上次介绍了《如何搭建高可用Web集群》,有不少同学反馈让我继续发些高可用相关的内容。本文将继续高可用系列内容,介绍一下SRE和架构师角度对『实现高可用性』的理解。
一、概述
可用性案例
在开始之前,先给大家看下可用性的badcase案例:
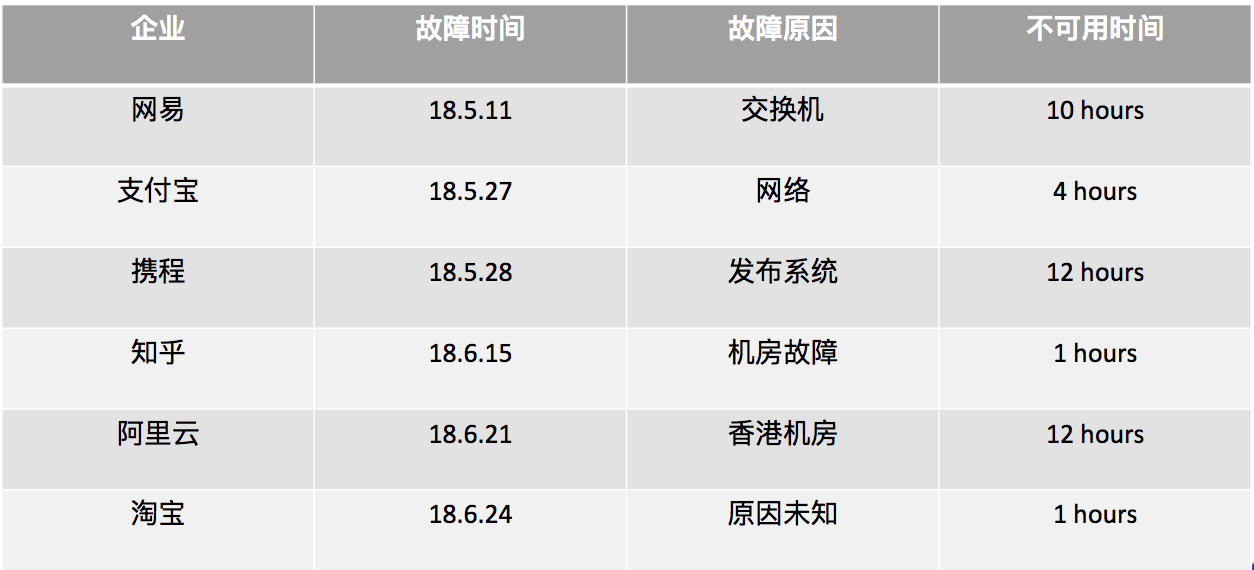
可用性问题后果
- 用户损失
–用户体验伤害
–经济损失
- 公司损失
–经济损失
–客户信任
–技术形象
本文探讨范围
- 以请求访问型的用户产品为示例
–用户产品
–平台化产品
–内部系统
- 目录
–高可用性定义
–如何度量
–影响要素分析
–如何保障
二、高可用性定义
可用性等级(Availability)定义
Availability = Uptime / (Uptime + Downtime)
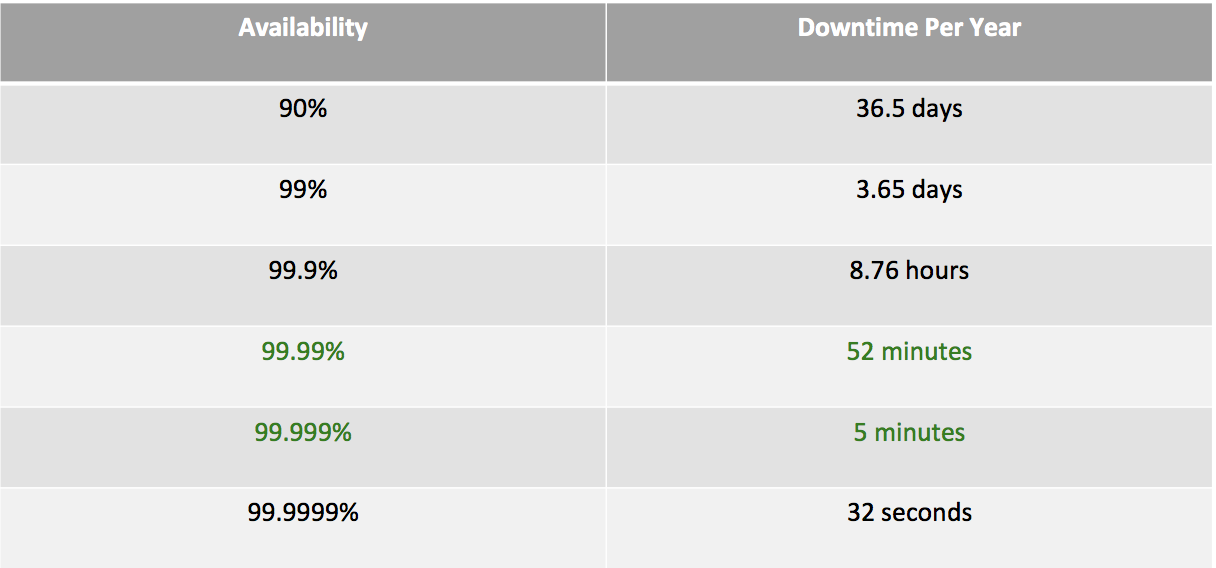
通常情况下,Availability达到99.99%或99.999%即可称为服务具备高可用性。
从用户角度出发
- 对于提供的服务,用户能够获得符合质量预期的服务比例
- 不可用
–不可访问
–DNS解析失败、链接失败
–服务不存在,或被封禁
–服务内部错误
–低质
–慢,页面错乱、核心元素缺失
相关名词
- SLA
–服务可用性等级,常说的几个九
- MTTR
–平均故障恢复时间,即从故障发现到止损点的时间差
- MTBF
–平均故障间隔时间,即从上一次故障到本次故障的间隔时间,常用于硬件产品
三、如何度量
困难
- 部分Down
–部分功能:子系统、页面、元素等
–部分用户
–间歇性:时间难以衡量
- 一个指标
–不同功能、用户是否一视同仁?
–浏览 vs 购买 vs 优惠卷
- 服务端指标 到 用户端 的“漫漫长路”
–服务端指标 vs 用户实际感受指标
–难以全面采集(端支持)
计算方法
- 时间 => 请求计数
–有效处理的请求次数 / 总合法的请求次数
- 用户指标 << 服务指标 << 模块指标 << 详细指标
–用户指标反映用户实际感受质量
–服务指标反映服务综合质量
–细分加权求和
–分功能指标反应模块服务质量
–详细指标有助于发现和定位问题
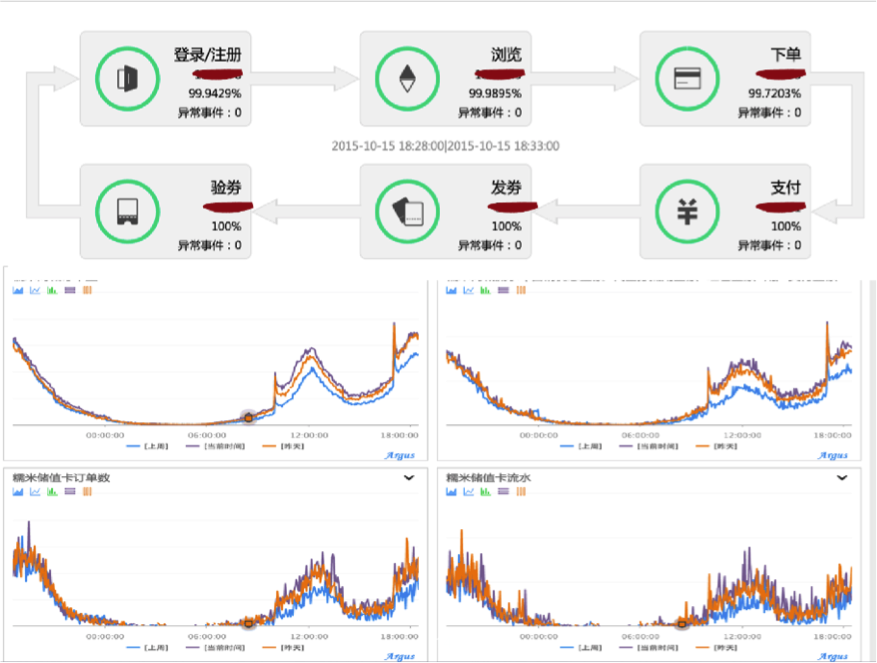
- SLA
–服务可用性等级,常说的几个九
–计算公式:1 –(失败次数 + 超时次数)/ 总请求次数
- MTTR
–平均故障恢复时间,即从故障发现到止损点的时间差
–计算公式:(故障恢复时间点 – 故障发生时间点) / 故障次数 * 模块重要性权重 * 模块流量权重
- MTBF
–平均故障间隔时间,即从上一次故障到本次故障的间隔时间,常用于硬件产品
–计算公式:(服务总可用时间-服务总故障时间) / 总故障次数
相关度量
- 关联其他指标
–服务容量
–流量:QPS
–性能:平响
–收入
- 关注变化
–变更
- 设置预警
–报警策略
四、影响要素分析
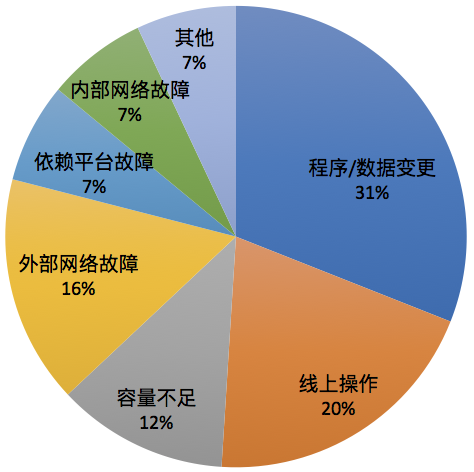
故障分布
下图是一个常见的服务故障分布情况:
故障时间
- 计划中的” Downtime”
–非兼容性升级
–数据一致性处理
–故障演练
- 故障(Failure)导致的” Downtime”
故障位置
- 硬件故障
–机器(含机器的各组成部分,如磁盘)
–IDC设施:交换机、链路、空调、电力等
–外部设施:运营商网络
- 软件缺陷
–代码BUG
–异常应对能力
故障触发
- 外部操作变更
–硬件及系统、网络
–软件:程序、配置、数据
- 外部流量因素引发的软件故障
–漏洞请求引发:特殊请求导致系统变慢、崩溃
–请求量、频次及构成引发:超出容量
五、如何保障
原则
- 减少发生
–降低故障出现频次
- 降低影响
–一旦发生,确保尽可能小的影响面
- 加快恢复
–能够快速发现、定位、修复
方法
变更控制
- 架构环节
–Design for Failures
–单机故障
–机房/区域故障
–流量异常
–自身异常
–下游异常
–清晰的服务部署
–避免单点
–消除跨逻辑机房的交互
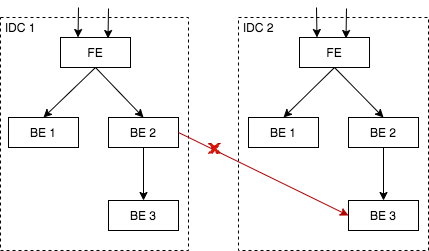
–合理的容量评估
–模块承担容量限额
–Cache崩溃对流量的影响
–第三方容量
–安全设计
- 编码环节
–严谨的编码,主动容错
–主动容错:函数执行失败、RPC调用失败、经过推敲的错误处理(任何一个函数、外部输入)
–超时控制
–使用NS名字服务
–重试的考虑:链路连锁反应,重试雪崩(容量计算/重试位置)
–模块隔离:高内聚、低耦合
–代码性能、安全性、可测性
–全分支覆盖自测;CodeReview
- 测试环节
–功能/性能/稳定性/兼容性/安全性测试
–交付确定性
- 上线环节
分级发布、回归测试
快速回滚
重视数据变更的风险
服务容量管理
- 服务冗余
–实例N+2
–支持熔灾 + 发布时摘流量
- 容量评估
–合理评估
–适当降低冗余
- 容量压测
–建立例行压测机制,定期获取系统容量瓶颈
–容量管理:根据流量合理部署实例,实现实例分配最优化
入口流量调度
- 能力
–流量的接入与调度能力
–粒度 && 速度
–限流:屏蔽与限制能力
–上下游的流量分配协调
–服务流量IDC调度 >> DB IDC流量激增
- 场景
–机房规模的故障
–接入故障、骨干网故障
–攻击
服务降级
- 先分级
–功能分级,开关
–区分核心功能
–流量分级,调度
–区分流量的相互影响
–区分流量的价值
- 分级场景
–服务过载:超出处理能力
–全局流量增加
–部分用户流量增加
–容量降低
–服务的子组件整体故障
–依赖的第三方服务整体崩溃
- 再降级
–功能降级
–丢弃非核心功能
–质量降级(减少计算)
–降低服务质量
–流量降级
–丢弃非核心流量
–配额
- 降级实例
–微信红包,异步延迟对账事物
–地图,基础地图功能,优先于动态路况
快速回滚
- 做好灾难恢复
–可恢复性
–备份的有效性
–恢复速度
- PaaS化
–故障自动发现,NS自动摘除
–分级发布
–一键回滚
- 自运维规范化
–备份与回滚
预案与演练
- 预案
–把预案内容转换为系统的设计和实现
–优先从系统设计和实现角度保证可用性
- 定期演练
–制造真实故障
监控报警
- 有效的指标
–整体及细分可用性
–核心业务指标
–程序指标
–依赖指标
- 回答如下问题
–会发生问题吗?
–发生问题了吗?
–哪里发生了问题?
–发生了什么问题?
–会自动恢复吗?
其他事项—可用性CheckList
- 感知
–服务关键指标
–关键依赖指标
- 隔离
–逻辑服务单元拆分
–单点消除
–核心功能逻辑独立
–核心服务资源优先
–流量成分的细分
–线上线下隔离
–容量规划
–关联解耦
–外部依赖消除
–分级发布
–变更流程规范
- 止损
–配置热加载
–快速回滚
–防攻击
–单机容错
–过载保护
–服务单元级流量调度
–服务降级
总结
- 建立对变更的控制能力(减少发生)
–架构、编码、测试、上线
- 建立对系统的控制能力(降低影响,加快恢复)
–容量管理、隔离、入口流量调度、服务降级、回滚
- 建立故障模型(减少发生,降低影响,加快恢复)
–考虑每一种可能出现的故障,以及是否都能够自动或手动应对
- 建立度量和监控(快速发现)
–对系统运转指标有清晰的度量和检测
yan 19.12.19
