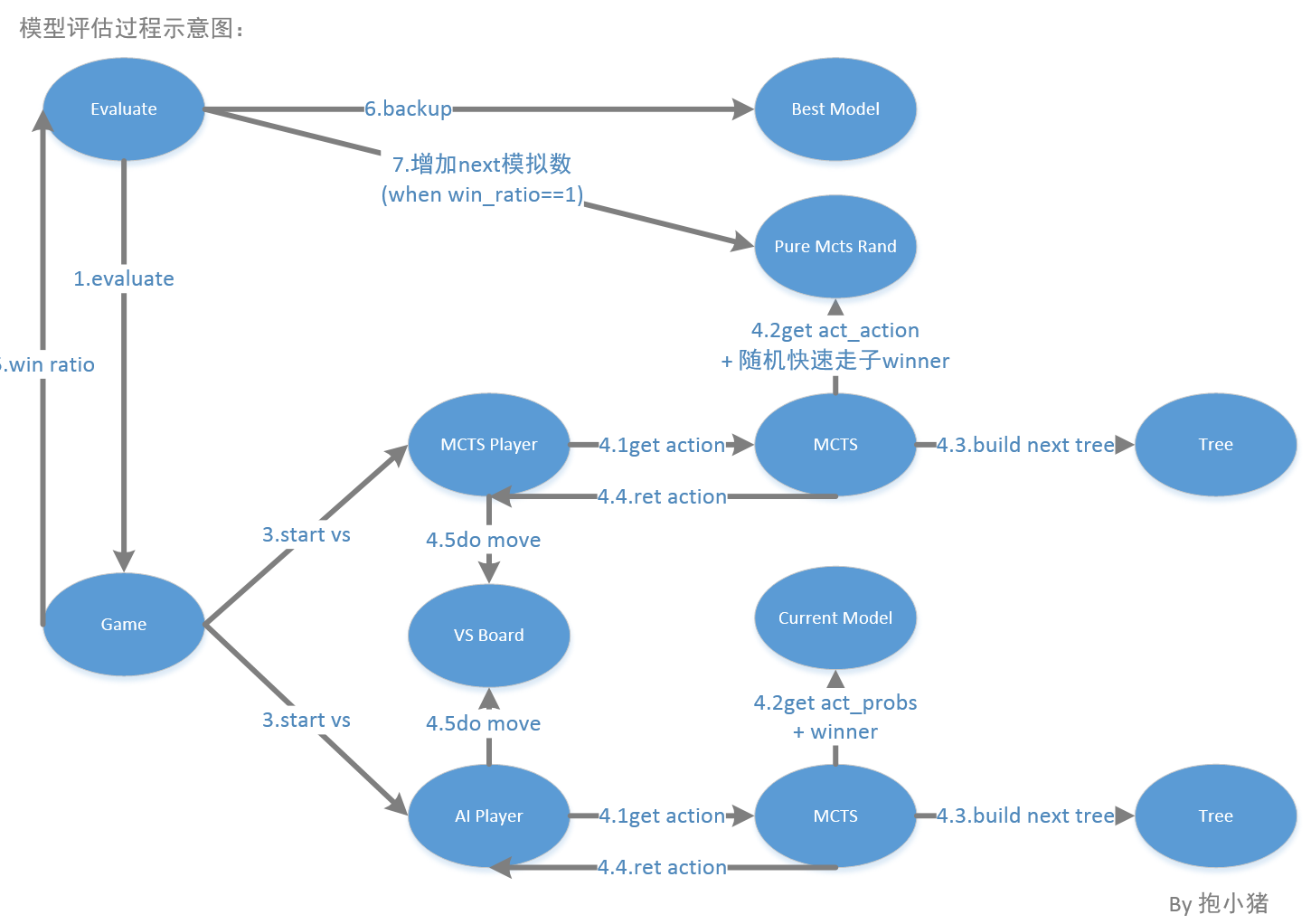
模型评估过程示意图:
环境:
# install python3.6.5
wget https://repo.anaconda.com/archive/Anaconda3-5.2.0-Linux-x86_64.sh --no-check-certificate
sh Anaconda3-5.2.0-Linux-x86_64.sh
# path
vim ~/.bashrc
# python3 pip3
export PATH=/home/yanjingang/python3.6.5/bin:$PATH
# cuda8.0 cudnn5.1
export CUDA_HOME=/home/yanjingang/cuda-8.0
export CUDNN_HOME=/home/yanjingang/cudnn_v5.1/cuda/
export CUDNN_ROOT=/home/yanjingang/cudnn_v5.1/cuda/
export PATH=${CUDA_HOME}/bin:${PATH}
export CPATH=${CUDNN_HOME}/include:${CUDA_HOME}/include
export LIBRARY_PATH=${CUDA_HOME}/lib64:${CUDNN_HOME}/lib64:${LIBRARY_PATH}
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64:${CUDNN_HOME}/lib64:${LD_LIBRARY_PATH}
#gpu
export CUDA_VISIBLE_DEVICES=0 #指定使用第一张gpu卡(不设置默认用所有的卡) nvidia-smi -l
# lang utf8
LC_ALL=en_US.UTF-8;export LC_ALL;date
source ~/.bashrc
which python
which pip
# lib
pip install --upgrade pip
pip install numpy opencv-python pillow python-chess pyquery xpinyin visualdl keras==2.0 tensorflow-gpu==1.2 paddlepaddle --default-timeout=1000
*注:本机gpu卡使用cuda_v8.0+cudnn_v5.1,因此只能安装tensorflow-gpu1.2,配套keras2.0(对应表:https://tensorflow.google.cn/install/source)代码:
五子棋AI:https://github.com/yanjingang/piggomoku
国际象棋AI:https://github.com/yanjingang/pigchess
三、实际对战
五子棋:
模型情况:mini-batch=512,8*8的棋盘,2核cpu训练了2周左右,跟人类对战可以保持不败。
做个微信小程序方便测试ai的能力。找了几个比较会下的人和这个AI对弈,基本最终都会和棋,因为棋盘不够大,而大棋盘需要的算力太大不值当去跑,毕竟五子棋只是为了研究和练手,下边的国际象棋才是正菜。。。

国际象棋:
训练情况:国际象棋因为每步的可走子范围比较大,训练较慢,跑了1周后还很弱智,为了加快速度,在databuffer里加入了top80国际大师的10w+对局数据用于加速初始模型训练。
mini-batch=512,训练1w轮后就会像跟人类在下棋了,在个人消费级gpu上训练5-6个月左右基本可以达到大师水平。

想体验与AI对战吗?扫下边的二维码“小猪国象AI”即可。

yan 2019.1.31 7:35
参考资料
Mastering the game of Go with deep neural networks and tree search
用深度神经网络和树搜索征服围棋
原文:原文 译文:译文
Mastering-Chess-and-Shogi-by-Self-Play-with-a-General-Reinforcement-Learning-Algorithm
用通用强化学习自我对弈,掌握国际象棋和将棋
原文:原文 译文:译文 译文
强化学习介绍
https://blog.csdn.net/u9oo9xkm169leldr84/article/details/78871371
https://mp.weixin.qq.com/s/pKsWoSk5qJoj1ZgqUblHWg
http://baijiahao.baidu.com/s?id=1597978859962737001
MCTS原理
https://zhuanlan.zhihu.com/p/25345778
https://blog.csdn.net/amds123/article/details/71038316
国际象棋棋谱规范
http://www.xqbase.com/protocol/pgnfen1.htm
http://www.xqbase.com/protocol/pgnfen2.htm
用Python和Keras搭建你自己的AlphaZero
https://jizhi.im/blog/post/pytoalphazero?from=singlemessage&isappinstalled=0
如何动手打造属于自己的AlphaGo Zero?
https://www.leiphone.com/news/201711/D3vCc0jiQ9ytZAbv.html?viewType=weixin&from=singlemessage&isappinstalled=0

您好,我是正在学习机器学习的学生,正在参考您的文章学习AI,想问一下如果要重新训练一个新的15*15的模型除了把几个代码文件里的size改成15以外,还要修改其他地方吗。model文件夹里需不需要自己创建一个名为current_policy_15x15.model的文件,还是在训练过程中会自动创建(在代码中好像没找到自动创建)。
如果是五子棋,可以直接把8×8改成15×15,不过估计要跑很久,中间别中断,最好用GPU来跑。模型文件在训练时会自动创建