eBPF(extended Berkeley Packet Filter),即扩展的伯克利包过滤器,可谓 Linux 社区的新宠,Goole、Facebook、Twitter等公司都开始投身于 eBPF 技术的研究和应用。
eBPF究竟有什么魅力让大家都关注它呢?一般来说,要向内核添加新功能,需要修改内核源代码或者编写内核模块来实现。而eBPF允许程序在不修改内核源代码或添加额外的内核模块情况下,以更灵活和便捷的方式扩展内核功能,类似一个通用内核执行引擎。本文就先带大家一起来到eBPF的世界,尝试一下如何编写我们的第一个eBPF程序。
一、概述
1. 什么是BPF
BPF(Berkeley Packet Filter),即伯克利包过滤器,最初构想提出于 1992 年,其目的是为了提供一种过滤包的方法,并且要避免从内核空间到用户空间的无用的数据包复制行为。
BPF 是基于寄存器虚拟机实现的,支持 JIT(Just-In-Time),比基于栈实现的性能高很多。它能载入用户态代码并且在内核环境下运行,内核提供 BPF 相关的接口,用户可以将代码编译成字节码,通过 BPF 接口加载到 BPF 虚拟机中,当然用户代码跑在内核环境中是有风险的,如有处理不当,可能会导致内核崩溃。因此在用户代码跑在内核环境之前,内核会先做一层严格的检验,确保没问题才会被成功加载到内核环境中。
BPF架构:

BPF最初是专门为过滤网络数据包而创造的,可以在不升级内核的情况下,对kernel的工作情况数据进行跟踪、收集、统计分析。
2. 什么是 eBPF
eBPF(extended Berkeley Packet Filter)起源于BPF,它提供了内核的数据包过滤机制。其扩充了 BPF 的功能,丰富了指令集,改善了它的性能。与此同时,将以前的 BPF 变成 cBPF( classic BPF)。新版本出现了如映射和尾调用tail call这样的新特性,并且 JIT 编译器也被重写了。新的语言比 cBPF 更接近于原生机器语言,并且在内核中创建了新的挂钩点,eBPF程序会注册到某些挂钩点,当内核运行到挂钩点后,就执行eBPF程序。这一机制使得eBPF 程序可以被用于各种各样的情形下,而不再仅限于过滤网络数据包。
挂钩点主要包括以下几类:
- 网络事件,例如封包到达
- Kprobes / Uprobes
- 系统调用
- 函数的入口/退出点
其分为两个主要应用领域:
- 内核跟踪和事件监控:BPF 程序可以被附着到探针(kprobe),而且它与其它跟踪模式相比,有很多的优点(有时也有一些缺点)。
- 网络编程:除了套接字过滤器外,eBPF 程序还可以附加到 tc(Linux 流量控制工具)的入站或者出站接口上,以一种很高效的方式去执行各种包处理任务。这种使用方式在这个领域开创了一个新的天地。
eBPF 架构:
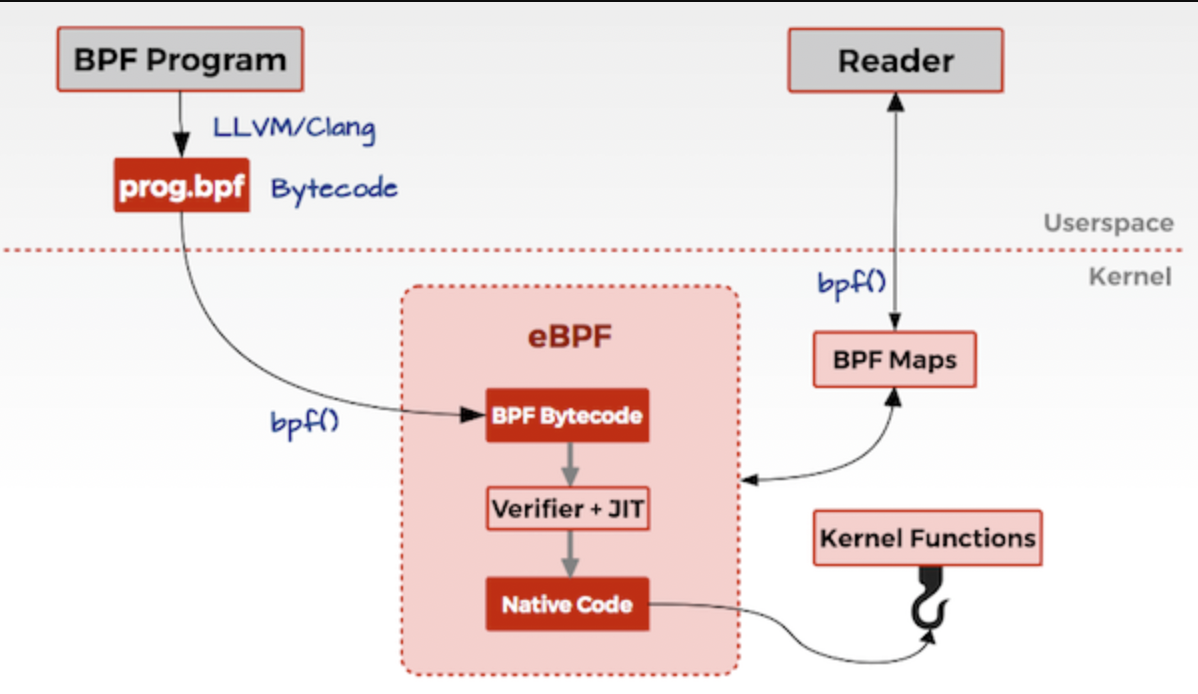
如上,一般 eBPF 的工作逻辑是:
-
BPF Program 通过 LLVM/Clang 编译成 eBPF 定义的字节码 prog.bpf。 -
通过系统调用 bpf() 将 bpf 字节码指令传入内核中。 -
经过 verifier 检验字节码的安全性、合规性。 -
在确认字节码安全后将其加载对应的内核模块执行,通过 Helper/hook 机制,eBPF 与内核可以交换数据/逻辑。BPF 观测技术相关的程序程序类型可能是 kprobes/uprobes/tracepoint/perf_events 中的一个或多个,其中: -
kprobes:实现内核中动态跟踪。kprobes 可以跟踪到 Linux 内核中的函数入口或返回点,但是不是稳定 ABI 接口,可能会因为内核版本变化导致,导致跟踪失效。理论上可以跟踪到所有导出的符号 /proc/kallsyms。 -
uprobes:用户级别的动态跟踪。与 kprobes 类似,只是跟踪的函数为用户程序中的函数。 -
tracepoints:内核中静态跟踪。tracepoints 是内核开发人员维护的跟踪点,能够提供稳定的 ABI 接口,但是由于是研发人员维护,数量和场景可能受限。 -
perf_events:定时采样和 PMC。
-
-
用户空间通过 BPF map 与内核通信。 - BPF Maps以键值对形式的存储,通过文件描述符来定位,值是不透明的Blob(任意数据)。用于跨越多次调用共享数据,或者与用户空间应用程序共享数据。
- 一个eBPF程序可以直接访问最多64个Map,多个eBPF程序可以共享同一Map。
eBPF 分用户空间和内核空间,用户空间和内核空间的交互有 2 种方式:
-
BPF map:统计摘要数据 -
perf-event:用户空间获取实时监测数据
简单总结下,就是eBPF可以在不升级linux内核的情况下,将用户自定义代码插入到内核执行过程中,从而对某些特定的内核或用户程序函数符号/偏移量等的触发过程进行监控、采集等自定义操作,并支持将输出数据暂存在bpf maps中,由reader读取后进行后续的落盘、数据分析等。
二、eBPF的具体能力
1. eBPF 主要能力
- kprobe:内核插探,在指定的内核函数前或后执行。
- kretprobe:内核函数返回插探,在指定的内核函数返回时执行。
- tracepoint:跟踪点,在指定的内核跟踪点处执行。
- tracepoint_return:跟踪点返回,在指定的内核跟踪点返回时执行。
- raw_tracepoint:原始跟踪点,在指定的内核原始跟踪点处执行。
- raw_tracepoint_return:原始跟踪点返回,在指定的内核原始跟踪
- xdp:网络数据处理,拦截和处理网络数据包。
- perf_event:性能事件,用于处理内核性能事件。
2. eBPF与直接编写内核模块的对比
| 维度 | Linux 内核模块 | eBPF |
|---|---|---|
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
三、eBPF的使用
eBPF 提供多种使用方式:BCC、BPFTrace、libbpf C/C++ Library、eBPF GO library 等。
更早期的工具使用 eBPF 受限的 C 语言来编写 BPF 程序,使用 LLVM clang 编译成 BPF 代码,这对于普通使用者上手有不少门槛。对于大多数开发者而言,更多的是基于 BPF 技术之上编写解决我们日常遇到的各种问题。
BCC 作为 BPF 的前端,在观测和性能分析上已经有了诸多灵活且功能强大的工具箱,完全可以满足我们日常使用。而libbpf C/C++ library则主要负责充当 BPF 程序加载器,它加载、检查和重新定位 BPF 程序,整理映射和钩子。libbpf允许创建在不同内核版本上运行的二进制文件,通过内置的vmheader兼容多种内核类型,编译一次到处运行,而不是像BCC那样嵌入LLVM/Clang编译器组件并在运行时编译程序(这需要额外的 CPU 和内存)。同时它在资源使用方面更好,输出更小的二进制文件,并且使用更少的内存,这使得它非常适合系统关键任务。它对性能的影响有限,因此也非常适合监控、安全和分析。
他们的对比情况如下:
BCC(BPF Compiler Collection):
- 提供了更高阶的抽象,可以让用户采用 Python、C++ 和 Lua 等高级语言快速开发 BPF 程序
- 提供了许多有用的资源和示例来构建有效的内核跟踪和操作程序
- 当工具启动时,需要占用大量CPU和内存资源来编译BPF程序,如果它在资源受限的服务器上运行,可能会引发问题。
- 由于 BPF 程序是在运行时编译的,因此许多简单的编译错误只能在运行时检测到。
libbpf + BPF CO-RE(Compile Once – Run Everywhere):
- 在资源使用方面更好,输出更小的二进制文件,并且使用更少的内存(BPF CO-RE内存开销约为bcc-python的1/10),非常适合系统关键任务
- 它对性能的影响有限,因此也非常适合监控、安全和分析,并能够支持更多的硬件环境
- 从BCC迁移到Libbpf并不复杂
1. bcc-tools
为了快速学习,我们先使用 BCC 工具来编写我们的第一个eBPF程序,它内置非常丰富的工具库,可以帮我们简化了很多繁琐的工作。
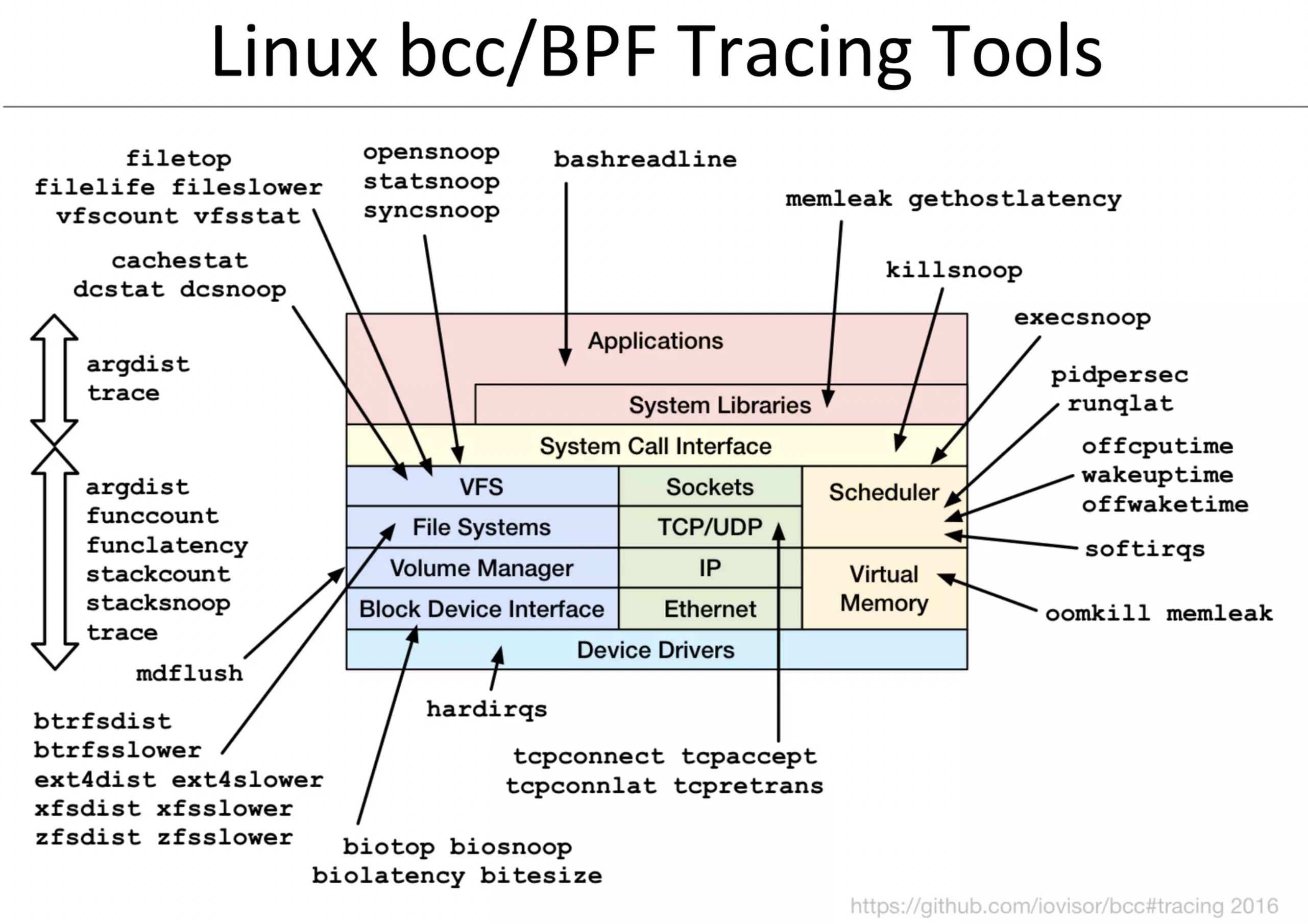
下面我们将使用 BCC 工具来介绍怎么编写一个 eBPF 程序。
注意:由于 eBPF 对内核的版本有较高的要求,不同版本的内核对 eBPF 的支持可能有所不相同。所以使用 eBPF 时,最好使用最新版本的内核。本文使用 Ubuntu 20.04.6(内核版本为5.15.0)。
1.1 安装bcc-tools
经过测试Ubuntu20.04使用apt安装的bpfcc-tools无法正常工作,我们这里采用源码安装:
# 安装依赖 For Focal (20.04.1 LTS)
sudo apt install -y zip bison build-essential cmake flex git libedit-dev libllvm12 llvm-12-dev libclang-12-dev python zlib1g-dev libelf-dev libfl-dev python3-setuptools liblzma-dev arping netperf iperf
# clang13
vim /etc/apt/sources.list
deb http://archive.ubuntu.com/ubuntu/ focal-proposed universe
sudo apt-get update
sudo apt-get install clang clang-13 libclang-13-dev
cd /usr/bin
sudo ln -sf ../lib/llvm-13/bin/clang clang
sudo ln -sf ../lib/llvm-13/bin/clang++ clang++
sudo ln -sf ../lib/llvm-13/bin/clang-format clang-format
sudo ln -sf llvm-strip-13 llvm-strip
export LLVM_ROOT=/usr/lib/llvm-13
# 编译bcc
git clone https://github.com/iovisor/bcc.git
mkdir bcc/build; cd bcc/build
cmake ..
make
sudo make install
cmake -DPYTHON_CMD=python3 .. # build python3 binding
pushd src/python/
make
sudo make install
popd1.2 编写第一个eBPF程序
使用 BCC 编写 eBPF 程序的步骤如下:
-
使用 C 语言编写 运行在内核态的 eBPF 程序。 -
使用 Python 编写加载代码和用户态功能。
因为 LLVM/Clang 只支持将 C 语言编译成 eBPF 字节码,而不支持将 Python 代码编译成 eBPF 字节码。所以,eBPF 内核态程序只能使用 C 语言编写。而 eBPF 的用户态程序可以使用 Python 进行编写,这样就能简化编写难度。
所以,第一步就是编写 eBPF 内核态程序。
a. 使用 C 编写 eBPF 程序
vim hello.c
int hello_ebpf(void *ctx)
{
bpf_trace_printk("Hello, eBPF!"); // 将信息输出到trace_pipe(/sys/kernel/debug/tracing/trace_pipe)
return 0;
}
b. 使用 Python 和 BCC 工具开发一个用户态程序
vim hello.py
#!/usr/bin/env python3
# 导入了 BCC 库的 BPF 模块,以便接下来调用
from bcc import BPF
# 调用 BPF() 函数加载 eBPF 内核态程序(也就是我们编写的hello.c)
b = BPF(src_file="hello.c")
# 将 eBPF 程序挂载到内核探针(简称 kprobe),其中 do_sys_openat2() 是系统调用 openat() 在内核中的实现
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_ebpf")
# 读取内核调试文件/sys/kernel/debug/tracing/trace_pipe的内容(bpf_trace_printk()函数会将信息写入到此文件),并打印到标准输出中
b.trace_print()
c. 运行 eBPF 程序
用户态程序开发完成之后,最后一步就是执行它了。需要注意的是,eBPF 程序需要以 root 用户来运行:
$ sudo python3 hello.py
b' <...>-40799 [003] d...1 120070.935621: bpf_trace_printk: Hello, eBPF!'
b' <...>-26273 [004] d...1 120071.218366: bpf_trace_printk: Hello, eBPF!'
b' <...>-386 [005] d...1 120072.792249: bpf_trace_printk: Hello, eBPF!'
b' <...>-386 [005] d...1 120072.792364: bpf_trace_printk: Hello, eBPF!'
b' <...>-386 [005] d...1 120072.792416: bpf_trace_printk: Hello, eBPF!'
...
到了这里,我们已经成功开发并运行了第一个 eBPF 程序。这个程序很简单,也没什么实际的用途。但通过这个程序,我们大概可以知道使用 BCC 开发一个 eBPF 程序的步骤。
2. libbpf-tools
我们在使用bcc测试的过程中可以看到,BPF程序hello.c是在hello.py启动时现编译的,这对生产环境来说并不友好,所以这里我们尝试下使用libbpf对比下。
基于 libbpf C/C++ library 的开发架构:
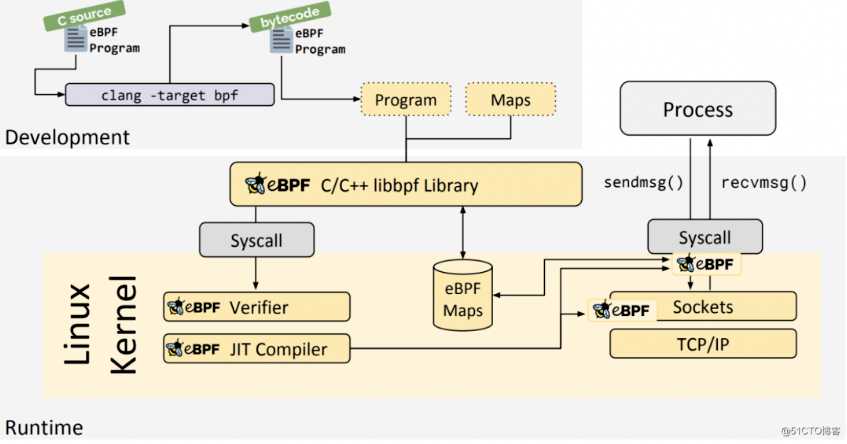
2.1 安装libbpf-tools
libbpf+ BPF CO-RE不需要将 Clang/LLVM 运行时部署到目标服务器,不过它依赖使用BTF类型信息构建的内核。我们这里采用源码安装:
# 安装依赖
sudo apt install -y make gcc libssl-dev bc gcc-multilib libncurses5-dev strace tar build-essential pkg-config libmnl-dev bison flex graphviz
sudo apt install -y clang llvm libelf-dev libcap-dev libbfd-dev bpfcc-tools cargo linux-headers-$(uname -r)
# 检查内核是否支持btf(文件存在即表示支持)
ls -la /sys/kernel/btf/vmlinux
# 编译bpftool+libbpf
cd ~/project
# git clone --recurse-submodules https://github.com/libbpf/bpftool.git
git clone https://github.com/yanjingang/libbpf-demo
cd ~/project/libbpf-demo
git submodule update --init --recursive
cd bpftool/src/
make -j8
sudo make install
# libbpf+bpftool脚手架示例
cd ~/project/libbpf-demo/examples/c
mkdir -p build && cd build
cmake ..
make -j8
sudo ./bootstrap
TIME EVENT COMM PID PPID FILENAME/EXIT CODE
18:45:05 EXIT vim 68519 27493 [0]
18:45:05 EXEC tracker-store 70267 25245 /usr/libexec/tracker-store
18:45:08 EXEC ls 70273 27493 /usr/bin/ls
18:45:08 EXIT ls 70273 27493 [0] (3ms)2.2 使用libbpf + bpftool编写eBPF程序
编写eBPF程序:
vim hello.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "Dual BSD/GPL";
// 使用SEC宏把下方函数插入到openant系统调用入口执行
SEC("kprobe/do_sys_openat2")
int BPF_KPROBE(do_sys_openat2, int dfd, struct filename *name)
{
pid_t pid;
pid = bpf_get_current_pid_tgid() >> 32;
// 将信息输出到trace_pipe(/sys/kernel/debug/tracing/trace_pipe) bpf_printk("Hello eBPF! kprobe entry pid = %d\n", pid); return 0; } 编写eBPF loader程序:
vim hello.c
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
#include <string.h>
#include <errno.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "hello.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
static volatile sig_atomic_t stop;
void sig_int(int signo)
{
stop = 1;
}
int main(int argc, char **argv)
{
struct hello_bpf *skel;
int err;
/* 设置 libbpf 错误和调试信息回调 */
libbpf_set_print(libbpf_print_fn);
/* 加载并验证 hello.bpf.c 应用程序 */
skel = hello_bpf__open_and_load();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
/* 附加 hello.bpf.c 程序到跟踪点 */
err = hello_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
if (signal(SIGINT, sig_int) == SIG_ERR) {
fprintf(stderr, "can't set signal handler: %s\n", strerror(errno));
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
while (!stop) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
hello_bpf__destroy(skel);
return -err;
}
编译运行:
# 编译
cmake ..
make -j8
# 测试
sudo ./hello
# 查看输出
sudo cat /sys/kernel/debug/tracing/trace_pipe
gsd-housekeepin-25624 [000] d...1 204926.010969: bpf_trace_printk: Hello eBPF! kprobe entry pid = 25624
ThreadPoolForeg-26248 [011] d...1 204907.802283: bpf_trace_printk: Hello eBPF! kprobe entry pid = 26222
thermald-1099 [000] d...1 204907.821950: bpf_trace_printk: Hello eBPF! kprobe entry pid = 877
一个简单的基于kprobe openat监听就实现了。
今天先到这里,下一篇我将带大家一起更深入的了解下附着点的分类,并实现一个具体的内核或用户层函数数据抓取功能。
四、其他
1. 常见问题
1.1 bcc: sudo python3 hello.py 报 AttributeError: /lib/x86_64-linux-gnu/libbcc.so.0: undefined symbol: bpf_module_create_b
排查方法:
# 查看找不到符号的so文件
$ ls -lh /lib/x86_64-linux-gnu/ |grep libbcc.so
lrwxrwxrwx 1 root root 11 Nov 2 21:17 libbcc.so -> libbcc.so.0
lrwxrwxrwx 1 root root 16 Nov 2 21:17 libbcc.so.0 -> libbcc.so.0.28.0
-rw-r--r-- 1 root root 58M Feb 7 2020 libbcc.so.0.12.0
-rw-r--r-- 1 root root 102M Nov 2 21:12 libbcc.so.0.28.0
# 检查符号
$ strings /lib/x86_64-linux-gnu/libbcc.so.0.28.0 |grep bpf_module_create_
bpf_module_create_c
bpf_module_create_c_from_string
bpf_module_create_c.cold
bpf_module_create_c_from_string.cold
bpf_module_create_c
bpf_module_create_c_from_string
# 旧版so里有这个符号(python3 bcc库依赖的so怎么是旧版本?)
$ strings /lib/x86_64-linux-gnu/libbcc.so.0.12.0 |grep bpf_module_create_
bpf_module_create_b
bpf_module_create_c
bpf_module_create_c_from_string
# 确认下python3 bcc库竟然都是20年的(说明python3的bcc库没有被正常安装和更新)
$ ll /usr/lib/python3/dist-packages/bcc/
total 188
-rw-r--r-- 1 root root 11728 Feb 7 2020 libbcc.py
...解决方法:
# 手动把bcc build产出里的python3库拷贝到python3 dist-packages目录中后解决
sudo cp -r /home/work/project/bcc/build/src/python/bcc-python3/bcc/* /usr/lib/python3/dist-packages/bcc/
yan 23.11.3
参考:
Meet cute-between-ebpf-and-tracing
BCC – Tools for BPF-based Linux IO analysis, networking, monitoring, and more
Why We Switched from bcc-tools to libbpf-tools for Linux BPF Performance Analysis
