在前两篇文章中,我们了解了eBPF的基本知识。本文开始进行一次具体的实践,带大家通过kprobe实现一个简单的内核系统调用捕获,来了解如何在内核函数的出入口动态注入自定义代码。
一、概述
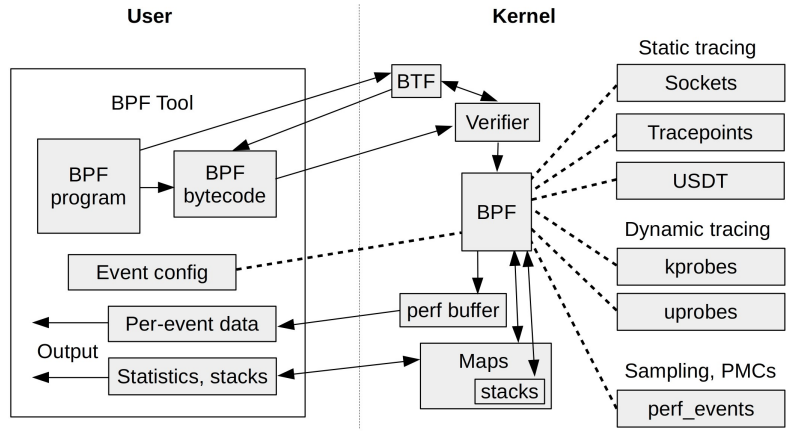
1. 什么是kprobe?
开发人员在内核或者模块的调试过程中,往往会需要要知道其中的一些函数有无被调用、何时被调用、执行是否正确以及函数的入参和返回值是什么等等。比较简单的做法是在内核代码对应的函数中添加日志打印信息,但这种方式往往需要重新编译内核或模块,重新启动设备之类的,操作较为复杂甚至可能会破坏原有的代码执行过程。
而利用 kprobes 技术,用户可以定义自己的回调函数,然后在内核或者模块中几乎所有的函数中(有些函数是不可探测的,例如kprobes自身的相关实现函数,后文会有详细说明)动态地插入探测点,当内核执行流程执行到指定的探测函数时,会调用该回调函数,用户即可收集所需的信息了,同时内核最后还会回到原本的正常执行流程。如果用户已经收集足够的信息,不再需要继续探测,则同样可以动态地移除探测点。因此 kprobes 技术具有对内核执行流程影响小和操作方便的优点。
kprobes 技术包括的3种探测手段分别时 kprobe、jprobe 和 kretprobe。首先 kprobe 是最基本的探测方式,是实现后两种的基础,它可以在任意的位置放置探测点(就连函数内部的某条指令处也可以),它提供了探测点的调用前、调用后和内存访问出错3种回调方式,分别是 pre_handler、post_handler 和 fault_handler,其中 pre_handler 函数将在被探测指令被执行前回调,post_handler 会在被探测指令执行完毕后回调(注意不是被探测函数),fault_handler 会在内存访问出错时被调用;jprobe 基于 kprobe 实现,它用于获取被探测函数的入参值;最后 kretprobe 从名字中就可以看出其用途了,它同样基于 kprobe 实现,用于获取被探测函数的返回值。
kprobes 的技术原理并不仅仅包含纯软件的实现方案,它也需要硬件架构提供支持。其中涉及硬件架构相关的是 CPU 的异常处理和单步调试技术,前者用于让程序的执行流程陷入到用户注册的回调函数中去,而后者则用于单步执行被探测点指令,因此并不是所有的架构均支持 kprobes。目前 kprobes 技术已经支持多种架构,包括 i386、x86_64、ppc64、ia64、sparc64、arm、ppc 和 mips(有些架构实现可能并不完全,具体可参考内核的 Documentation/kprobes.txt)。
kprobes 的特点与使用限制:
- kprobes 允许在同一个被探测位置注册多个 kprobe,但是目前 jprobe 却不可以;同时也不允许以其他的 jprobe 回调函数和 kprobe 的 post_handler 回调函数作为被探测点。
- 一般情况下,可以探测内核中的任何函数,包括中断处理函数。不过在 kernel/kprobes.c 和 arch/*/kernel/kprobes.c 程序中用于实现 kprobes 自身的函数是不允许被探测的,另外还有do_page_fault 和 notifier_call_chain;
- 如果以一个内联函数为探测点,则 kprobes 可能无法保证对该函数的所有实例都注册探测点。由于 gcc 可能会自动将某些函数优化为内联函数,因此可能无法达到用户预期的探测效果;
- 一个探测点的回调函数可能会修改被探测函数的运行上下文,例如通过修改内核的数据结构或者保存与struct pt_regs结构体中的触发探测器之前寄存器信息。因此 kprobes 可以被用来安装 bug 修复代码或者注入故障测试代码;
- kprobes 会避免在处理探测点函数时再次调用另一个探测点的回调函数,例如在printk()函数上注册了探测点,而在它的回调函数中可能会再次调用printk函数,此时将不再触发printk探测点的回调,仅仅是增加了kprobe结构体中nmissed字段的数值;
- 在 kprobes 的注册和注销过程中不会使用 mutex 锁和动态的申请内存;
- kprobes 回调函数的运行期间是关闭内核抢占的,同时也可能在关闭中断的情况下执行,具体要视CPU架构而定。因此不论在何种情况下,在回调函数中不要调用会放弃 CPU 的函数(如信号量、mutex 锁等);
- kretprobe 通过替换返回地址为预定义的 trampoline 的地址来实现,因此栈回溯和 gcc 内嵌函数__builtin_return_address()调用将返回 trampoline 的地址而不是真正的被探测函数的返回地址;
- 如果一个函数的调用次数和返回次数不相等,则在类似这样的函数上注册 kretprobe 将可能不会达到预期的效果,例如do_exit()函数会存在问题,而do_execve()函数和do_fork()函数不会;
- 当在进入和退出一个函数时,如果 CPU 运行在非当前任务所有的栈上,那么往该函数上注册 kretprobe 可能会导致不可预料的后果,因此,kprobes 不支持在 X86_64 的结构下为__switch_to()函数注册 kretprobe,将直接返回-EINVAL。
二、实践
1. 准备kernel内核源码
在对系统调用植入探针的过程中,我们需要了解对应函数的参数和返回值定义,因此我们需要提前下载好对应版本的内核源码,以便随时查阅:
# 确认目标设备的linux版本
uname -a
5.15.0-83-generic
# 下载kernel源码
git clone git@github.com:torvalds/linux.git -b v5.152. kprobe ebpf程序实例
为了方便调试,我们这里选取内核的do_unlinkat函数(删除文件事件)进行自定义代码植入。
2.1 内核do_unlinkat函数定义
开始之前,我们先来看下内核源码中这个函数的定义:
cd ~/project/linux
grep -w do_unlinkat -r ./
./fs/internal.h:int do_unlinkat(int dfd, struct filename *name);可以看到,该函数接受2个参数:dfd(文件描述符)和name(文件名结构体指针),返回值为int,我们接下来编写ebpf程序时会用到这个定义。
2.2 ebpf探测函数
我们编写一个简单的kprobe.bpf.c程序,通过使使用kprobe(内核探针)在内核do_unlinkat函数的入口和退出位置添加钩子,实现对Linux 内核中的unlink 系统调用的入口参数和返回值的监测和捕获:
/**
* 通过使用 kprobe(内核探针)在do_unlinkat函数的入口和退出处放置钩子,实现对该系统调用的跟踪
*/
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
// 定义许可证,以允许程序在内核中运行
char LICENSE[] SEC("license") = "Dual BSD/GPL";
// 定义一个名为do_unlinkat的 kprobe,当进入do_unlinkat函数时,它会被触发
SEC("kprobe/do_unlinkat")
int BPF_KPROBE(do_unlinkat, int dfd, struct filename *name) // 捕获函数的参数:dfd(文件描述符)和name(文件名结构体指针)
{
pid_t pid;
const char *filename;
// 获取当前进程的 PID(进程标识符)
pid = bpf_get_current_pid_tgid() >> 32;
// 读取文件名
filename = BPF_CORE_READ(name, name);
// 使用bpf_printk函数在内核日志中打印 PID 和文件名
bpf_printk("KPROBE ENTRY pid = %d, filename = %s\n", pid, filename);
return 0;
}
// 定义一个名为do_unlinkat_exit的 kretprobe,当从do_unlinkat函数退出时,它会被触发
SEC("kretprobe/do_unlinkat")
int BPF_KRETPROBE(do_unlinkat_exit, long ret) // 捕获函数的返回值(ret)
{
pid_t pid;
// 获取当前进程的 PID(进程标识符)
pid = bpf_get_current_pid_tgid() >> 32;
// 使用bpf_printk函数在内核日志中打印 PID 和返回值
bpf_printk("KPROBE EXIT: pid = %d, ret = %ld\n", pid, ret);
return 0;
}2.3 加载程序
编写一个bpf用户空间程序,用于加载刚才编写的ebpf钩子到内核空间:
/**
* ebpf 用户空间程序(loader、read ringbuffer)
*/
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
#include <string.h>
#include <errno.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "kprobe.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
static volatile sig_atomic_t stop;
static void sig_int(int signo)
{
stop = 1;
}
int main(int argc, char **argv)
{
struct kprobe_bpf *skel;
int err;
/* 设置libbpf错误和调试信息回调 */
libbpf_set_print(libbpf_print_fn);
/* 加载并验证 kprobe.bpf.c 应用程序 */
skel = kprobe_bpf__open_and_load();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
/* 附加 kprobe.bpf.c 程序到跟踪点 */
err = kprobe_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
/* Control-C 停止信号 */
if (signal(SIGINT, sig_int) == SIG_ERR) {
fprintf(stderr, "can't set signal handler: %s\n", strerror(errno));
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
while (!stop) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
/* 销毁挂载的ebpf程序 */
kprobe_bpf__destroy(skel);
return -err;
}
2.4 cmake编译配置
为kprobe.bpf.c、kprobe.c配置cmake编译:
cmake_minimum_required(VERSION 3.16)
project(ebpf_test)
# find BpfObject
list(APPEND CMAKE_MODULE_PATH ${CMAKE_CURRENT_SOURCE_DIR}/tools)
# build libbpf depend
include(ExternalProject)
ExternalProject_Add(libbpf
PREFIX libbpf
SOURCE_DIR ${CMAKE_CURRENT_SOURCE_DIR}/../../libbpf/src
CONFIGURE_COMMAND ""
BUILD_COMMAND make
BUILD_STATIC_ONLY=1
OBJDIR=${CMAKE_CURRENT_BINARY_DIR}/libbpf/libbpf
DESTDIR=${CMAKE_CURRENT_BINARY_DIR}/libbpf
INCLUDEDIR=
LIBDIR=
UAPIDIR=
install install_uapi_headers
BUILD_IN_SOURCE TRUE
INSTALL_COMMAND ""
STEP_TARGETS build
)
ExternalProject_Add(bpftool
PREFIX bpftool
SOURCE_DIR ${CMAKE_CURRENT_SOURCE_DIR}/../../bpftool/src
CONFIGURE_COMMAND ""
BUILD_COMMAND make bootstrap
OUTPUT=${CMAKE_CURRENT_BINARY_DIR}/bpftool/
BUILD_IN_SOURCE TRUE
INSTALL_COMMAND ""
STEP_TARGETS build
)
find_program(CARGO_EXISTS cargo)
if(CARGO_EXISTS)
ExternalProject_Add(blazesym
PREFIX blazesym
SOURCE_DIR ${CMAKE_CURRENT_SOURCE_DIR}/../../blazesym
CONFIGURE_COMMAND ""
BUILD_COMMAND cargo build --release
BUILD_IN_SOURCE TRUE
INSTALL_COMMAND ""
STEP_TARGETS build
)
endif()
# Set BpfObject input parameters
set(BPFOBJECT_BPFTOOL_EXE ${CMAKE_CURRENT_BINARY_DIR}/bpftool/bootstrap/bpftool)
set(BPFOBJECT_VMLINUX_H ${CMAKE_CURRENT_SOURCE_DIR}/../../vmlinux/${ARCH}/vmlinux.h)
set(LIBBPF_INCLUDE_DIRS ${CMAKE_CURRENT_BINARY_DIR}/libbpf)
set(LIBBPF_LIBRARIES ${CMAKE_CURRENT_BINARY_DIR}/libbpf/libbpf.a)
find_package(BpfObject REQUIRED)
# Create an executable for each application
file(GLOB apps *.bpf.c)
if(NOT CARGO_EXISTS)
list(REMOVE_ITEM apps ${CMAKE_CURRENT_SOURCE_DIR}/profile.bpf.c)
endif()
foreach(app ${apps})
get_filename_component(app_name ${app} NAME_WE)
# Build object skeleton and depend skeleton on libbpf build
bpf_object(${app_name} ${app_name}.bpf.c)
add_dependencies(${app_name}_skel libbpf-build bpftool-build)
add_executable(${app_name} ${app_name}.c)
target_link_libraries(${app_name} ${app_name}_skel)
if(${app_name} STREQUAL profile)
target_include_directories(${app_name} PRIVATE
${CMAKE_CURRENT_SOURCE_DIR}/../../blazesym/include)
target_link_libraries(${app_name}
${CMAKE_CURRENT_SOURCE_DIR}/../../blazesym/target/release/libblazesym.a -lpthread -lrt -ldl)
endif()
endforeach()
2.5 编译&调试
# 编译
mkdir build && cd build
cmake ..
make
# 挂载自定义探针到内核
sudo ./kprobe
# 监控内核日志
sudo cat /sys/kernel/debug/tracing/trace_pipe
# 测试unlink删除事件
touch test1
rm test1
touch test2
rm test2
# 从监控的内核log中可以看到探针已经生效
sudo cat /sys/kernel/debug/tracing/trace_pipe
rm-260674 [002] d...1 3556349.502552: bpf_trace_printk: KPROBE ENTRY pid = 260674, filename = test1
rm-260674 [002] d...1 3556349.502574: bpf_trace_printk: KPROBE EXIT: pid = 260674, ret = 0
rm-260676 [002] d...1 3556349.675106: bpf_trace_printk: KPROBE ENTRY pid = 260676, filename = test2
rm-260676 [002] d...1 3556349.675144: bpf_trace_printk: KPROBE EXIT: pid = 260676, ret = 0
3. 使用 ring buffer 向用户态传递数据
在刚才的实例里,内核捕获到的数据打印到了内核log中,需要通过查看 /sys/kernel/debug/tracing/trace_pipe 文件来获取eBPF程序的输出。
在上一篇文章里我们学习了BPF Map,所以这里我们把它修改下,将捕获到的数据通过ring buffer从内核空间传递到用户空间。用户空间获取数据后,可以再进行后续的数据存储、处理和分析。
3.1 定义存储数据的结构体
这里我们定义一个kprobe.h头文件,方便内核空间和用户空间的程序使用同一个数据存储结构。
#ifndef __KPROBE_H
#define __KPROBE_H
#define MAX_FILENAME_LEN 256
struct event {
int pid;
char filename[MAX_FILENAME_LEN];
bool exit_event;
unsigned exit_code;
unsigned long long ns;
};
#endif3.2 内核ebpf存储数据到ring buffer
修改kprobe.bpf.c,引入数据结构头文件:
#include <string.h>
#include "kprobe.h"定义一个名为rb的 ring buffer 类型的Map:
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 256 * 1024); // 256 KB
} rb SEC(".maps");在ebpf探针函数中保存数据到ring buffer:
SEC("kprobe/do_unlinkat")
int BPF_KPROBE(do_unlinkat, int dfd, struct filename *name) // 该函数接受两个参数:dfd(文件描述符)和name(文件名结构体指针)
{
...
struct event *e;
...
// 预订一个ringbuf样本空间
e = bpf_ringbuf_reserve(&rb, sizeof(*e), 0);
if (!e)
return 0;
// 设置数据
e->pid = pid;
bpf_probe_read_str(&e->filename, sizeof(e->filename), (void *)filename);
e->exit_event = false;
e->ns = bpf_ktime_get_ns();
// 提交到ringbuf用户空间进行后处理
bpf_ringbuf_submit(e, 0);
return 0;
}3.3 用户空间读取ring buffer
定义ring_buffer结构体、handle_event回调函数,使用ring_buffer__new(skel->maps.rb的fd, handle_event回调)初始化用户空间缓冲区对象,并使用ring_buffer__poll(rb) 获取内核ebpf程序传递的数据,收到的内核数据可以在handle_event回调函数中进行打印、存储、分析等后续处理。
/**
* ebpf 用户空间程序(loader、read ringbuffer)
*/
...
#include <time.h>
#include "kprobe.h"
...
// ring buffer data process
static int handle_event(void *ctx, void *data, size_t data_sz)
{
const struct event *e = data;
struct tm *tm;
char ts[32];
time_t t;
time(&t);
tm = localtime(&t);
strftime(ts, sizeof(ts), "%H:%M:%S", tm);
if (e->exit_event) {
printf("%-8s %-5s %-16s %-7d [%u]", ts, "EXIT", e->filename, e->pid, e->exit_code);
if (e->ns)
printf(" (%llums)", e->ns / 1000000);
printf("\n");
} else {
printf("%-8s %-5s %-16s %-7d %s\n", ts, "EXEC", e->filename, e->pid, e->filename);
}
return 0;
}
int main(int argc, char **argv)
{
...
struct ring_buffer *rb = NULL;
...
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
/* 设置环形缓冲区轮询 */
rb = ring_buffer__new(bpf_map__fd(skel->maps.rb), handle_event, NULL, NULL);
if (!rb) {
err = -1;
fprintf(stderr, "Failed to create ring buffer\n");
goto cleanup;
}
/* 处理收到的内核数据 */
printf("%-8s %-5s %-16s %-7s %s\n", "TIME", "EVENT", "FILENAME", "PID", "FILENAME/RET");
while (!stop) {
// 轮询内核数据
err = ring_buffer__poll(rb, 100 /* timeout, ms */);
if (err == -EINTR) { /* Ctrl-C will cause -EINTR */
err = 0;
break;
}
if (err < 0) {
printf("Error polling perf buffer: %d\n", err);
break;
}
}
// while (!stop) {
// fprintf(stderr, ".");
// sleep(1);
// }
...
}
3.4 编译&测试
# 编译
cmake ..
make
# 挂载自定义探针到内核
sudo ./kprobe
# 测试unlink删除事件
touch test.txt
rm test.txt
# 用户空间程序可以直接输出内核传递的数据
sudo ./kprobe
TIME EVENT FILENAME PID FILENAME/RET
23:31:03 EXEC test.txt 269717 test.txt
23:31:03 EXIT 269717 [0] (3567267373ms)
可以看到内核采集到的数据已经顺利ring buffer传递到了用户空间并打印了出来,后续的存储、分析等逻辑自己单独写就行,就不在这里赘述了。
三、总结
今天我们学习了如何使用 eBPF 的 kprobe 和 kretprobe 捕获系统调用,并通过ring buffer将内核捕获到的数据传递到用户空间。下一次,我们将尝试如何捕获一个自定义程序中的函数或变量。如果你对其他的内容感兴趣,也可以告诉我~
yan 23.12.12
