
我们都知道磁盘是有寿命的,超期服役后,服务器或物联网设备的磁盘会陆续报故障损坏,意外的损坏也带来诸多问题。本文主要讲解下nvme SSD的磁盘寿命消耗情况。
我们都知道磁盘是有寿命的,超期服役后,服务器或物联网设备的磁盘会陆续报故障损坏,意外的损坏也带来诸多问题。本文主要讲解下nvme SSD的磁盘寿命消耗情况。

本文主要记录华硕的GPU本(RTX2070)如何Ubuntu20.04 + Nvidia显卡驱动 + CUDA11.8 + cuDNN8.7,并验证GPU CUDA生效的过程。
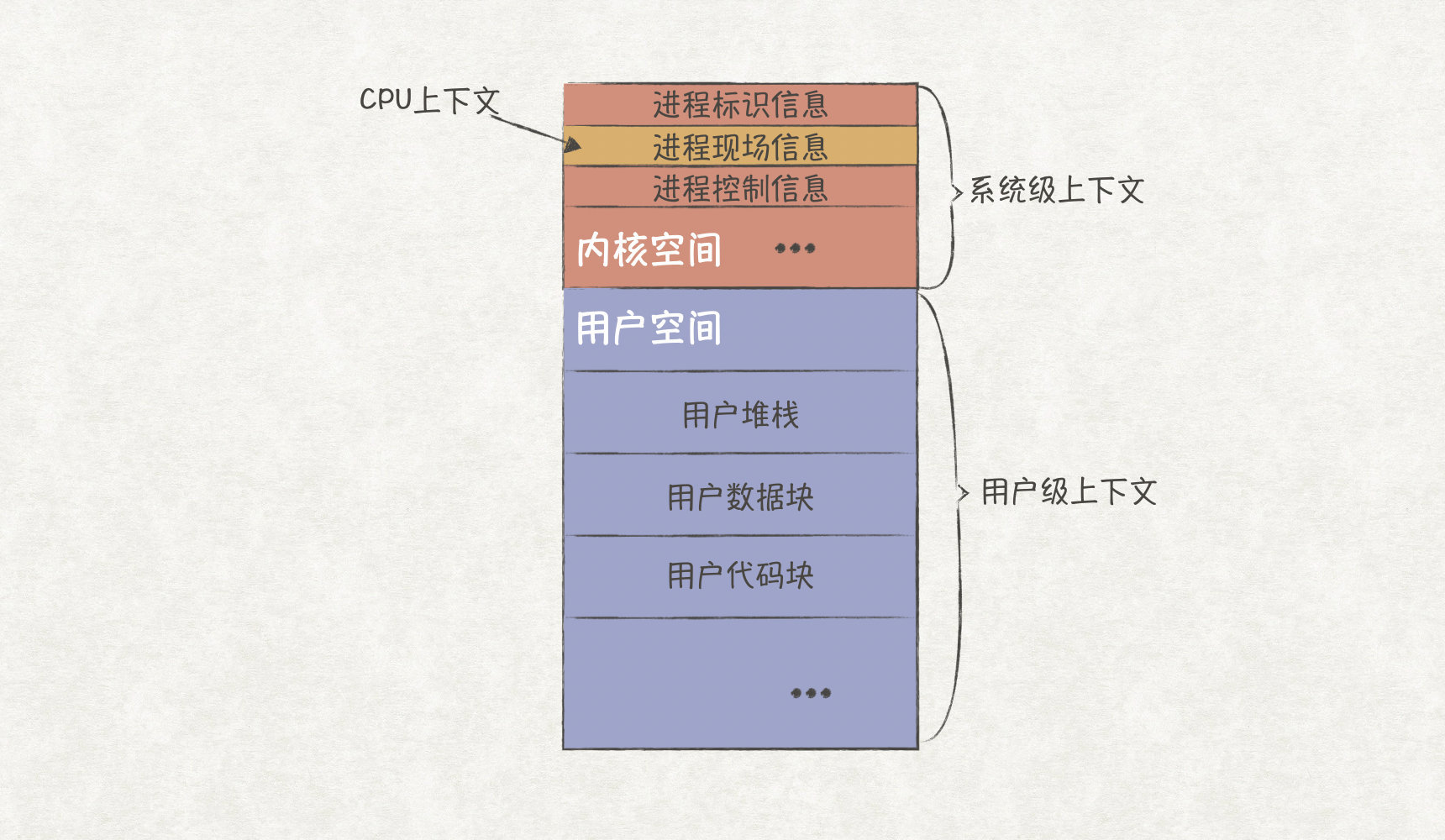
软件工程师们总习惯把OS(Operating System,操作系统)当成是一个非常值得信赖的管家,我们只管把程序托管到OS上运行,却很少深入了解操作系统的运行原理。确实,OS作为一个通用的软件系统,在大多数的场景下都表现得足够的优秀。但仍会有一些特殊的场景,需要我们对OS进行各项调优,才能让业务系统更高效地完成任务。这就要求我们必须深入了解OS的原理,不仅仅只会使唤这个管家,还能懂得如何让管家做得更好。本文主要探索其中的冰山一角:CPU的调度原理。
上一次,我们尝试了用户空间自定义函数探测,里边会用到进程ID参数,那么实际使用场景下,我们可能需要能检测到进程的拉起和退出,今天就一起来实现下这个小功能。
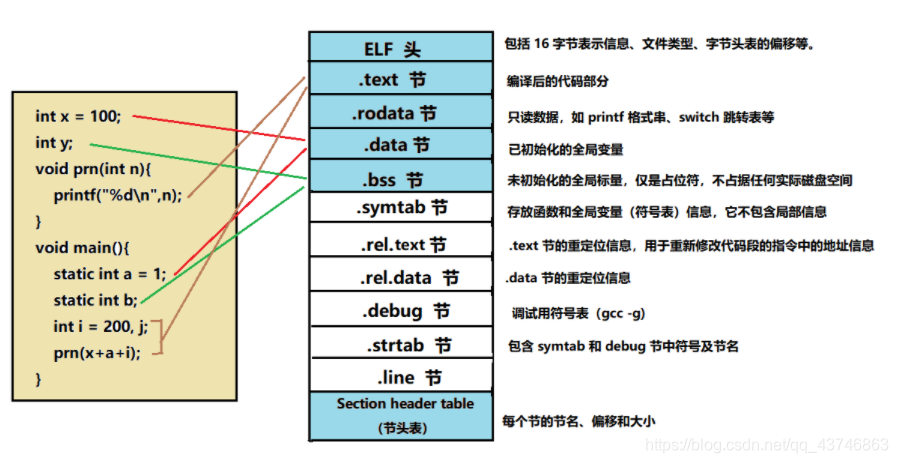
上一次,我们通过uprobe实现一个对用户空间自定义程序的特定函数出入口进行代码注入和探测的方法,但它还有很多不完善的地方,比如需要提前准备好编译后的函数符号,同时生产环境产出通常也不带符号、产出的部署位置通常也不固定,给我们在实际场景中使用带来不便。本文就讲解下如何通过导出符号表、产出去符号,通过符号表的offset、类函数名、进程PID来进行用户自定义函数调用的探测,从而更方便直接在生产环境使用。
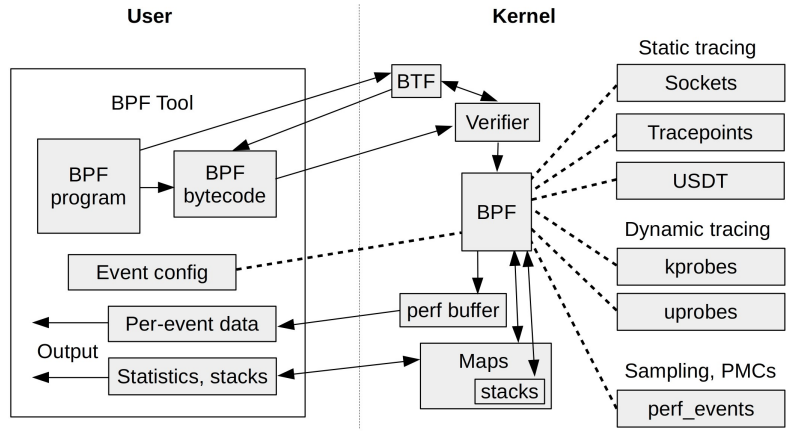
上一次,我们通过kprobe实现一个简单的内核系统调用捕获,了解了如何在内核函数的出入口动态注入自定义代码,并通过ring buffer传递到用户空间。今天,我开始带大家通过uprobe实现一个对用户空间自定义程序的特定函数出入口进行代码注入和探测的方法。
在前两篇文章中,我们了解了eBPF的基本知识。本文开始进行一次具体的实践,带大家通过kprobe实现一个简单的内核系统调用捕获,来了解如何在内核函数的出入口动态注入自定义代码。
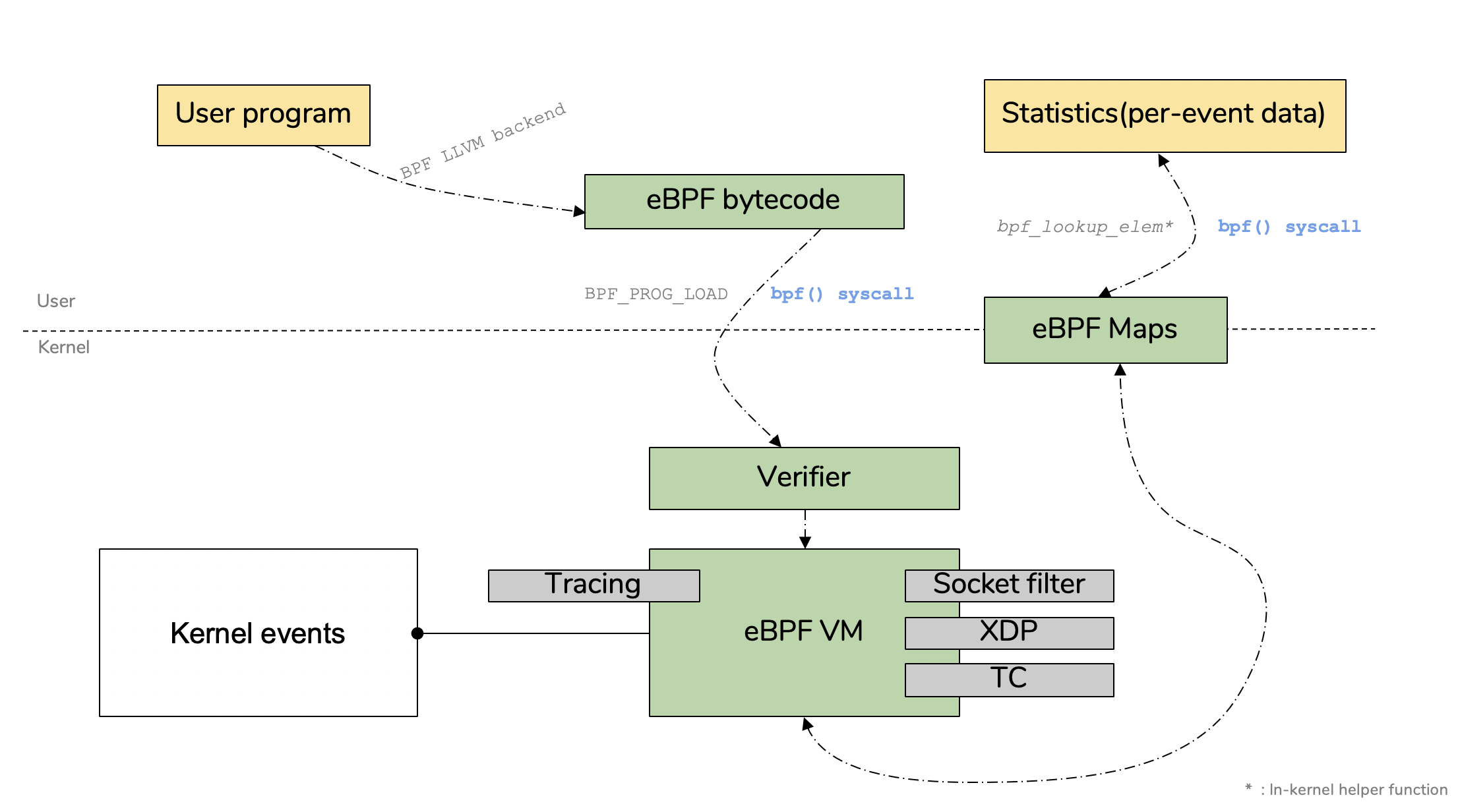
上一次,我们对eBPF有了基本的了解,并实现了一个简单的kprobe监听。本文我们从BPF Map开始,了解如何将在内核中抓取到的数据传递到用户空间。了解BPF Map是从0开始独立编写一个eBPF程序的必经之路。

eBPF(extended Berkeley Packet Filter),即扩展的伯克利包过滤器,可谓 Linux 社区的新宠,Goole、Facebook、Twitter等公司都开始投身于 eBPF 技术的研究和应用。
编译autoware simulation_interface库时,报conversions.hpp:53:10: fatal error: zmqpp/zmqpp.hpp: No such file or directory
在ubuntu22.04上编译autoware autoware_carla_interface库时,报setup.py install is deprecated命令已弃用stderr
在ubuntu22.04上编译autoware时,报TypeError: canonicalize_version() got an unexpected keyword argument ‘strip_trailing_zero’错误
Ubuntu20.04默认apt最高只能安装到python3.9,ros2的autoware对python3.10的新特性有依赖,因此需要升级到3.10+版本。
执行apt时,报Depends: xxx but it is not installed,根据提示运行sudo apt –fix-broken install也无法解决:

在进行嵌入式开发的过程中,经常会遇到通信协议是按bit位定义的情况,比如协议一共6个byte字节,每个byte一共8bit位,但是传输的很多数据用1、2个bit就足够了,这时协议会按bit定义,如何方便快捷的进行bit位的赋值和读取,即为本文讲解的内容。
我们在编写程序时经常会用到enum枚举类型,使用非常方便。但是当枚举定义较多时,在LOG打印时输出值很难直观的明白其含义,必须对照enum定义。本文介绍一个比较简单的方法,让LOG打印或std::cout输出枚举值时,直接输出文本。
有时用vscode打开比较大的工作目录,用一会儿机器会突然卡顿,鼠标都移动不了,但是查看系统资源会发现cpu全是空闲的,mem占用也不到50%,但是swap几乎处于打满状态。
之前体验过Ubuntu22.04版本后感觉新增的小工具很好用,就把几台linux设备都升级到了Ubuntu22,最近开发一个新功能,其中必须的编译依赖工具bcloud要求最高Ubuntu20下才能用,然后就悲催了,实在不想重装系统了,打算做一个ubuntu20+bcloud及依赖库的docker镜像,本文就记录下过程。
日常开发时,不论是企业或组织都会对代码格式有统一的要求,本文主要讲解如何在vscode中自动按Google C++代码规范进行代码自动格式化和检查提示。如有需要也可以在此基础上进行自定义调整。
使用cmake编译的时候提示:CMake 3.20 or higher is required. You are running version 3.16.3.