C++带有线程操作,异步操作,就是没有线程池。一般而言,当你的函数需要在多线程中运行,但是你又不能每来一个函数就开启一个线程,所以你就需要根据资源情况固定几个线程来执行,但会出现有的线程还没有执行完,有的又在空闲,如何分配任务呢?这时你就需要封装一个线程池来完成这些操作,有了线程池这层封装,你就只需要告诉它开启几个线程,然后直接往里塞任务就行,并通过一定的机制获取执行结果。
C++线程池ThreadPool实现解析
发表评论
C++带有线程操作,异步操作,就是没有线程池。一般而言,当你的函数需要在多线程中运行,但是你又不能每来一个函数就开启一个线程,所以你就需要根据资源情况固定几个线程来执行,但会出现有的线程还没有执行完,有的又在空闲,如何分配任务呢?这时你就需要封装一个线程池来完成这些操作,有了线程池这层封装,你就只需要告诉它开启几个线程,然后直接往里塞任务就行,并通过一定的机制获取执行结果。
智能指针:智能指针是一个类,用来存储指针(指向动态分配对象也就是堆中对象的的指针)。
简单理解下:

内存管理是C++最令人切齿痛恨的问题,也是C++最有争议的问题,C++高手从中获得了更好的性能,更大的自由,C++菜鸟的收获则是一遍一遍的检查代码和对C++的痛恨,但内存管理在C++中无处不在,内存泄漏几乎在每个C++程序中都会发生,因此要想成为C++高手,内存管理一关是必须要过的,除非放弃C++,转到Java或者C#,他们的内存管理基本是自动的,当然你也放弃了自由和对内存的支配权,还放弃了C++超绝的性能。本期专题将从内存管理、内存泄漏、内存回收这三个方面来探讨C++内存管理问题。
1.CMake编译原理
在C++多线程编程中,开发者往往使用cout来打印一些信息,但是往往被人忽略的是,cout在使用时可能会存在线程之间的打印信息乱串的问题,这个问题的原因是”<<“这个操作符是线程不安全的,会造成竞争问题,当采用多个<<拼接时,打印可能在<<时中断,例如下边的写法:

Linux开发者越来越多,但是仍然有很多人整不明白POSIX是什么。本文就带着大家来了解一下到底什么是POSIX,了解他的历史和重要性。
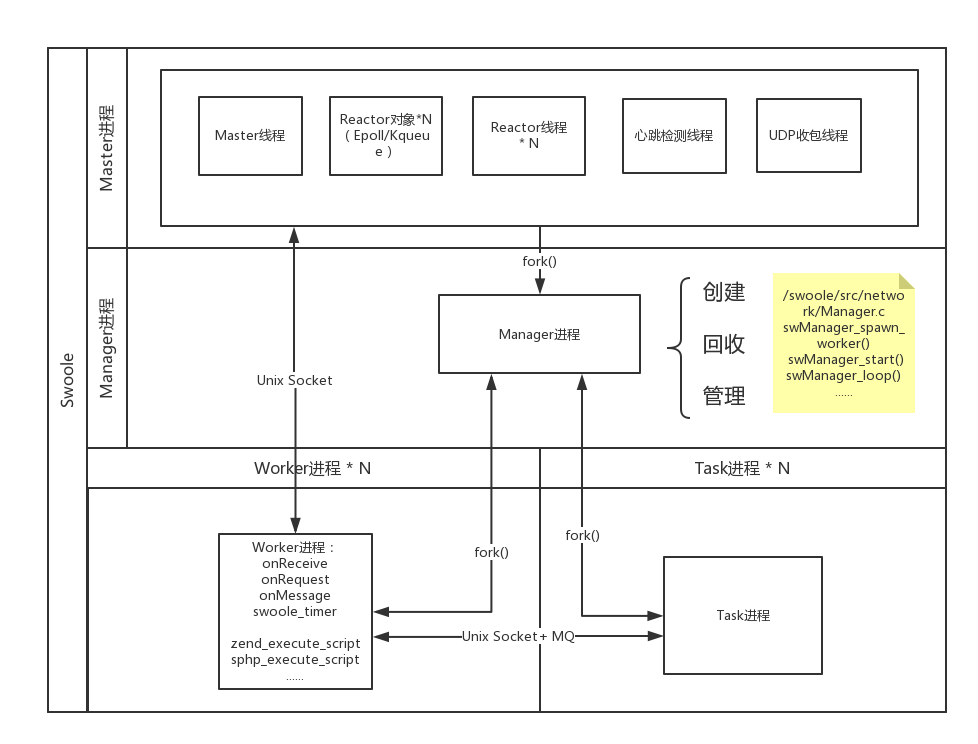
Swoole是一个为PHP用C和C++编写的基于事件的高性能异步&协程并行网络通信引擎。设计思路类似nginx(Reactor)+ php-fpm(Worker)。可以创建TCP,Websocket长链接服务,轻松承载上万长连接请求。
1.编写一个简单的c .so

PHP是当前应用非常广泛的一门语言,从国外的Facebook、Twitter到国内的淘宝、腾讯、百度等都能见到它的身影。
go的import与python或java不太一样,第一次搞go开发在本地封装lib后import时可能会浪费不少时间,这里说明下,go的import分两种场景:
问题:
当我们使用 go get、go install、go mod 等命令时,会自动下载相应的包或依赖包。但由于众所周知的原因,类似于 golang.org/x/… 的包会出现下载失败的情况。如下所示:
本文用实例演示如何把自己的python代码库打包上传pypi,以使用pip进行安装。
使用c++开发程序时,经常会遇到运行中core的情况,如果是偶发的就更加难以定位,本文讲解如何使用gdb进行core位置的分析定位。
jupyter notebook里的代码有py2.7也有py3.0的,本文讲解如何使jupyter同时支持多个python版本(python2.7.5 + python3.6.2)。
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
skimage即是Scikit-Image。基于python脚本语言开发的数字图片处理包,比如PIL,Pillow, opencv, scikit-image等。 PIL和Pillow只提供最基础的数字图像处理,功能有限;opencv实际上是一个c++库,只是提供了python接口,更新速度非常慢。scikit-image是基于scipy的一款图像处理包,它将图片作为numpy数组进行处理,与matlab一样。
PHP7已经发布, 如承诺, 我也要开始这个系列的文章的编写, 主要想通过文章让大家理解到PHP7的巨大性能提升背后到底我们做了什么, 今天我想先和大家聊聊zval的变化.
上次我们进行了简单的环境安装和模型应用尝试,今天开始通过paddlepaddle的房价预测看一下简单的线性回归有监督模型是怎么训练出来的。
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。在本文中,我们将介绍 Jupyter notebook 的主要特性,以及为什么对于希望编写漂亮的交互式文档的人来说是一个强大工具。