本文主要根据插入、遍历、删除、排序、查找等场景对常用数据结构进行性能分析。
一、常用数据结构简介
1、数组
数组是最常用的一种线性表,对于静态的或者预先能确定大小的数据集合,采用数组进行存储是最佳选择。
数组的优点一是查找方便,利用下标即可立即定位到所需的数据节点;二是添加或删除元素时不会产生内存碎片;三是不需要考虑数据节点指针的存储。然而,数组作为一种静态数据结构,存在内存使用率低、可扩展性差的缺点。无论数组中实际有多少元素,编译器总会按照预先设定好的内存容量进行分配。如果超出边界,则需要建立新的数组。
2、链表
链表是另一种常用的线性表,一个链表就是一个由指针连接的数据链。每个数据节点由指针域和数据域构成,指针一般指向链表中的下一个节点,如果节点是链表中的最后一个,则指针为NULL。在双向链表(Double Linked List)中,指针域还包括一个指向上一个数据节点的指针。在跳转链表(Skip Linked List)中,指针域包含指向任意某个关联向的指针。
template <typename T>
class LinkedNode
{
public:
LinkedNode(const T& e): pNext(NULL), pPrev(NULL)
{
data = e;
}
LinkedNode<T>* Next()const
{
return pNext;
}
LinkedNode<T>* Prev()const
{
return pPrev;
}
private:
T data;
LinkedNode<T>* pNext;// 指向下一个数据节点的指针
LinkedNode<T>* pPrev;// 指向上一个数据节点的指针
LinkedNode<T>* pConnection;// 指向关联节点的指针
};与预先静态分配好存储空间的数组不同,链表的长度是可变的。只要内存空间足够,程序就能持续为链表插入新的数据项。数组中所有的数据项都被存放在一段连续的存储空间中,链表中的数据项会被随机分配到内存的某个位置。
3、哈希表
数组和链表有各自的优缺点,数组能够方便定位到任何数据项,但扩展性较差;链表则无法提供快捷的数据项定位,但插入和删除任意一个数据项都很简单。当需要处理大规模的数据集合时,通常需要将数组和链表的优点结合。通过结合数组和链表的优点,哈希表能够达到较好的扩展性和较高的访问效率。
虽然每个开发者都可以构建自己的哈希表,但哈希表都有共同的基本结构,如下:
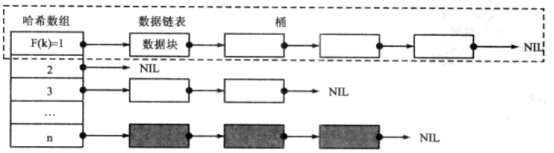
哈希数组中每个项都有指针指向一个小的链表,与某项相关的所有数据节点都会被存储在链表中。当程序需要访问某个数据节点时,不需要遍历整个哈希表,而是先找到数组中的项,然后查询子链表找到目标节点。每个子链表称为一个桶(Bucket),如何定位一个存储目标节点的桶,由数据节点的关键字域Key和哈希函数共同确定,虽然存在多种映射方法,但实现哈希函数最常用的方法还是除法映射。除法函数的形式如下:
F(k) = k % Dk是数据节点的关键字,D是预先设计的常量,F(k)是桶的序号(等同于哈希数组中每个项的下标),哈希表实现如下:
// 数据节点定义
template <class E, class Key>
class LinkNode
{
public:
LinkNode(const E& e, const Key& k): pNext(NULL), pPrev(NULL)
{
data = e;
key = k;
}
void setNextNode(LinkNode<E, Key>* next)
{
pNext = next;
}
LinkNode<E, Key>* Next()const
{
return pNext;
}
void setPrevNode(LinkNode<E, Key>* prev)
{
pPrev = prev;
}
LinkNode<E, Key>* Prev()const
{
return pPrev;
}
E& getData()const
{
return data;
}
Key& getKey()const
{
return key;
}
private:
// 指针域
LinkNode<E, Key>* pNext;
LinkNode<E, Key>* pPrev;
// 数据域
E data;// 数据
Key key;//关键字
};
// 哈希表定义
template <class E, class Key>
class HashTable
{
private:
typedef LinkNode<E, Key>* LinkNodePtr;
LinkNodePtr* hashArray;// 哈希数组
int size;// 哈希数组大小
public:
HashTable(int n = 100);
~HashTable();
bool Insert(const E& data);
bool Delete(const Key& k);
bool Search(const Key& k, E& ret)const;
private:
LinkNodePtr searchNode()const;
// 哈希函数
int HashFunc(const Key& k)
{
return k % size;
}
};
// 哈希表的构造函数
template <class E, class Key>
HashTable<E, Key>::HashTable(int n)
{
size = n;
hashArray = new LinkNodePtr[size];
memset(hashArray, 0, size * sizeof(LinkNodePtr));
}
// 哈希表的析构函数S
template <class E, class Key>
HashTable<E, Key>::~HashTable()
{
for(int i = 0; i < size; i++)
{
if(hashArray[i] != NULL)
{
// 释放每个桶的内存
LinkNodePtr p = hashArray[i];
while(p)
{
LinkNodePtr toDel = p;
p = p->Next();
delete toDel;
}
}
}
delete [] hashArray;
}分析代码,哈希函数决定了一个哈希表的效率和性能。
当F(k)=k时,哈希表中的每个桶仅有一个节点,哈希表是一个一维数组,虽然每个数据节点的指针会造成一定的内存空间浪费,但查找效率最高(时间复杂度O(1))。
当F(k)=c时,哈希表所有的节点存放在一个桶中,哈希表退化为链表,同时还加上一个多余的、基本为空的数组,查找一个节点的时间效率为O(n),效率最低。
因此,构建一个理想的哈希表需要尽可能的使用让数据节点分配更均匀的哈希函数,同时哈希表的数据结构也是影响其性能的一个重要因素。例如,桶的数量太少会造成巨大的链表,导致查找效率低下,太多的桶则会导致内存浪费。因此,在设计和实现哈希表前,需要分析数据节点的关键值,根据其分布来决定需要造多大的哈希数组和使用什么样的哈希函数。
哈希表的实现中,数据节点的组织方式多种多样,并不局限于链表,桶可以是一棵树,也可以是一个哈希表。
4、二叉树
二叉树是一种常用数据结构,开发人员通常熟知二叉查找树。在一棵二叉查找树中,所有节点的左子节点的关键值都小于等于本身,而右子节点的关键值大于等于本身。由于平衡二叉查找树与有序数组的折半查找算法原理相同,所以查询效率要远高于链表(O(Log2n)),而链表为O(n)。但由于树中每个节点都要保存两个指向子节点的指针,空间代价要远高于单向链表和数组,并且树中每个节点的内存分配是不连续的,导致内存碎片化。但二叉树在插入、删除以及查找等操作上的良好表现使其成为最常用的数据结构之一。二叉树的链表实现如下:
template <class T>
class TreeNode
{
public:
TreeNode(const TreeNode& e): left(NULL), right(NULL)
{
data = e;
}
TreeNode<T>* Left()const
{
return left;
}
TreeNode<T>* Right()const
{
return right;
}
private:
T data;
TreeNode<T>* left;
TreeNode<T>* right;
};
二、数据结构的遍历操作
1、数组的遍历
遍历数组的操作很简单,无论是顺序还是逆序都可以遍历数组,也可以任意位置开始遍历数组。
2、链表的遍历
跟踪指针便能完成链表的遍历:
LinkNode<E>* pNode = pFirst;
while(pNode)
{
pNode = pNode->Next();
// do something
}双向链表可以支持顺序和逆序遍历,跳转链表通过过滤某些无用节点可以实现快速遍历。
3、哈希表的遍历
如果预先知道所有节点的Key值,可以通过Key值和哈希函数找到每一个非空的桶,然后遍历桶的链表。否则只能通过遍历哈希数组的方式遍历每个桶。
for(int i = 0; i < size; i++)
{
LinkNodePtr pNode = hashArray[i];
while(pNode) != NULL)
{
// do something
pNode = pNode->Next();
}
}4、二叉树的遍历
遍历二叉树由三种方式:前序,中序,后序,三种遍历方式的递归实现如下:
// 前序遍历
template <class E>
void PreTraverse(TreeNode<E>* pNode)
{
if(pNode != NULL)
{
// do something
doSothing(pNode);
PreTraverse(pNode->Left());
PreTraverse(pNode->Right());
}
}
// 中序遍历
template <class E>
void InTraverse(TreeNode<E>* pNode)
{
if(pNode != NULL)
{
InTraverse(pNode->Left());
// do something
doSothing(pNode);
InTraverse(pNode->Right());
}
}
// 后序遍历
template <class E>
void PostTraverse(TreeNode<E>* pNode)
{
if(pNode != NULL)
{
PostTraverse(pNode->Left());
PostTraverse(pNode->Right());
// do something
doSothing(pNode);
}
}使用递归方式对二叉树进行遍历的缺点主要是随着树的深度增加,程序对函数栈空间的使用越来越多,由于栈空间的大小有限,递归方式遍历可能会导致内存耗尽。解决办法主要有两个:一是使用非递归算法实现前序、中序、后序遍历,即仿照递归算法执行时函数工作栈的变化状况,建立一个栈对当前遍历路径上的节点进行记录,根据栈顶元素是否存在左右节点的不同情况,决定下一步操作(将子节点入栈或当前节点退栈),从而完成二叉树的遍历;二是使用线索二叉树,即根据遍历规则,在每个叶子节点增加指向后续节点的指针。
三、数据结构的插入操作
1、数组的插入
由于数组中的所有数据节点都保存在连续的内存中,所以插入新的节点需要移动插入位置之后的所有节点以腾出空间,才能正确地将新节点复制到插入位置。如果恰好数组已满,还需要重新建立一个新的容量更大的数组,将原数组的所有节点拷贝到新数组,因此数组的插入操作与其它数据结构相比,时间复杂度更高。
如果向一个未满的数组插入节点,最好的情况是插入到数组的末尾,时间复杂度是O(1),最坏情况是插入到数组头部,需要移动数组的所有节点,时间复杂度是O(n)。
如果向一个满数组插入节点,通常做法是先创建一个更大的数组,然后将原数组的所有节点拷贝到新数组,同时插入新节点,最后删除元数组,时间复杂度为O(n)。在删除元数组之前,两个数组必须并存一段时间,空间开销较大。
2、链表的插入
在链表中插入一个新节点很简单,对于单链表只需要修改插入位置之前节点的pNext指针使其指向本节点,然后将本节点的pNext指针指向下一个节点即可(对于链表头不存在上一个节点,对于链表尾不存在下一个节点)。对于双向链表和跳转链表,需要修改相关节点的指针。链表的插入操作与长度无关,时间复杂度为O(1),当然链表的插入操作通常会伴随链表插入节点位置的定位,需要一定时间。
3、哈希表的插入
在哈希表中插入一个节点需要完成两部操作,定位桶并向链表插入节点。
template <class E, class Key>
bool HashTable<E, Key>::Insert(const E& data)
{
Key k = data;// 提取关键字
// 创建一个新节点
LinkNodePtr pNew = new LinkNodePtr(data, k);
int index = HashFunc(k);//定位桶
LinkNodePtr p = hashArray[index];
// 如果是空桶,直接插入
if(NULL == p)
{
hashArray[index] = pNew;
return true;
}
// 在表头插入节点
hashArray[index] = pNew;
pNew->SetNextNode(p);
p->SetPrevNode(pNew);
return true;
}哈希表插入操作的时间复杂度为O(1),如果桶的链表是有序的,需要花时间定位链表中插入的位置,如果链表长度为M,则时间复杂度为O(M)。
4、二叉树的插入
二叉树的结构直接影响插入操作的效率,对于平衡二叉查找树,插入节点的时间复杂度为O(Log2N)。对于非平衡二叉树,插入节点的时间复杂度比较高,在最坏情况下,非平衡二叉树所有的left节点都为NULL,二叉树退化为链表,插入节点新节点的时间复杂度为O(n)。
当节点数量很多时,对平衡二叉树中进行插入操作的效率要远高于非平衡二叉树。工程开发中,通常避免非平衡二叉树的出现,或是将非平衡二叉树转换为平衡二叉树。简单做法如下:
(1)中序遍历非平衡二叉树,在一个数组中保存所有的节点的指针。
(2)由于数组中所有元素都是有序排列的,可以使用折半查找遍历数组,自上而下逐层构建平衡二叉树。
四、数据结构的删除操作
1、数组的删除
从数组中删除节点,如果需要数组没有空洞,需要在删除节点后将其后所有节点向前移动。最坏情况下(删除首节点),时间复杂度为O(n),最好情况下(删除尾节点),时间复杂度为O(1)。
在某些场合(如动态数组),当删除完成后如果数组中存在大量空闲位置,则需要缩小数组,即创建一个较小的新数组,将原数组中所有节点拷贝到新数组,再将原数组删除。因此,会导致较大的空间与时间开销,应谨慎设置数组的大小,即要尽量避免内存空间的浪费也要减少数组的放大或缩小操作。通常,每当需要删除数组中的某个节点时,并不将其真正删除,而是在节点的位置设计一个标记位bDelete,将其设置为true,同时禁止其它程序使用本节点,待数组中需要删除的节点达到一定阈值时,再统一删除,避免多次移动节点操作,降低时间复杂度。
2、链表的删除
链表中删除节点的操作,直接将被删除节点的上一节点的指针指向被删除节点的下一节点即可,删除操作的时间复杂度是O(1)。
3、哈希表的删除
从哈希表中删除一个节点的操作如下:首先通过哈希函数和链表遍历(桶由链表实现)找到待删除节点,然后删除节点并重新设置前向和后向指针。如果被删除节点是桶的首节点,则将桶的头指针指向后续节点。
template <class E, class Key>
bool HashTable<E, Key>::Delete(const Key& k)
{
// 找到关键值匹配的节点
LinkNodePtr p = SearchNode(k);
if(NULL == p)
{
return false;
}
// 修改前向节点和后向节点的指针
LinkNodePtr pPrev = p->Prev();
if(pPrev)
{
LinkNodePtr pNext = p->Next();
if(pNext)
{
pNext->SetPrevNode(pPrev);
pPrev->SetNextNode(pNext);
}
else
{
// 如果前向节点为NULL,则当前节点p为首节点
// 修改哈希数组中的节点的指针,使其指向后向节点。
int index = HashFunc(k);
hashArray[index] = p->Next();
if(p->Next() != NULL)
{
p->Next()->SetPrevNode(NULL);
}
}
}
delete p;
return true;
}4、二叉树的删除
从二叉树删除一个节点需要根据情况讨论:
(1)如果节点是叶子节点,直接删除。
(2)如果删除节点仅有一个子节点,则将子节点替换被删除节点。
(3)如果删除节点的左右子节点都存在,由于每个子节点都可能有自己的子树,需要找到子树中合适的节点,并将其立为新的根节点,并整合两棵子树,重新加入到原二叉树。
五、数据结构的排序操作
1、数组的排序
数组的排序包括冒泡、选择、插入等排序方法。
template <typename T>
void Swap(T& a, T& b)
{
T temp;
temp = a;
a = b;
b = temp;
}冒泡排序实现:
template <typename T>
static void Bubble(T array[], int len, bool min2max = true)
{
bool exchange = true;
//遍历所有元素
for(int i = 0; (i < len) && exchange; i++)
{
exchange = false;
//将尾部元素与前面的每个元素作比较交换
for(int j = len - 1; j > i; j--)
{
if(min2max?(array[j] < array[j-1]):(array[j] > array[j-1]))
{
//交换元素位置
Swap(array[j], array[j-1]);
exchange = true;
}
}
}
}冒泡排序的时间复杂度为O(n^2),冒泡排序是稳定的排序方法。
选择排序实现:
template <typename T>
void Select(T array[], int len, bool min2max = true)
{
for(int i = 0; i < len; i++)
{
int min = i;//从第i个元素开始
//对待排序的元素进行比较
for(int j = i + 1; j < len; j++)
{
//按排序的方式选择比较方式
if(min2max?(array[min] > array[j]):(array[min] < array[j]))
{
min = j;
}
}
if(min != i)
{
//元素交换
Swap(array[i], array[min]);
}
}
}选择排序的时间复杂度为O(n^2),选择排序是不稳定的排序方法。
插入排序实现:
template <typename T>
void Select(T array[], int len, bool min2max = true)
{
for(int i = 0; i < len; i++)
{
int min = i;//从第i个元素开始
//对待排序的元素进行比较
for(int j = i + 1; j < len; j++)
{
//按排序的方式选择比较方式
if(min2max?(array[min] > array[j]):(array[min] < array[j]))
{
min = j;
}
}
if(min != i)
{
//元素交换
Swap(array[i], array[min]);
}
}
}插入排序的时间复杂度为O(n^2),插入排序是稳定的排序方法。
2、链表的排序
虽然链表在插入和删除操作上性能优越,但排序复杂度却很高,尤其是单向链表。由于链表中访问某个节点需要依赖其它节点,不能根据下标直接定位到任意一项,因此节点定位的时间复杂度为O(N),排序效率低下。
工程开发中,可以使用数组链表,当需要排序时构造一个数组,存放链表中每个节点的指针。在排序过程中通过数组定位每个节点,并实现节点的交换。
链表数组为直接访问链表的节点提供了便利,但是使用空间换时间的方法,如果希望得到一个有序链表,最好是在构建链表时将每个节点插入到合适的位置。
3、哈希表的排序
由于采用哈希函数访问每个桶,因此哈希表中对哈希数组排序毫无意义,但具体节点的定位需要通过查询每个桶链表完成(桶由链表实现),将桶的链表排序可以提高节点的查询效率。
4、二叉树的排序
对于二叉查找树,其本身是有序的,中序遍历可以得到二叉查找树有序的节点输出。对于未排序的二叉树,所有节点被随机组织,定位节点的时间复杂度为O(N)。
六、数据结构的查找操作
1、数组的查找
数组的最大优点是可以通过下标任意的访问节点,而不需要借助指针、索引或遍历,时间复杂度为O(1)。对于下标未知的情况查找节点,则只能遍历数组,时间复杂度为O(N)。对于有序数组,最好的查找算法是二分查找法。
template <class E>
int BinSearch(E array[], const E& value, int start, int end)
{
if(end - start < 0)
{
return INVALID_INPUT;
}
if(value == array[start])
{
return start;
}
if(value == array[end])
{
return end;
}
while(end > start + 1)
{
int temp = (end + start) / 2;
if(value == array[temp])
{
return temp;
}
if(array[temp] < value)
{
start = temp;
}
else
{
end = temp;
}
}
return -1;
}折半查找的时间复杂度是O(Log2N),与二叉树查询效率相同。
对于乱序数组,只能通过遍历方法查找节点,工程开发中通常设置一个标识变量保存更新节点的下标,执行查询时从标识变量标记的下标开始遍历数组,执行效率比从头开始要高。
2、链表的查找
对于单向链表,最差情况下需要遍历整个链表才能找到需要的节点,时间复杂度为O(N)。
对于有序链表,可以预先获取某些节点的数据,可以选择与目标数据最接近的一个节点查找,效率取决于已知节点在链表中的分布,对于双向有序链表效率会更高,如果正中节点已知,则查询的时间复杂度为O(N/2)。
对于跳转链表,如果预先能够根据链表中节点之间的关系建立指针关联,查询效率将大大提高。
3、哈希表的查找
哈希表中查询的效率与桶的数据结构有关。桶由链表实现,则查询效率和链表长度有关,时间复杂度为O(M)。查找算法实现如下:
template <class E, class Key>
bool HashTable<E, Key>::SearchNode(const Key& k)const
{
int index = HashFunc(k);
// 空桶,直接返回
if(NULL == hashArray[index])
return NULL;
// 遍历桶的链表,如果由匹配节点,直接返回。
LinkNodePtr p = hashArray[index];
while(p)
{
if(k == p->GetKey())
return p;
p = p->Next();
}
}4、二叉树的查找
在二叉树中查找节点与树的形状有关。对于平衡二叉树,查找效率为O(Log2N);对于完全不平衡的二叉树,查找效率为O(N);
工程开发中,通常需要构建尽量平衡的二叉树以提高查询效率,但平衡二叉树受插入、删除操作影响很大,插入或删除节点后需要调整二叉树的结构,通常,当二叉树的插入、删除操作很多时,不需要在每次插入、删除操作后都调整平衡度,而是在密集的查询操作前统一调整一次。
七、其他
在实际应用过程中,我们可以结合需求场景,选择合适的数据结构。更多的时候,我们会采用数据结构的组合,在满足需求的同时尽可能的提高运行性能。
摘自:
https://blog.csdn.net/A642960662/article/details/123029361
