上一次,我们对eBPF有了基本的了解,并实现了一个简单的kprobe监听。本文我们从BPF Map开始,了解如何将在内核中抓取到的数据传递到用户空间。了解BPF Map是从0开始独立编写一个eBPF程序的必经之路。
一、概述
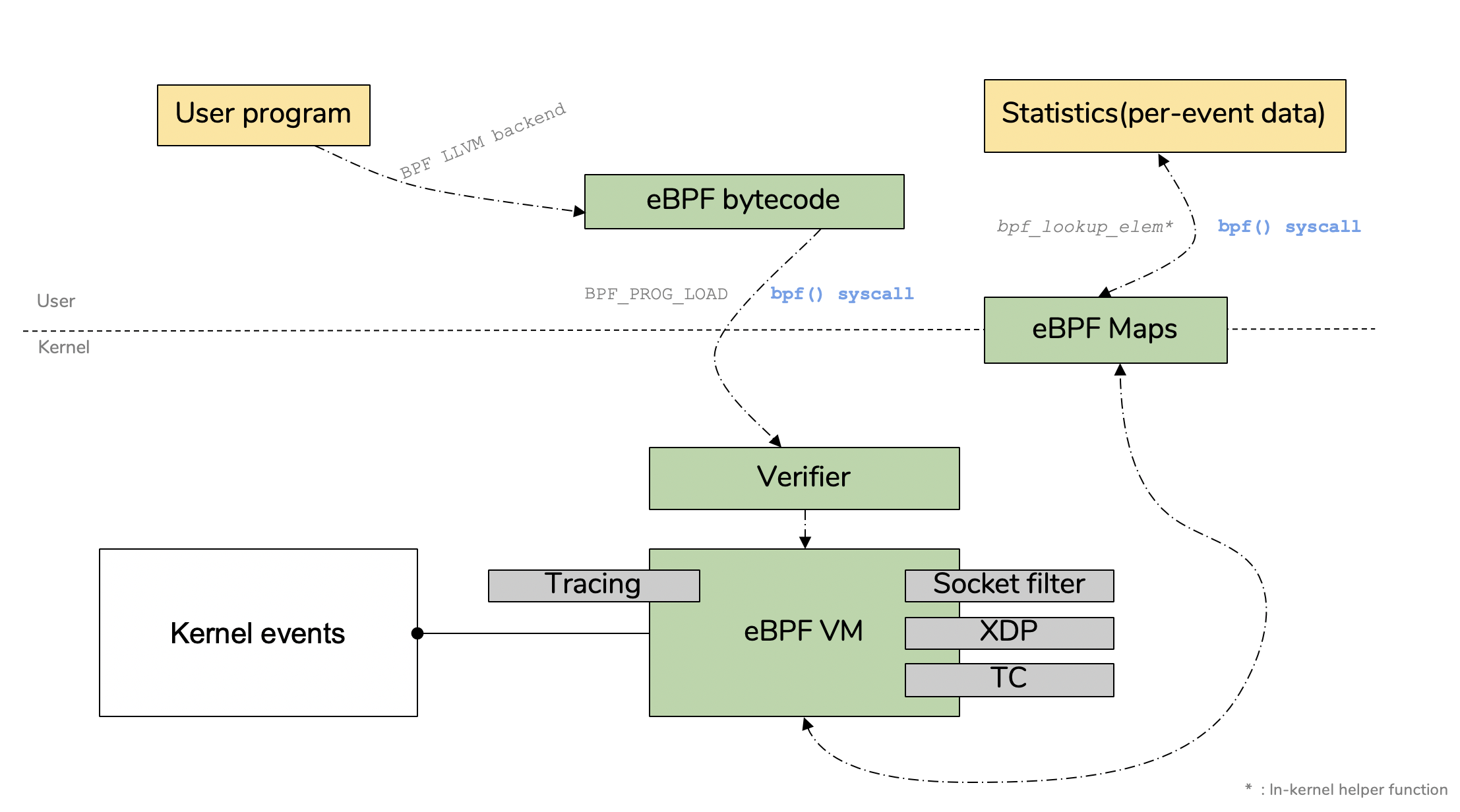
1.BPF Map是什么
如上图,简单来说,BPF Map就是内核空间和用户空间之间用于数据交换、信息传递的桥梁。是eBPF程序中使用的主要数据结构。
BPF Map本质上是以「键/值」方式存储在内核中的数据结构,它们可以被任何知道它们的BPF程序访问。
在内核空间的程序创建BPF Map并返回对应的文件描述符,在用户空间运行的程序就可以通过这个文件描述符来访问并操作BPF Map,从而实现kernel内核空间与user用户空间的数据交换。
2. BPF Map数据结构
每个BPF Map由四个值定义:类型、元素的最大个数、值大小(以字节为单位)和键大小(以字节为单位)
# BPF Map 定义示例
struct {
__uint(type, BPF_MAP_TYPE_HASH); // 类型
__uint(max_entries, 8192); // 元素的最大个数
__type(key, pid_t); // 键大小(以字节为单位)
__type(value, u64); // 值大小(以字节为单位)
} rb SEC(".maps"); // SEC(".maps") 声明并创建了一个名为rb的BPFMap二、BPF Map类型
1. bpf_map_type类型定义全集
所有 map 类型的定义:
// https://github.com/torvalds/linux/blob/v5.10/include/uapi/linux/bpf.h#L130
enum bpf_map_type {
BPF_MAP_TYPE_UNSPEC,
BPF_MAP_TYPE_HASH, // 一种哈希表
BPF_MAP_TYPE_ARRAY, // 一种为快速查找速度而优化的数组类型map键值对,通常用于计数器
BPF_MAP_TYPE_PROG_ARRAY, // 与eBPF程序相对应的一种文件描述符数组;用于实现跳转表和处理特定(网络)包协议的子程序
BPF_MAP_TYPE_PERF_EVENT_ARRAY, // 存储指向perf_event数据结构的指针,用于读取和存储perf事件计数器
BPF_MAP_TYPE_PERCPU_HASH, // 一种基于每个CPU的哈希表
BPF_MAP_TYPE_PERCPU_ARRAY, // 一种基于每个cpu的数组,用于实现展现延迟的直方图
BPF_MAP_TYPE_STACK_TRACE, // 存储堆栈跟踪信息
BPF_MAP_TYPE_CGROUP_ARRAY, // 存储指向控制组的指针
BPF_MAP_TYPE_LRU_HASH, // 一种只保留最近使用项的哈希表
BPF_MAP_TYPE_LRU_PERCPU_HASH, // 一种基于每个CPU的哈希表,只保留最近使用项
BPF_MAP_TYPE_LPM_TRIE, // 一个匹配最长前缀的字典树数据结构,适用于将IP地址匹配到一个范围
BPF_MAP_TYPE_ARRAY_OF_MAPS, // 一种map-in-map数据结构
BPF_MAP_TYPE_HASH_OF_MAPS, // 一种map-in-map数据结构
BPF_MAP_TYPE_DEVMAP,
BPF_MAP_TYPE_SOCKMAP,
BPF_MAP_TYPE_CPUMAP,
BPF_MAP_TYPE_XSKMAP,
BPF_MAP_TYPE_SOCKHASH,
BPF_MAP_TYPE_CGROUP_STORAGE,
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY,
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE,
BPF_MAP_TYPE_QUEUE,
BPF_MAP_TYPE_STACK,
BPF_MAP_TYPE_SK_STORAGE,
BPF_MAP_TYPE_DEVMAP_HASH,
BPF_MAP_TYPE_STRUCT_OPS,
BPF_MAP_TYPE_RINGBUF, // 一种高性能字节形缓冲区
BPF_MAP_TYPE_INODE_STORAGE,
};注: bcc 维护的文档, 记录了哪个内核版本引入的,以及对应的 patch。
2. Hash Maps
Hash map 的实现见 kernel/bpf/hashtab.c。 五种类型共用一套代码:
BPF_MAP_TYPE_HASHBPF_MAP_TYPE_PERCPU_HASHBPF_MAP_TYPE_LRU_HASHBPF_MAP_TYPE_LRU_PERCPU_HASHBPF_MAP_TYPE_HASH_OF_MAPS
Hash map 的特点:
- key 的长度没有限制。
- 给定 key 查找 value 时,内部通过哈希实现,而非数组索引。 key/value 是可删除的;作为对比,Array 类型的 map 中,key/value 是不可删除的(但用空值覆盖掉 value ,可实现删除效果)。原因其实也很简单:哈希表是链表,可以删除链表中的元素;array 是内存空间连续的数组,即使某个 index 处的 value 不用了,这段内存区域还是得留着,不可能将其释放掉。
不带与带 PERCPU 的 map 的区别:
- 前者是 global 的,只有一个实例;后者是 cpu-local 的,每个 CPU 上都有一个 map 实例;
- 多核并发访问时,global map 要加锁;per-cpu map 无需加锁,每个核上的程序访问 local-cpu 上的 map;最后将所有 CPU 上的 map 汇总。
2.1 BPF_MAP_TYPE_HASH
最简单的哈希 map。
初始化时需要指定支持的最大条目数(max_entries)。 满了之后继续插入数据时,会报 E2BIG 错误。
使用场景:
- 场景一:将内核态得到的数据,传递给用户态程序
- 这是非常典型的在内核态和用户态传递数据场景。
- 例如,BPF 程序过滤网络设备设备上的包,统计流量信息,并将其写到 map。 用户态程序从 map 读取统计,做后续处理。
- 场景二:存放全局配置信息,供 BPF 程序使用
- 例如,对于防火墙功能的 BPF 程序,将过滤规则放到 map 里。用户态控制程序通过 bpftool 之类的工具更新 map 里的配置信息,BPF 程序动态加载。
程序示例:
- 将内核态数据传递到用户态:
samples/bpf/sockex2 - 这个例子用 BPF 程序 过滤网络设备设备上的包,统计包数和字节数, 并以目的 IP 地址为 key 将统计信息写到 map:
// samples/bpf/sockex2_kern.c
struct {
__uint(type, BPF_MAP_TYPE_HASH); // BPF map 类型
__uint(max_entries, 1024); // 最大 entry 数量
__type(key, __be32); // 目的 IP 地址
__type(value, struct pair); // 包数和字节数
} hash_map SEC(".maps");
SEC("socket2")
int bpf_prog2(struct __sk_buff *skb)
{
flow_dissector(skb, &flow);
key = flow.dst; // 目的 IP 地址
value = bpf_map_lookup_elem(&hash_map, &key);
if (value) { // 如果已经存在,则更新相应计数
__sync_fetch_and_add(&value->packets, 1);
__sync_fetch_and_add(&value->bytes, skb->len);
} else { // 否则,新建一个 entry
struct pair val = {1, skb->len};
bpf_map_update_elem(&hash_map, &key, &val, BPF_ANY);
}
return 0;
}2.2 BPF_MAP_TYPE_PERCPU_HASH
使用场景:
- 基本同上。
程序示例:
- samples/bpf/map_perf_test_kern.c
2.3 BPF_MAP_TYPE_LRU_HASH
普通 hash map 的问题是有大小限制,超过最大数量后无法再插入了。LRU map 可以避 免这个问题,如果 map 满了,再插入时它会自动将最久未被使用(least recently used)的 entry 从 map 中移除。
使用场景:
- 场景一:连接跟踪(conntrack)表、NAT 表等固定大小哈希表
- 满了之后最老的 entry 会被踢出去。
程序示例:
- samples/bpf/map_perf_test_kern.c
2.4 BPF_MAP_TYPE_LRU_PERCPU_HASH
基本同上。
2.5 BPF_MAP_TYPE_HASH_OF_MAPS
map-in-map:第一个 map 内的元素是指向另一个 map 的指针。 与后面将介绍的 BPF_MAP_TYPE_ARRAY_OF_MAPS 类似,但外层 map 使用的是哈希而不是数组。
可以将 整个(内层)map 在运行时实现原子替换。
相关 commit message。
使用场景:
- map-in-map
- Array of array
- Hash of array
- Hash of hash
程序示例:
- samples/bpf/test_map_in_map_kern.c
3. Array Maps
3.1 BPF_MAP_TYPE_ARRAY
最大的特点:key 就是数组中的索引(index)(因此 key一定是整形),因此无需对key进行哈希。
使用场景:
- key 是整形
程序示例:
- 根据协议类型(proto as key)统计流量:
samples/bpf/sockex1
// samples/bpf/sockex1_kern.c
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 256);
__type(key, u32); // L4 协议类型(长度是 uint8),例如 IPPROTO_TCP,范围是 0~255
__type(value, long); // 累计包长(skb->len)
} my_map SEC(".maps");
SEC("socket1")
int bpf_prog1(struct __sk_buff *skb)
{
int index = load_byte(skb, ETH_HLEN + offsetof(struct iphdr, protocol)); // L4 协议类型
if (skb->pkt_type != PACKET_OUTGOING)
return 0;
// 注意:在用户态程序和这段 BPF 程序里都没有往 my_map 里插入数据;
// * 如果这是 hash map 类型,那下面的 lookup 一定失败,因为我们没插入过任何数据;
// * 但这里是 array 类型,而且 index 表示的 L4 协议类型,在 IP 头里占一个字节,因此范围在 255 以内;
// 又 map 的长度声明为 256,所以这里的 lookup 一定能定位到 array 的某个位置,即查找一定成功。
value = bpf_map_lookup_elem(&my_map, &index);
if (value)
__sync_fetch_and_add(value, skb->len);
return 0;
}
3.2 BPF_MAP_TYPE_PERCPU_ARRAY
基本同上。
3.3 BPF_MAP_TYPE_PROG_ARRAY
程序数组,尾调用 bpf_tail_call() 时会用到。
- key:任意整形(因为要作为 array index),具体表示什么由使用者设计(例如表示协议类型 proto)。
- value:BPF 程序的文件描述符(fd)。
使用场景:
- 尾调用(tail call)
程序示例:
- 根据协议类型尾调用到下一层 parser:samples/bpf/sockex3
3.4 BPF_MAP_TYPE_PERF_EVENT_ARRAY
使用场景:
- 保存 tracing 结果
程序示例:
- 保存 perf event:samples/bpf/trace_output_kern.c
// samples/bpf/trace_output_kern.c
struct bpf_map_def SEC("maps") my_map = {
.type = BPF_MAP_TYPE_PERF_EVENT_ARRAY,
.max_entries = 2,
.key_size = sizeof(int),
.value_size = sizeof(u32),
};
SEC("kprobe/sys_write")
int bpf_prog1(struct pt_regs *ctx)
{
struct S {
u64 pid;
u64 cookie;
} data;
data.pid = bpf_get_current_pid_tgid();
data.cookie = 0x12345678;
bpf_perf_event_output(ctx, &my_map, 0, &data, sizeof(data));
return 0;
}
3.5 BPF_MAP_TYPE_ARRAY_OF_MAPS
使用场景:
- map-in-map
- map-in-map,values 是指向内层 map 的 fd。只支持两层 map。 two levels of map,也就是一层 map 嵌套另一层 map。
- BPF_MAP_TYPE_PROG_ARRAY类型的 BPF 程序不支持 map-in-map 功能 ,因为这会使 tail call 的 verification 更加困难。
程序示例:
- samples/bpf/map_perf_test_kern.c
- samples/bpf/test_map_in_map_kern.c
3.6 BPF_MAP_TYPE_CGROUP_ARRAY
在用户空间存放 cgroup fds,用来检查给定的 skb 是否与 cgroup_array[index] 指向的 cgroup 关联。
使用场景:
- cgroup 级别的包过滤(拒绝/放行)
- cgroup 级别的进程过滤(权限控制等)
程序示例:
- Pin & update pinned cgroup array:samples/bpf/test_cgrp2_array_pin.c
- 将 cgroupv2 array pin 到 BPFFS
- 更新 pinned cgroupv2 array
// samples/bpf/test_cgrp2_array_pin.c
if (create_array) {
array_fd = bpf_create_map(BPF_MAP_TYPE_CGROUP_ARRAY, sizeof(uint32_t), sizeof(uint32_t), 1, 0);
} else {
array_fd = bpf_obj_get(pinned_file);
}
bpf_map_update_elem(array_fd, &array_key, &cg2_fd, 0);
if (create_array) {
ret = bpf_obj_pin(array_fd, pinned_file);
}
- CGroup 级别的包过滤:samples/bpf/test_cgrp2_tc_kern.c
- 核心是调用 bpf_skb_under_cgroup() 判断 skb 是否在给定 cgroup 中:
// samples/bpf/test_cgrp2_tc_kern.c
struct bpf_elf_map SEC("maps") test_cgrp2_array_pin = {
.type = BPF_MAP_TYPE_CGROUP_ARRAY,
.size_key = sizeof(uint32_t),
.size_value = sizeof(uint32_t),
.pinning = PIN_GLOBAL_NS,
.max_elem = 1,
};
SEC("filter")
int handle_egress(struct __sk_buff *skb)
{
...
if (bpf_skb_under_cgroup(skb, &test_cgrp2_array_pin, 0) != 1) {
bpf_trace_printk(pass_msg, sizeof(pass_msg));
return TC_ACT_OK;
}
...
}
- 判断进程是否在给定 cgroup 中:samples/bpf/test_current_task_under_cgroup_kern.c
- 调用 bpf_current_task_under_cgroup() 判断当前进程是否在给定 cgroup 中:
struct bpf_map_def SEC("maps") cgroup_map = {
.type = BPF_MAP_TYPE_CGROUP_ARRAY,
.key_size = sizeof(u32),
.value_size = sizeof(u32),
.max_entries = 1,
};
/* Writes the last PID that called sync to a map at index 0 */
SEC("kprobe/sys_sync")
int bpf_prog1(struct pt_regs *ctx)
{
...
if (!bpf_current_task_under_cgroup(&cgroup_map, 0))
return 0;
...
}
4. CGroup Maps
4.1 BPF_MAP_TYPE_CGROUP_ARRAY
上边3.6节已经有详细介绍。
4.2 BPF_MAP_TYPE_CGROUP_STORAGE
Attach 到一个 cgroup 的所有 BPF 程序,会共用一组 cgroup storage,包括:
for (stype = 0; stype < MAX_BPF_CGROUP_STORAGE_TYPE; stype++)
storages[stype] = bpf_cgroup_storage_alloc(prog, stype);
这里的 types 目前只有两种:shared、per-cpu
使用场景:
- cgroup 内所有 BPF 程序的共享存储:samples/bpf/hbm_kern.h:host bandwidth manager
struct {
__uint(type, BPF_MAP_TYPE_CGROUP_STORAGE);
__type(key, struct bpf_cgroup_storage_key);
__type(value, struct hbm_vqueue);
} queue_state SEC(".maps");
4.3 BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE
同上。
5. Tracing Maps
5.1 BPF_MAP_TYPE_STACK_TRACE
内核程序能通过 bpf_get_stackid() helper 存储 stack 信息。 将 stack 信息关联到一个 id,而这个 id 是对当前栈的 指令指针地址(instruction pointer address)进行 32-bit hash 得到的。
使用场景:
- 存储 profiling 信息
- 在内核中获取 stack id,用它作为 key 更新另一个 map。 例如通过对指定的 stack traces 进行 profiling,统计它们的出现次数,或者将 stack trace 信息与当前 pid 关联起来。
- 程序示例:打印调用栈:samples/bpf/offwaketime_kern.c
5.2 BPF_MAP_TYPE_STACK
5.3 BPF_MAP_TYPE_RINGBUF
BPF perf buffer(perfbuf)是目前这一过程的事实标准,但它存在一些问题,例如 浪费内存(因为其 per-CPU 设计)、事件顺序无法保证等。
作为改进,内核 5.8 引入另一个新的 BPF 数据结构:BPF ring buffer(环形缓冲区,ringbuf):
- 相比 perf buffer,它内存效率更高、保证事件顺序,性能也不输前者;
- 在使用上,既提供了与 perf buffer 类似的 API ,以方便用户迁移;又提供了一套新的 reserve/commit API(先预留再提交),以实现更高性能。
ringbuf 是一个“多生产者、单消费者”(multi-producer, single-consumer,MPSC) 队列,可安全地在多个 CPU 之间共享和操作。perfbuf 支持的一些功能它都支持,包括:
- 可变长数据(variable-length data records);
- 通过 memory-mapped region 来高效地从 userspace 读数据,避免内存复制或系统调用;
- 支持 epoll notifications 和 busy-loop 两种获取数据方式。
此外,实验与真实环境的压测结果都表明,从 BPF 程序发送数据给用户空间时, 应该首选 BPF ring buffer。
使用场景:
- 更高效、保证事件顺序地往用户空间发送数据
- 常规场景:对于所有实际场景(尤其是那些基于 bcc/libbpf 的默认配置在使用 perfbuf 的场景), ringbuf 的性能都优于 perfbuf 性能。各种不同场景的仿真压测(synthetic benchmarking)
- 高吞吐场景:每秒百万级事件(millions of events per second)以上的场景
内核 BPF 示例程序:BPF-side code
--- src/perfbuf-output.bpf.c 2020-10-25 18:52:22.247019800 -0700
+++ src/ringbuf-output.bpf.c 2020-10-25 18:44:14.510630322 -0700
@@ -6,12 +6,11 @@
char LICENSE[] SEC("license") = "Dual BSD/GPL";
-/* BPF perfbuf map */
+/* BPF ringbuf map */
struct {
- __uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
- __uint(key_size, sizeof(int));
- __uint(value_size, sizeof(int));
-} pb SEC(".maps");
+ __uint(type, BPF_MAP_TYPE_RINGBUF);
+ __uint(max_entries, 256 * 1024); // 256 KB
+} rb SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_ARRAY);
@@ -35,7 +34,7 @@
bpf_get_current_comm(&e->comm, sizeof(e->comm));
bpf_probe_read_str(&e->filename, sizeof(e->filename), (void *)ctx + fname_off);
- bpf_perf_event_output(ctx, &pb, BPF_F_CURRENT_CPU, e, sizeof(*e));
+ bpf_ringbuf_output(&rb, e, sizeof(*e), 0);
return 0;
}可以看到两者的差异:
- max_entries 的单位是字节,必须是内核页大小( 几乎永远是 4096)的倍数,也必须是 2 的幂次。
- bpf_perf_event_output() 替换成了类似的 bpf_ringbuf_output(),后者更简单,不需要 BPF context 参数
用户空间示例程序:user-space code
事件 handler 签名有点变化:
- 会返回错误信息(进而终止 consumer 循环)
- 参数里面去掉了产生这个事件的 CPU Index
-void handle_event(void *ctx, int cpu, void *data, unsigned int data_sz)
+int handle_event(void *ctx, void *data, size_t data_sz)
{
const struct event *e = data;
struct tm *tm;5.4 BPF_MAP_TYPE_PERF_EVENT_ARRAY
使用场景:
- Perf events:BPF 程序将数据存储在
mmap()共享内存中,用户空间程序可以访问。samples/bpf/trace_output:trace write() 系统调用- 非固定大小数据(不适合 map)
- 无需与其他 BPF 程序共享数据
6. Socket Maps
6.1 BPF_MAP_TYPE_SOCKMAP
主要用于 socket redirection:将 sockets 信息插入到 map,后面执行到 bpf_sockmap_redirect() 时,用 map 里的信息触发重定向。
使用场景:
- socket redirection(重定向)
6.2 BPF_MAP_TYPE_REUSEPORT_SOCKARRAY
配合 BPF_PROG_TYPE_SK_REUSEPORT 类型的 BPF 程序使用,加速 socket 查找。
使用场景:
- 配合 _SK_REUSEPORT 类型 BPF 程序,加速 socket 查找
6.3 BPF_MAP_TYPE_SK_STORAGE
使用场景:
- per-socket 存储空间
- 在内核定期 dump socket 详情:samples/bpf/tcp_dumpstats_kern.c
struct {
__u32 type;
__u32 map_flags;
int *key;
__u64 *value;
} bpf_next_dump SEC(".maps") = {
.type = BPF_MAP_TYPE_SK_STORAGE,
.map_flags = BPF_F_NO_PREALLOC,
};
SEC("sockops")
int _sockops(struct bpf_sock_ops *ctx)
{
struct bpf_tcp_sock *tcp_sk;
struct bpf_sock *sk;
__u64 *next_dump;
switch (ctx->op) {
case BPF_SOCK_OPS_TCP_CONNECT_CB:
bpf_sock_ops_cb_flags_set(ctx, BPF_SOCK_OPS_RTT_CB_FLAG);
return 1;
case BPF_SOCK_OPS_RTT_CB:
break;
default:
return 1;
}
sk = ctx->sk;
next_dump = bpf_sk_storage_get(&bpf_next_dump, sk, 0, BPF_SK_STORAGE_GET_F_CREATE);
now = bpf_ktime_get_ns();
if (now < *next_dump)
return 1;
tcp_sk = bpf_tcp_sock(sk);
*next_dump = now + INTERVAL;
bpf_printk("dsack_dups=%u delivered=%u\n", tcp_sk->dsack_dups, tcp_sk->delivered);
bpf_printk("delivered_ce=%u icsk_retransmits=%u\n", tcp_sk->delivered_ce, tcp_sk->icsk_retransmits);
return 1;
}总体来看,BPF_MAP_TYPE_HASH、BPF_MAP_TYPE_ARRAY、BPF_MAP_TYPE_RINGBUF这个类型基本可以覆盖到大部分内核与用户空间传递数据的需求场景,且能满足高性能的要求。
三、BPF Map操作
BPF Map创建后,对其CRUD操作主要涉及几个方法:
helper:(kernel space)
- void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)
- long bpf_map_update_elem(struct bpf_map *map, const void *key,
const void *value, u64 flags)
- long bpf_map_delete_elem(struct bpf_map *map, const void *key)
- ...
libbpf:(user space)
// https://elixir.bootlin.com/linux/v4.19.261/source/tools/lib/bpf/bpf.c#L299
- int bpf_map_lookup_elem(int fd, const void *key, void *value)
- int bpf_map_update_elem(int fd, const void *key, const void *value,
__u64 flags)
- int bpf_map_delete_elem(int fd, const void *key)
- ...1. bpf_map_lookup_elem(map, key)
通过key查询BPF Map,得到对应value。
2. bpf_map_update_elem(map, key, value, options)
通过key-value更新BPF Map,如果这个key不存在,也可以作为新的元素插入到BPF Map中去。
3. bpf_map_delete_elem(map, key)
删除BPF Map中的某个key。
好了,今天主要熟悉了下BPF Map的作用、常见Map类型的使用方法、以及Map的常规操作。下一次,我们再继续深入的学习eBPF程序的开发方法。
yan 23.12.8
参考:
BPF 进阶笔记(二):BPF Map 类型详解:使用场景、程序示例
[译] BPF ring buffer:使用场景、核心设计及程序示例(2020)
