问题描述:
在ubuntu22.04上编译autoware autoware_carla_interface库时,报setup.py install is deprecated命令已弃用stderr
在ubuntu22.04上编译autoware autoware_carla_interface库时,报setup.py install is deprecated命令已弃用stderr
在ubuntu22.04上编译autoware时,报TypeError: canonicalize_version() got an unexpected keyword argument ‘strip_trailing_zero’错误
Ubuntu20.04默认apt最高只能安装到python3.9,ros2的autoware对python3.10的新特性有依赖,因此需要升级到3.10+版本。

在进行嵌入式开发的过程中,经常会遇到通信协议是按bit位定义的情况,比如协议一共6个byte字节,每个byte一共8bit位,但是传输的很多数据用1、2个bit就足够了,这时协议会按bit定义,如何方便快捷的进行bit位的赋值和读取,即为本文讲解的内容。
我们在编写程序时经常会用到enum枚举类型,使用非常方便。但是当枚举定义较多时,在LOG打印时输出值很难直观的明白其含义,必须对照enum定义。本文介绍一个比较简单的方法,让LOG打印或std::cout输出枚举值时,直接输出文本。
有时用vscode打开比较大的工作目录,用一会儿机器会突然卡顿,鼠标都移动不了,但是查看系统资源会发现cpu全是空闲的,mem占用也不到50%,但是swap几乎处于打满状态。
日常开发时,不论是企业或组织都会对代码格式有统一的要求,本文主要讲解如何在vscode中自动按Google C++代码规范进行代码自动格式化和检查提示。如有需要也可以在此基础上进行自定义调整。
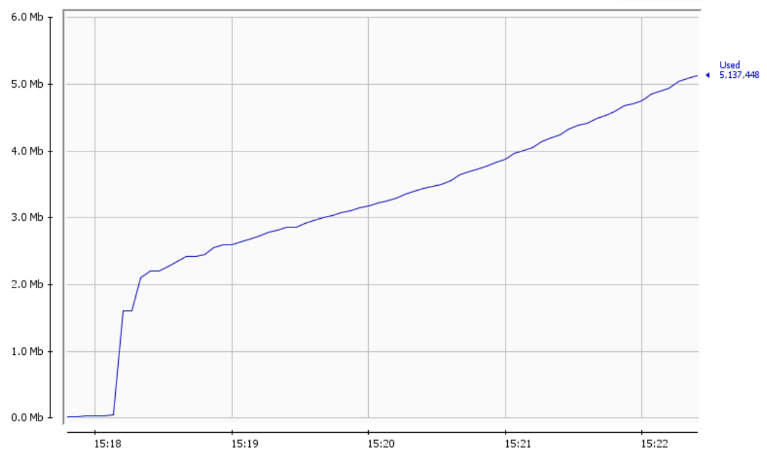
最近在开发一个小的C++项目,由于ASan比较便于在开发阶段帮助发现内存问题,所以在编译设置里默认都是打开的,它工作的很好,帮助团队发现了不少问题。
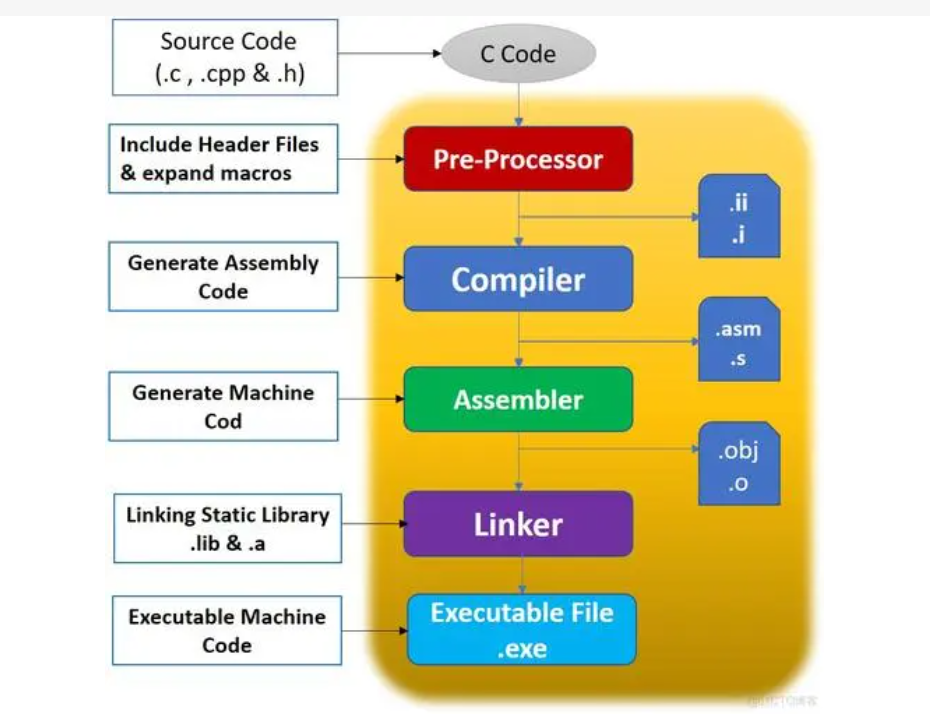
我们在编写C++程序时经常用到.so库,有外部的也有自己编写的,那么在程序编译后,如何查看可执行程序或动态库的依赖关系呢?有些项目启动时加载大量的.so库导致启动速度慢,如何便捷的清理已不使用的so文件呢?本文就给大家简单讲一下。

我们在编写C++框架时,经常会涉及到一项基础技术,就是根据“一个动态库 + 一个类名称字符串“,动态的创建类对象。

我们日常在定位C++的Core问题时,经常会遇到Core位置并非真实问题点的情况,在release无符号偶发场景下定位会更加困难。今天就通过一个问题场景,来讲解下如何通过IDA来进行此类问题的定位。

当一个类的成员函数里需要把当前类对象作为参数传给外部时(例如传递给异步线程),如何安全的的传递和释放将是一个棘手的问题,而C++11的enable_shared_from_this就是为此而设计的,本文就和大家一起来解析下。
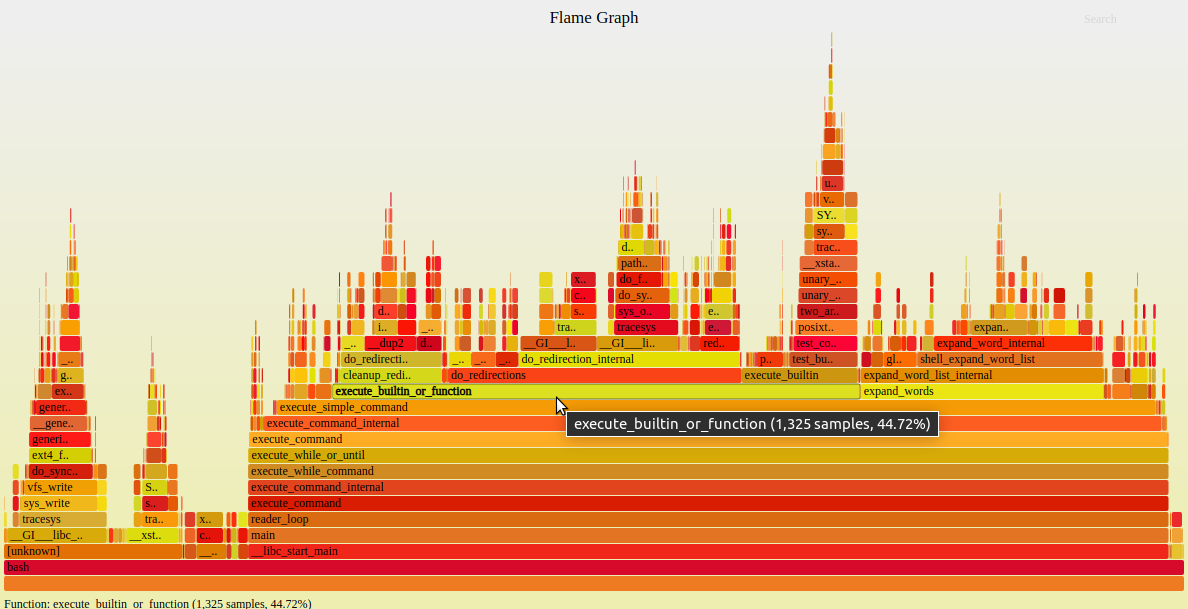
软件的性能分析,往往需要查看 CPU 耗时,了解瓶颈在哪里。perf和火焰图是性能分析的利器。本文主要介绍它们的基本用法。
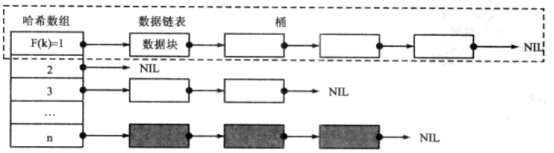
本文主要根据插入、遍历、删除、排序、查找等场景对常用数据结构进行性能分析。
在一些明确的场景下,程序员比CPU和编译器更了解哪个分支条件更有可能被满足。我们是否可将这一先验知识告知编译器和CPU, 提高分支预测的准确率,从而减少CPU流水线分支预测错误带来的性能损失呢?答案是可以!它便是likely和unlikely。在Linux内核代码中,这两个宏的应用比比皆是。下面是他们的定义:

gRPC是由 google开发的一款高性能开源远程过程调用(RPC)框架,主要面向高性能C/S模式应用场景,基于HTTP/2协议标准设计,支持常见的各类编程语言。
C++11中引入了mutex和方便优雅的lock_guard,但是有时候我们想要一个性能更高的实现方式,本文主要讲解如何使用C++11中的原子操作类atomic来巧妙地实现无锁同步。
C++多线程编程需要对共享的数据进行写保护,以防止多线程在对共享数据成员进行并发写时造成资源争抢而导致出现崩溃或其他不符合预期的结果。通常的做法是在修改共享数据成员前先对互斥锁mutex进行lock加锁,在修改后再进行unlock操作,这个场景中经常会出现由于疏忽或异常导致lock之后未能unlock,最终导致死锁。
static_pointer_cast从表面上看就是静态指针类型转换。细细看来,并不是那么简单,有一个隐形的限制条件。首先这个是c++11里的,更老的编译器不支持,其次指针是shared_ptr类型的,对于普通指针是无效的。还有一般只用在子类父类的继承关系中,当子类中要获取父类中的一些属性时,或工厂模式等需要通过父类参数接收不同子类实例的场景(当然了子类通过多态拥有自己的父类继承来的属性和行为,但是还想知道父类相应的属性和行为,这时,将父类的shared_ptr通过static_pointer_cast转化为子类的shared_ptr,这样就可以使得子类可以访问到父类的方法)。
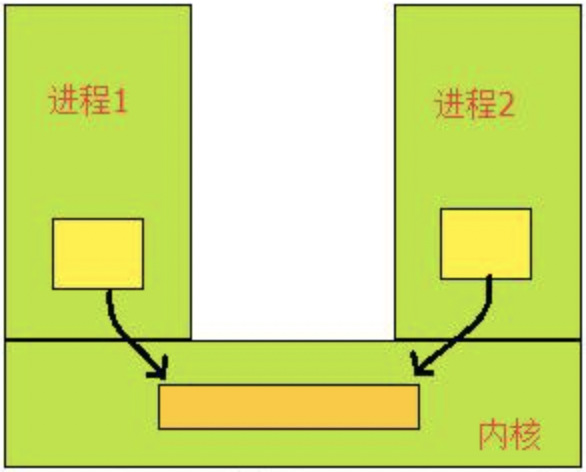
一个进程需要将它的数据发送给另一个进程;