全国SLAM技术论坛由中国图象图形学学会CSIG主办,每年举办一届,邀请学术界和企业届的专家围绕SLAM技术的研究、发展以及产业化应用作技术分享。本文整理自浙江大学刘勇教授在第二届全国SLAM技术论坛中的报告。
刘勇,浙江大学智能系统与控制研究所教授,浙江大学求是青年学者,浙江省“新世纪151人才工程”第二层次培养人员,担任浙江省机器换人专家组专家。承担NSFC-浙江两化融合联合基金、国家自然科学基金青年和面上项目、科技部863重点项目子课题、浙江省杰出青年基金、工信部重大专项等国家级省部级项目多项。获得浙江省自然科学奖2017(一等奖),科学进步奖2013(一等奖)。主要研究方向包括:智能机器人系统、机器人感知与视觉、深度学习、大数据分析,多传感器融合等。
多源融合SLAM-现状与挑战
SLAM的定义比较经典,它的核心就是一个状态估计问题,根据传感器观测到的数据以及一些实际的模型,如何对这两者进行结合来准确估计实际情况。这个问题虽然在数学模型上比较简单,但是在实际过程中会面临很多的挑战以及不如意的实际现象。
首先的一个挑战就是landmark在实际应用中的复杂性(由于环境的复杂性引起);其次,由于sensor的不同,也会存在一些其他的问题。具体来讲,在纹理少、四季天气变化、光照剧烈变化、车载条件IMU退化、长走廊、机器人剧烈运动等情况下,原来很好用的SLAM方法在这些情况下往往会无用。这都是很棘手的场景,这些场景会给我们带来实际应用中的困惑,采用单一的传感器会面临这个问题,所以多源融合这个领域很热门,被产业界所认可。

针对上述问题,我们使用多源融合的方法去克服复杂的场景,这些融合方法可以大致归结为三个类别:多传感器、多特征基元以及几何语义融合。
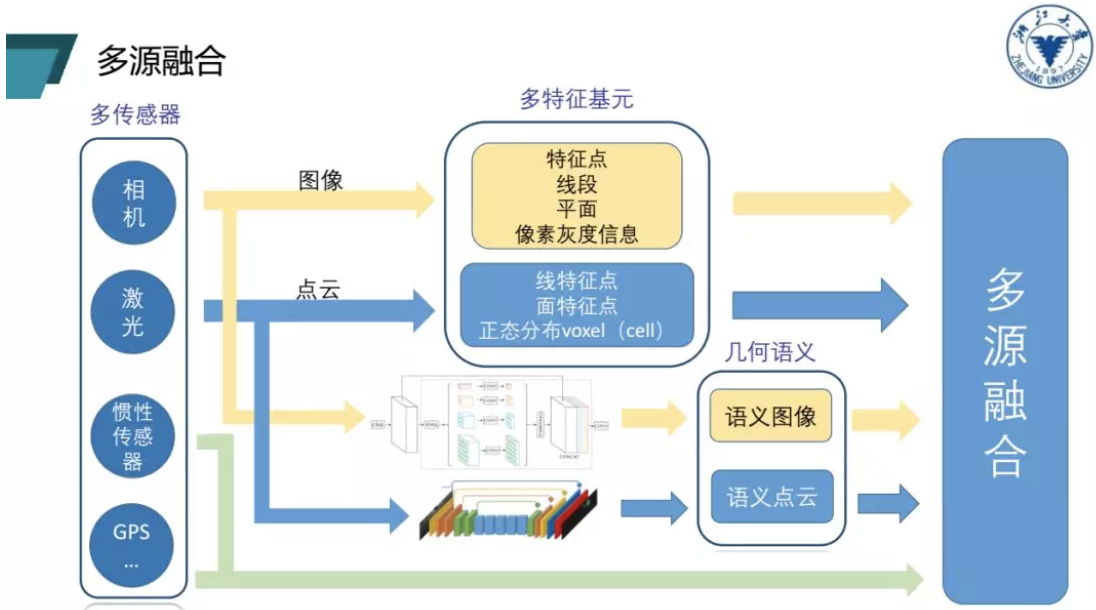
从多源融合框架图中可以看出,多源融合中第一个层面是多传感器的融合,比如激光或GPS。第二个层面是多特征基元的融合,我们可以通过对特征点、线段还有灰度信息这些特征进行提取,从而得到多个特征基元。使用激光之后还能够得到三维点云的线特征、面特征以及正态分布特征,这些都是我们做SLAM时经常会使用的特征。对相机和激光进行融合可以得到两个通道的信息,即图像和点云。现在的很多工作会将图像和点云信息直接输入到神经网络,这从某种层面上来说能够帮助我们提取语义信息。然后加上点云和图像的语义信息,就能够把几何和语义融合起来,这是对多源融合的宏观概括。
在进行融合之后我们会面临一些问题。
第一个问题就是多传感器融合之后,传感器间数据如何同步?外参关系如何标定?这些都是绕不开的问题。
第二个问题是在引入大量传感器之后,数据处理非常耗时,这与我们希望实现轻量级、快速响应且紧凑的SLAM系统相矛盾。而且传感器根据原理的不同,有些观测相互耦合,信息有一定的冗余,所以如何实现多个传感器之间的有效耦合也是我们面临的一个挑战。
第三个问题就是做多特征基元的融合,在做线、面特征提取时,这是很工程化而且很依赖技巧,目前没有特别好的方法能够把线面的特征做到特别的通用、鲁棒。在另外一个层面,当我们进行参数化或者数据关联时,如果使用很差的原始输入,会产生很多误差和干扰。除此之外,图像特征和激光特征如何进行提取?几何特征之间如何实现紧耦合,这都是进行多源耦合会面临的问题。
第四个问题就是怎么将语义信息融合到传统或者经典SLAM框架里,甚至能够像人一样地对语义进行认知。此外如何应用和集成图像语义和激光的语义信息,这也是非常有挑战性的问题。
介绍完以上挑战之后,报告接下来分享团队近两年做的一些工作。
一、多传感器的融合
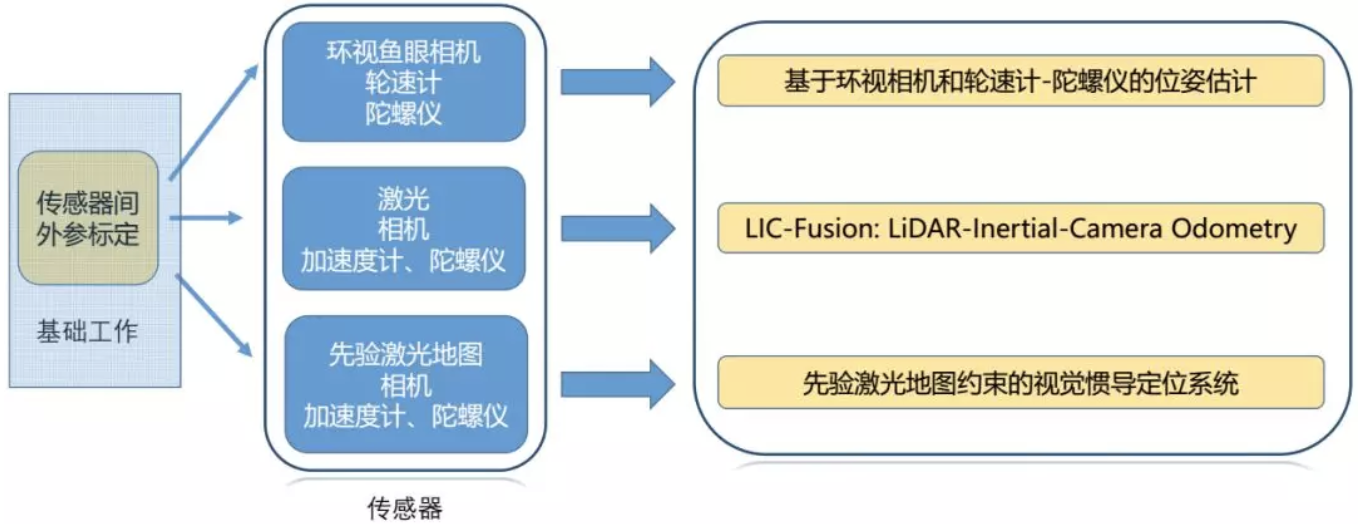
多传感器的融合能够帮助我们应对比较复杂的场景和环境,降低使用成本。首先,团队完成了传感器的标定工作,并且提出了环视鱼眼相机、轮速计陀螺仪融合方法,实现了基于环视相机和陀螺仪的融合估计。之后还完成了激光、相机、加速计和陀螺仪紧耦合的多传感器融合的里程计框架,叫LIC-Fusion。还完成了先验激光地图和相机、加速度计和陀螺仪所构成的定位系统。
基于环视相机和轮速计-陀螺仪的位姿估计
首先完成了环视鱼眼相机外参标定。先对相机视角进行划分,然后对棋盘格进行重投影,如果重投影重合,就可以间接地反应标定的精度。然后进行了激光相机外参标定,通过将图像数据和激光数据融合之后重新投到一个平面,能够比较准确地把线和边缘融合在一起。最后还完成了激光和IMU的融合,利用三面墙面,加上对IMU的轨迹做差时,实现了最佳标定结果。
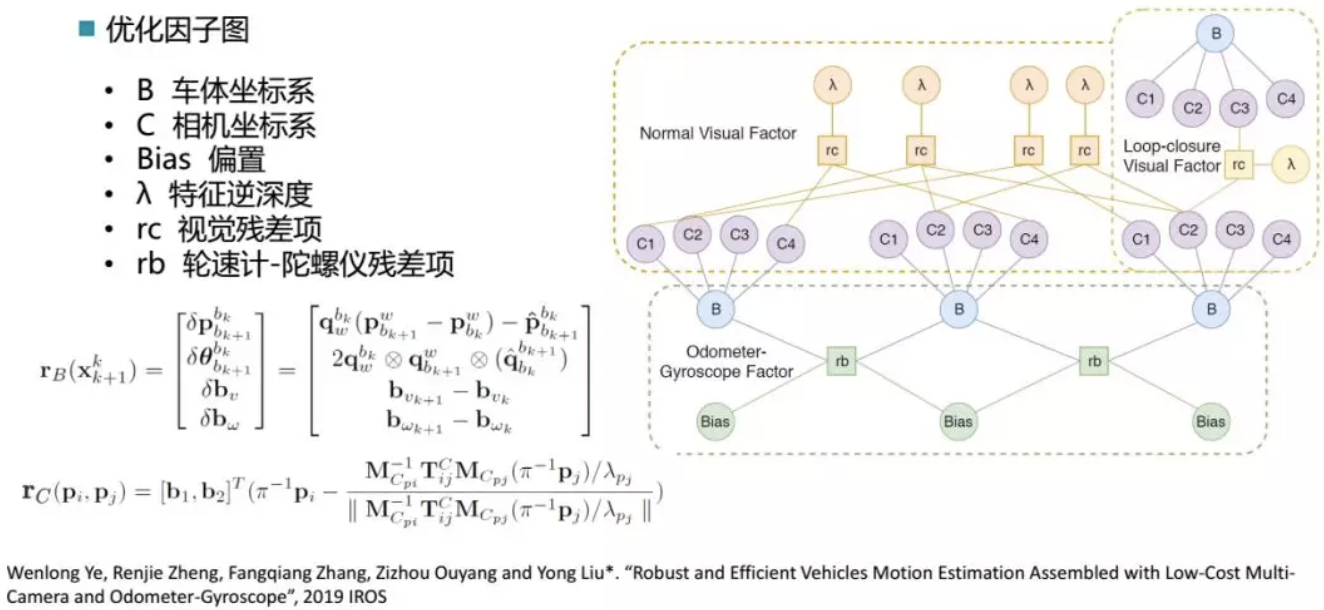
在完成传感器的标定这一基础工作之后,第二个工作是基于环视相机和轮速计-陀螺仪的位姿估计。在汽车移动模型中,VINS会面临很大的挑战,即退化的问题,准确来讲,由于在Z方向上(纵向)是没有任何的运动,会导致在这个方向上缺乏激励,在这种情况下,得到的VINS结果是比较差的。这也是自动停车系统仅仅依赖一个VINS效果并不理想的原因。这个时候会引入汽车的里程计信息,汽车在比较平整的路面上行驶的时候,它的里程计相对比较精确,然后我们可以把这个测量值引入进来,完成整体的运行。我们由此解决了车载环境下VIO姿态轨迹退化问题,实现了一个基于多目视觉的鲁棒定位。
LIC-Fusion:LiDAR-Inertial-Camera Odometry
这个面向的应用是多源融合在剧烈运动、轨迹退化等场景下的情况。团队用紧耦合、单线程的轻量级激光-惯导-相机定位方法,在任意两个传感器之间进行在线的空间和时间的标定,最终可以做到不需要任何的迭代最近点或迭代优化步骤来实现比较紧凑的计算资源。
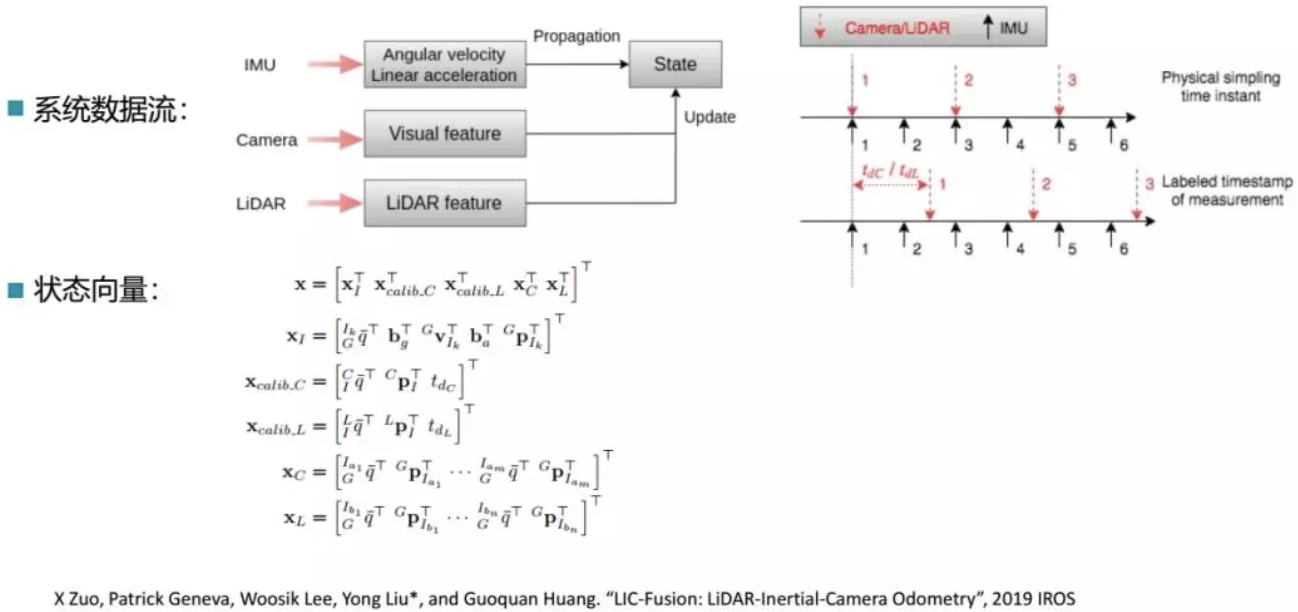
整个系统的流程图如上图所示,可以看到相机和雷达之间的状态做耦合更新,另外考虑了时间和周期上的差异性。该方法在室外场景和室内场景均进行了验证,相机轨迹均能较为准确地进行估计。
先验激光地图约束的视觉惯导定位系统
该工作假定多个传感器的信息是融合的,需要做到一个轻量级的视觉惯性定位系统。我们会利用前面先验的雷达数据建的图,作为一个约束来实现多模的传感。在线的使用雷达和VINS,成本相对较低,然后通过地图来提供约束,抑制漂移。该工作和Vins-Mono在一些benchmark上也进行了对比。
二、多特征的基元融合
这部分的核心问题是如何将多个特征较好地嵌入到SLAM框架中,即如何对特征进行表示并放入优化框架中。这方面主要做了以下两个工作:
基于点线特征的鲁棒视觉SLAM
该方法的核心思想就是对直线的参数化使用不同的方法。这里引入了两种直线的参数化方法,一种是普吕克坐标系的空间参数化方法,一种是正交表示的参数化方法。两者的应用有所区别,一种是为了在提取直线的时候能够比较好地进行表示,但是它是一个四自由度的表示,如果放在状态方程里由于多了一个自由度,会对状态方程的迭代过程不够友好。所以团队在优化过程中,将它转换到一个三自由度的正交表示的空间,再进行优化,这样的话可以保证自由度是比较接近需要待优化的空间的。同时也对前端进行了一些改进,使结果能够更连续更好。
基于特征点与光流结合的鲁棒双目SLAM系统
该工作能够解决DSO在大基线运动下的精度不高问题,同时可以改进光度标定,提高对光照变化的鲁棒性。该工作的本质想法是利用特征点法在比较大的基线下的稳健性和鲁棒性来改进DSO的缺陷,同时对在线光度的测量进行了改进,利用特征点在线估计相机每一帧的曝光时间,然后优化相机响应参数,这样可以对光度做得更鲁棒,实现更好的在线光度标定,最后能够得到比较好的结果,在一些光照可能不强的情况下可以正常跑出来。
三、几何语义融合
报告也介绍了团队近期主要聚焦的几何语义融合工作,也即如何把语义信息集成到经典的SLAM框架。下面将分别介绍三块工作。
精确快速的3D点云语义分割
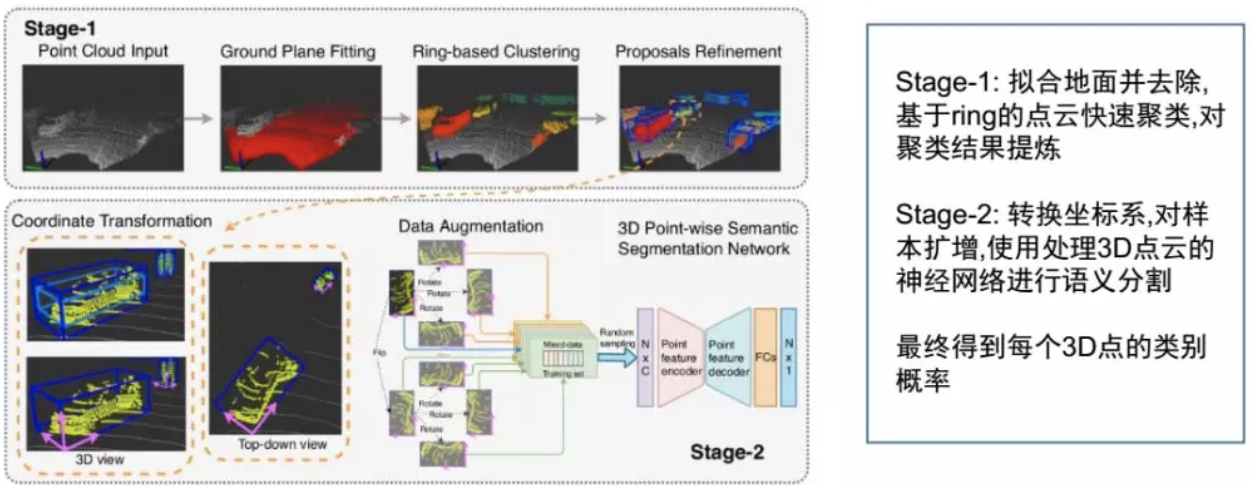
传统的点云分割没有语义输出,而映射到2D的方法会损失信息,直接在3D语义里做计算量很大。因此,团队做了两个阶段的工作来避免以上问题,基本思路是第一阶段做快速的分割,把比较好的点云簇提取出来;第二阶段设计了一个端到端的方案来较好地实现对数据的扩增,然后直接去对点进行分割。
第一阶段直接做一个地面拟合去除之后,做基于ring的点云快速聚类,对聚类结果做提炼,这个工作是轻量级的,能够比较快速完成。第二个阶段就是把每个点云簇计算之后换算到点云的坐标系,然后把点云簇放到设计的网络里做3D语义分割,这样可以得到每个点所隶属于某个类别的概率,实际上就是把传统的点云聚类方法和现在比较流行的end-to-end方案比较好地结合起来。这样做的好处在于,相对于传统的快速分割聚类算法,我们只需要少量的运算就可以得到高质量的聚类分割结果。另外在3D空间处理神经网络,有利于做并行化,即使继续进行优化,也可以在GPU里面做并行化处理,做完分割之后,所有的分类处理,可以并行化地在多路里去做,这样能够达到非常高的效率。
融合局部刚性的无监督场景流估计
场景流包括了运动信息、光流信息,这些信息混合在一起称之为sceneflow。现在比较多的工作在有监督方法上做得很好,但是有监督方法最大的问题在于需要大量的数据标注。我们想通过无监督学习来处理现实中的光流和深度的获取问题,通过无监督的方法来恢复光流和深度信息。传统的无监督方案一个很大的假设在于,要求光度是一致的,而且有平滑正则的约束,这两个假设对场景中有动态目标时会遇到非常大的挑战。因此团队提出的方案是相机自运动的网络,来估计光流和深度之间的关系。这里可以分成两个场景,一个是刚体流,另一种是非刚性流。当场景中有一些运动物体,对于运动物体,做深度恢复或者光流的估计,这些信息没有正向作用,因此需要进行剔除。这个时候把相机的运动和物体运动进行分离,能够使得输出在全局上更加合理。
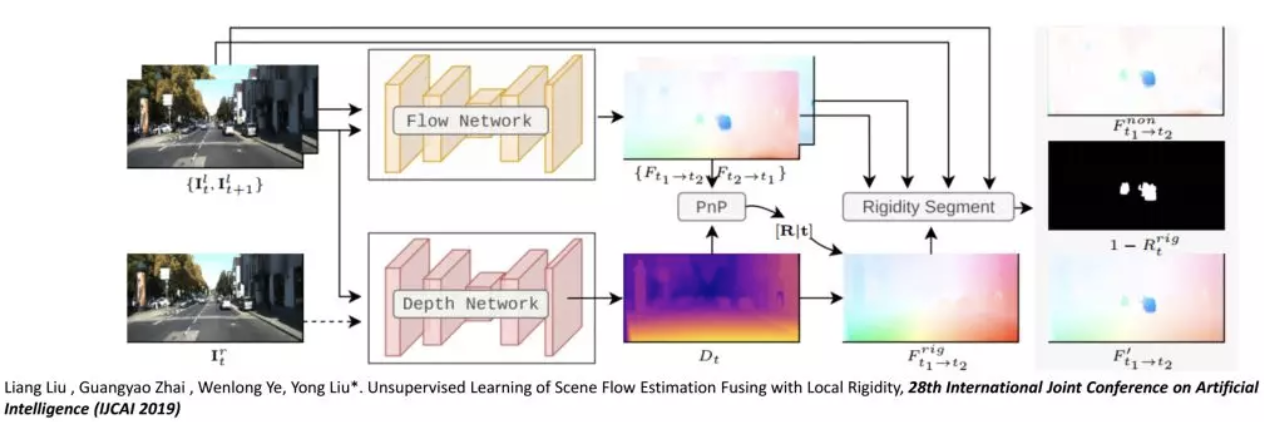
对于整个的网络训练,会先训练单独的光流网络和深度估计网络。从图中可以看到有两条网络,一条叫flow network,这条是对整个光流的估计网络,另外是对深度的估计网络,两者估计完成之后,中间引入了PNP的方法,来估算R和t关系。有了这些信息之后网络右侧把场景中的动态目标比较显著的提取出来,这个提取之后可以选择具体做场景流估算,以及应该为哪块地方获取置信度,由这个进一步生成置信度的map。然后可以把物体的相机和物体的运动进行分离,实现多任务联合训练的精度的提升。该工作在数据上已经做到对整个光流估算在目前最好的性能。
纹理与几何信息融合的稠密深度恢复
很多的深度传感器,比如激光,一个很大的问题在于它并不是稠密的深度恢复,即使使用64线或者128线,得到的也是稀疏的采样点。也有一些其他的深度传感器,如Kinect或Intel RealSense,很大的问题在于仅能在室内使用,而且测距的depth信息并不准确。另外像双目或多目相机,利用立体视觉做场景的恢复,但是恢复的质量并不是特别高,而且存在比较多的空洞信息。由于单目视觉的二义性,即尺度的不确定性,我们考虑把单目和比较稀疏的深度观测两者结合起来,从单张图像来恢复深度。我们用了一个几何测量值,从图像的纹理中去做一个联合的深度的恢复。
考虑端到端的方法,将图像和稀疏观测联合起来,来得到一个输入对。图像数据可以很容易地输入到卷积网络中,但是单线激光数据如何进行处理?这里团队从稀疏观测来重构稠密观测的参考深度值:由于激光只扫描一条线,但是图像观测是一个垂直面,所以先把线重构成面,把它扩增到整个图像上,这样就可以得到稠密的参考深度。在这个基础上把能够进行卷积从而进一步对这两个channel的信息进行结合并进行统一的表示。由于需要恢复深度,现在需要估算的值并不直接估算,而是考虑激光观测的mask和实际需要估测的深度叠加之后的叠加值,恢复这个值之后再把mask减掉,然后就可以得到真实场景的深度。
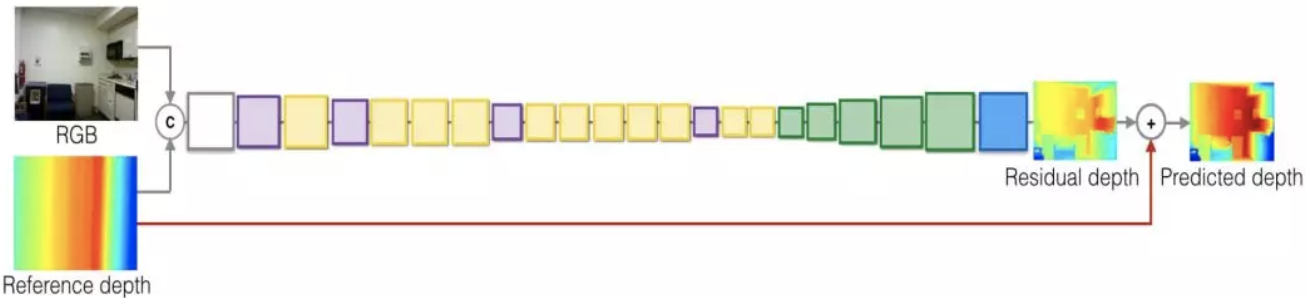
上图是完整的网络结构的设计,RGB的图像输入加上稀疏观测得到的参考深度,两者融合之后中间用残差网络方案进行的连接,然后完成这样的设计。这里有一些细节需要注意,一个是代价函数设计有几项,如果变成回归问题非常困难,做回归运算会有很大的困难。首先做离散化,变成分类误差会好一点,另外可以通过引入回归误差来提升精度,通过约束的深度跟估计期望值的一致性来弥补训练精度。通过这两个可以得到比较精准的深度值,这样可以把连续深度值的估计问题变成概率估计问题。方法在NYUD2数据集上进行了对比,从室内场景可以看到弥补的误差结果,和现有的结果相比已经取得了非常不错的结果除此以外场景的二义性能够得到缓解,可以比较好地恢复出有歧义的深度区域。
报告相关参考文献如下:
[1] Xingxing Zuo, Wenlong Ye, YulinYang, Renjie Zheng, Teresa Vidal‐Calleja, Guoquan Huang, Yong Liu*. Multimodal localization: Stereo over LiDAR map. Journal of Field Robotics, 2020. https://doi.org/10.1002/rob.21936
[2] Yong Liu*, Rong Xiong, Yue Wang, Hong Huang, Xiaojia Xie, XiaofengLiu, Gaoming Zhang. Stereo Visual-Inertial Odometry with Multiple Kalman Filters Ensemble. IEEE Transactions on Industrial Electronics, 2016, 63(10): 6205- 6216.
[3] Xingxing Zuo, Patrick Geneva, Yulin Yang, Wenlong Ye, Yong Liu*, Guoquan Huang. Visual-Inertial Localization with Prior LiDAR Map Constraints, IEEE Robotics and Automation Letters, 2019, 4(4): 3394-3401.
[4] Liang Liu, Guangyao Zhai, Wenlong Ye, Yong Liu*. Unsupervised Learning of Scene Flow Estimation Fusing with Local Rigidity, 28th International Joint Conference on Artificial Intelligence (IJCAI 2019).
[5] Xingxing Zuo, Patrick Geneva, Woosik Lee, Yong Liu*, and Guoquan Huang. LIC-Fusion: LiDAR-Inertial-Camera Odometry, 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
[6] Wenlong Ye, Renjie Zheng, Fangqiang Zhang, Zizhou Ouyang, Yong Liu*. Robust and Efficient Vehicles Motion Estimation Ensembled with Low-Cost Multi-Camera and Odometer-Gyroscope, 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
[7] Xin Kong, Guangyao Zhai, Baoquan Zhong, Yong Liu*. PASS3D: Precise and Accelerated Semantic Segmentationfor 3D Point Cloud, 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
[8] Xiangrui Zhao, Renjie Zheng, Wenlong Ye, Yong Liu*. A Robust Stereo Semi-direct SLAM System Based on Hybrid Pyramid, 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
[9] Xingxing Zuo, Xiaojia Xie, YongLiu*, Guoquan Huang. Robust visual SLAM with point and line features, 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24-28 Sept. 2017.
[10] Mengmeng Wang, Yong Liu*, ZeyiHuang. Large Margin Object Tracking with Circulant Feature Maps, 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, Hawaii, July22-25, 2017.
[11] Yiyi Liao, Lichao Huang, YueWang, Sarath Kodagoda, Yinan Yu, Yong Liu*. Parse Geometry from a Line: Monocular Depth Estimation with Partial Laser Observation, 2017 IEEE International Conference on Robotics & Automation (ICRA), Singapore, May 29-June3, 2017.
摘自:https://mp.weixin.qq.com/s/mdWS4_BDKLhho8mkblxAeg
