上次我们进行了简单的环境安装和模型应用尝试,今天开始通过paddlepaddle的房价预测看一下简单的线性回归有监督模型是怎么训练出来的。
简单点说就是根据一份有标注的数据集,包含了某地区房屋的相关信息(feature)及该类房屋的标注平均价格(label),用来训练一个可以根据feature预测label的模型。具体数据字段一共14个,包含13个feature和1个label,含义如下:
| 属性名 | 解释 | 类型 |
|---|---|---|
| CRIM | 该镇的人均犯罪率 | 连续值 |
| ZN | 占地面积超过25,000平方呎的住宅用地比例 | 连续值 |
| INDUS | 非零售商业用地比例 | 连续值 |
| CHAS | 是否邻近 Charles River | 离散值,1=邻近;0=不邻近 |
| NOX | 一氧化氮浓度 | 连续值 |
| RM | 每栋房屋的平均客房数 | 连续值 |
| AGE | 1940年之前建成的自用单位比例 | 连续值 |
| DIS | 到波士顿5个就业中心的加权距离 | 连续值 |
| RAD | 到径向公路的可达性指数 | 连续值 |
| TAX | 全值财产税率 | 连续值 |
| PTRATIO | 学生与教师的比例 | 连续值 |
| B | 1000(BK – 0.63)^2,其中BK为黑人占比 | 连续值 |
| LSTAT | 低收入人群占比 | 连续值 |
| MEDV | 同类房屋价格的中位数 | 连续值 |
数据示例:
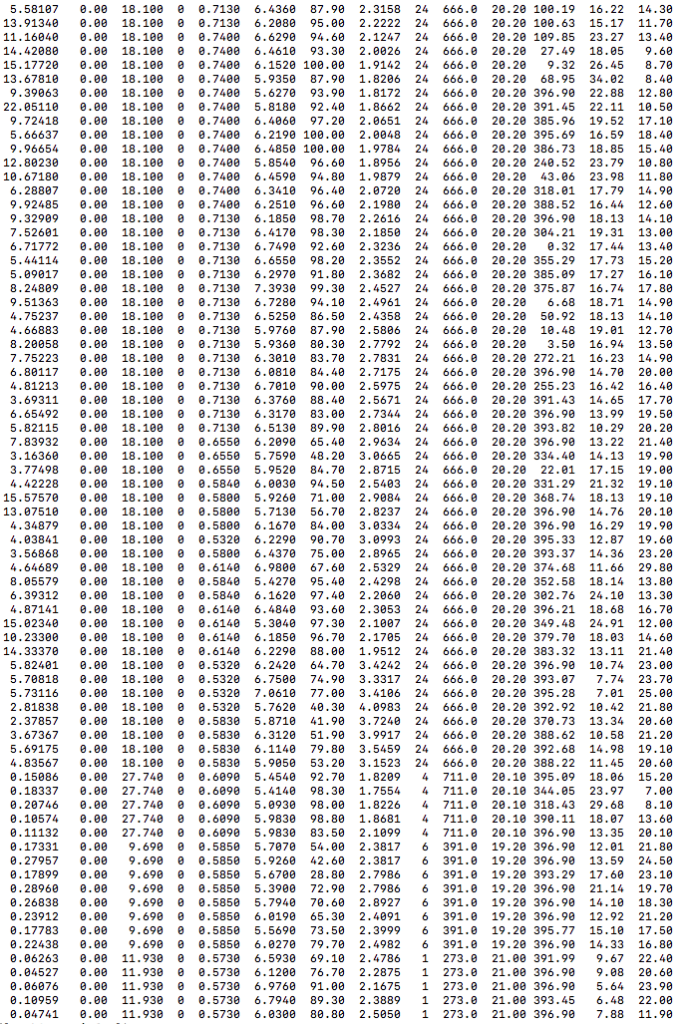
整个训练过程大概分为读取数据集、定义网络结构/cost损失函数/训练参数/训练优化器、进行多轮模型迭代训练、选择训练误差最小的模型、应用模型。具体就不再赘述了,可以先阅读一下paddlepaddle的文档:http://www.paddlepaddle.org/docs/develop/book/01.fit_a_line/index.cn.html
下边是训练过程的代码和自己的理解注释,有错误欢迎指正:
vim housing_train.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import paddle.v2 as paddle
import paddle.v2.dataset.uci_housing as uci_housing
with_gpu = os.getenv('WITH_GPU', '0') != '0'
def main():
# 0.init paddle初始化定义跑模型的设备
paddle.init(use_gpu=with_gpu, trainer_count=1)
# 1.读取data数据
x = paddle.layer.data(name='x', type=paddle.data_type.dense_vector(13)) #13列feature数据层, dense_vector:稠密的浮点数向量
y = paddle.layer.data(name='y', type=paddle.data_type.dense_vector(1)) #1列label数据层, dense_vector:稠密的浮点数向量
# 2.network config 定义网络结构(创建一个全连接层,激活函数为线性函数)
y_predict = paddle.layer.fc(input=x, size=1, act=paddle.activation.Linear())
# 3.定义cost损失函数,此处使用square平方差cost函数
cost = paddle.layer.square_error_cost(input=y_predict, label=y)
# 4.保存网络拓扑到protobuf
inference_topology = paddle.topology.Topology(layers=y_predict)
with open("inference_topology.pkl", 'wb') as f:
inference_topology.serialize_for_inference(f)
# 5.create parameters指定训练相关的参数
parameters = paddle.parameters.create(cost)
# 6.create optimizer定义训练方法(Momentum:梯度下降方向与上次一致时加大下降幅度,以加快收敛速度)
optimizer = paddle.optimizer.Momentum(momentum=0)
# 7.指定trainer训练优化器(SGD:随机梯度下降stochastic gradient descent)
trainer = paddle.trainer.SGD(
cost=cost, parameters=parameters, update_equation=optimizer)
feeding = {'x': 0, 'y': 1}
# 8.定义event_handler,输出训练过程中的结果
lists = []
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print "Pass %d, Batch %d, Cost %f" % (
event.pass_id, event.batch_id, event.cost)
if isinstance(event, paddle.event.EndPass):
#保存参数
#if event.pass_id % 10 == 0:
with open('params_pass_%d.tar' % event.pass_id, 'w') as f:
trainer.save_parameter_to_tar(f)
result = trainer.test(
reader=paddle.batch(uci_housing.test(), batch_size=2),
feeding=feeding)
print "Test %d, Cost %f" % (event.pass_id, result.cost)
#print result.metrics
#保存训练结果损失情况
lists.append((event.pass_id, result.cost,
#result.metrics['classification_error_evaluator']))
result.metrics))
# 9.training开始训练模型
#创建一个reader,实质上是一个迭代器,每次返回一条数据
reader = uci_housing.train()
#创建一个shuffle_reader,把上一步的reader放进去,配置buf_size就可以读取buf_size大小的数据自动做shuffle,让数据打乱,随机化
shuffle_reader = paddle.reader.shuffle(reader, buf_size=500)
#创建一个batch_reader,把shuffle后的数据,一个batch一个batch的形式,批量的放到训练器里去进行每一步的迭代和训练
batch_reader = paddle.batch(shuffle_reader, batch_size=2)
#开始训练
trainer.train(
#reader=paddle.batch(
# paddle.reader.shuffle(uci_housing.train(), buf_size=500),
# batch_size=2),
reader=batch_reader,
#reader=paddle.batch(reader, batch_size=2),
feeding=feeding,
event_handler=event_handler,
num_passes=30)
#找到训练误差最小的一次结果
best = sorted(lists, key=lambda list: float(list[1]))[0]
best_passid = best[0] #训练误差最小的模型passid
best_cost = best[1] #训练误差最小的损失函数返回cost
print 'Best pass is %s, testing Avgcost is %s' % (best_passid, best_cost)
#print str(best[2])
#print 'The classification accuracy is %.2f%%' % (100 - float(best[2]) * 100)
#清理非best模型参数文件
for tmp in lists:
if tmp[0] != best_passid:
os.remove('params_pass_%s.tar' % tmp[0])
# 10.inference使用模型进行预测
#加载测试数据
test_data_creator = paddle.dataset.uci_housing.test()
test_data = []
test_label = []
for item in test_data_creator():
test_data.append((item[0], ))
test_label.append(item[1])
#print item[1]
#if len(test_data) == 5:
# break
# load parameters from tar file.
# users can remove the comments and change the model name
# 使用训练误差最小那次的模型
#print parameters.__dict__
with open('params_pass_%s.tar' % best_passid, 'r') as f:
print 'Use best pass params: %s' % best_passid
parameters = paddle.parameters.Parameters.from_tar(f)
#print parameters.__dict__
#运行预测
probs = paddle.infer(
output_layer=y_predict, parameters=parameters, input=test_data)
#模型预测结果打印
for i in xrange(len(probs)):
#print "label=" + str(test_label[i][0]) + ", predicted price=${:,.2f}" . format(probs[i][0] * 1000)
print "label=" + str(test_label[i][0]) + ", predicted price=$%s" % probs[i][0]
if __name__ == '__main__':
main()运行后的打印信息说明:
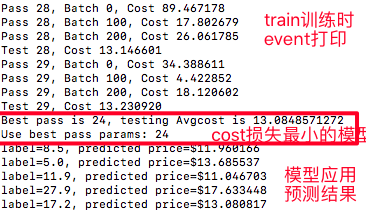
模型预测结果与原标注label对比:(左侧是原始feature+label,右侧是用训练出的模型预测的原label+预测label对比)
运行程序后保存的迭代模型参数文件(保留最优的那个就行):
yan 2018.4.11 22:50
参考:
http://www.paddlepaddle.org/docs/develop/book/01.fit_a_line/index.cn.html
http://bit.baidu.com/course/detail/id/137/column/117.html
http://www.cnblogs.com/charlotte77/p/7802226.html
http://www.cnblogs.com/charlotte77/p/7712856.html
