最近在研究视频二维码定位清理,涉及到Object Detection对象检测技术,发现Darknet用起来效果不错,本文简单介绍下。先贴几个示例:
儿子比赛视频中的普通目标识别:

自动检测清理视频中的二维码:


概述
Darknet深度学习框架是由Joseph Redmon提出的一个用C和CUDA编写的开源神经网络框架。它安装速度快,易于安装,并支持CPU和GPU计算。
GitHub:https://github.com/pjreddie/darknet
官网:https://pjreddie.com/darknet/
如何安装:https://pjreddie.com/darknet/install/
实时对象检测&如何训练自己的特殊模型:https://pjreddie.com/darknet/yolo/
优点
Darknet是一个比较小众的深度学习框架,没有社区,主要靠作者团队维护,所以推广较弱,用的人不多。而且由于维护人员有限,功能也不如tensorflow等框架那么强大,但是该框架还是有一些独有的优点:
1.易于安装
在makefile里面选择自己需要的附加项(cuda,cudnn,opencv等)直接make即可,几分钟完成安装;
2.没有任何依赖项
整个框架都用C语言进行编写,可以不依赖任何库,连opencv作者都编写了可以对其进行替代的函数;
3.运行速度快
P4 gpu卡上实测约35 fps(高清视频切桢图片)
4.结构明晰,源代码查看、修改方便,易于移植
其框架的基础文件都在src文件夹,而定义的一些检测、分类函数则在example文件夹,可根据需要直接对源代码进行查看和修改;
该框架部署到机器本地十分简单,且可以根据机器情况,使用cpu和gpu,特别是检测识别任务的本地端部署,darknet会显得异常方便。
5.友好python接口
虽然darknet使用c语言进行编写,但是也提供了python的接口,通过python函数,能够使用python直接对训练好的.weight格式的模型进行调用;
YOLO算法
YOLO(You Only Look Once)是Joseph Redmon针对这一框架提出的核心目标检测算法。

作者在YOLO算法中把物体检测问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。

YOLO算法的优点:
1、YOLO的速度非常快。在Titan X GPU上的速度是45 fps(frames per second),加速版的YOLO差不多是150fps。
2、YOLO是基于图像的全局信息进行预测的。这一点和基于sliding window以及region proposal等检测算法不一样。与Fast R-CNN相比,YOLO在误检测(将背景检测为物体)方面的错误率能降低一半多。
3、可以学到物体的generalizable-representations。可以理解为泛化能力强。
4、准确率高。有实验证明。
事实上,目标检测的本质就是回归,因此一个实现回归功能的CNN并不需要复杂的设计过程。YOLO没有选择滑窗或提取proposal的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好的区分目标和背景区域,相比之下,采用proposal训练方式的Fast-R-CNN常常把背景区域误检为特定目标。当然,YOLO在提升检测速度的同时牺牲了一些精度。

YOLO的设计理念遵循端到端训练和实时检测。YOLO将输入图像划分为S*S个网格,如果一个物体的中心落在某网格(cell)内,则相应网格负责检测该物体。

在训练和测试时,每个网络预测B个bounding boxes,每个bounding box对应5个预测参数,即bounding box的中心点坐标(x,y),宽高(w,h),和置信度评分。
这里的置信度评分(Pr(Object)*IOU(predtruth))综合反映基于当前模型bounding box内存在目标的可能性Pr(Object)和bounding box预测目标位置的准确性IOU(predtruth)。如果bouding box内不存在物体,则Pr(Object)=0。如果存在物体,则根据预测的bounding box和真实的bounding box计算IOU,同时会预测存在物体的情况下该物体属于某一类的后验概率Pr(Class_iObject)。
假定一共有C类物体,那么每一个网格只预测一次C类物体的条件类概率Pr(Class_iObject), i=1,2,…,C;每一个网格预测B个bounding box的位置。即这B个bounding box共享一套条件类概率Pr(Class_iObject), i=1,2,…,C。基于计算得到的Pr(Class_iObject),在测试时可以计算某个bounding box类相关置信度:Pr(Class_iObject)*Pr(Object)*IOU(predtruth)=Pr(Class_i)*IOU(predtruth)。
如果将输入图像划分为7*7网格(S=7),每个网格预测2个bounding box (B=2),有20类待检测的目标(C=20),则相当于最终预测一个长度为S*S*(B*5+C)=7*7*30的向量,从而完成检测+识别任务,整个流程可以通过下图理解。
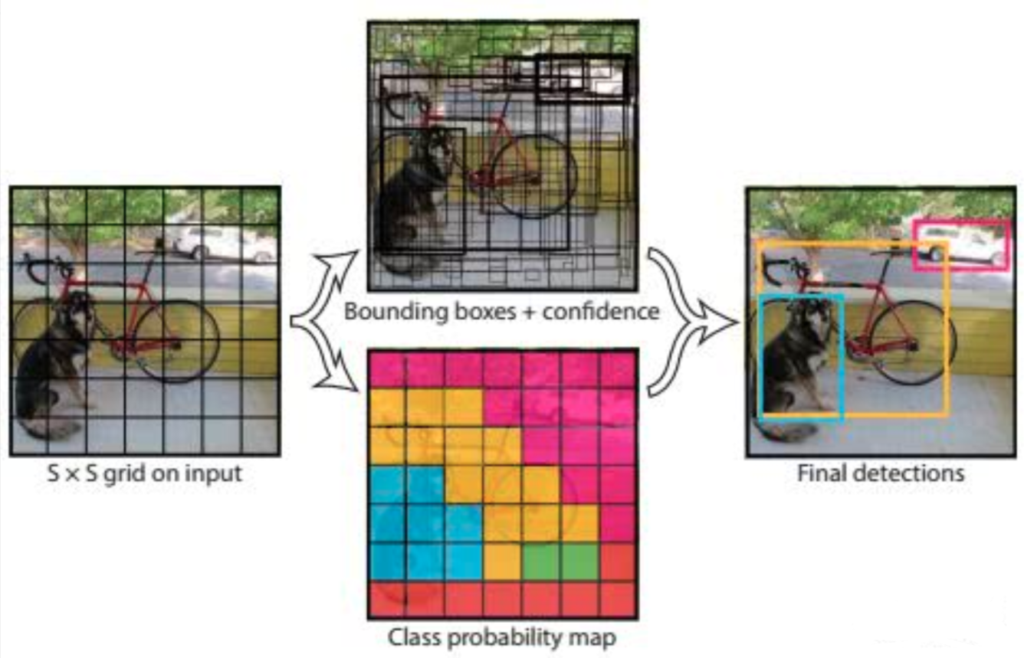
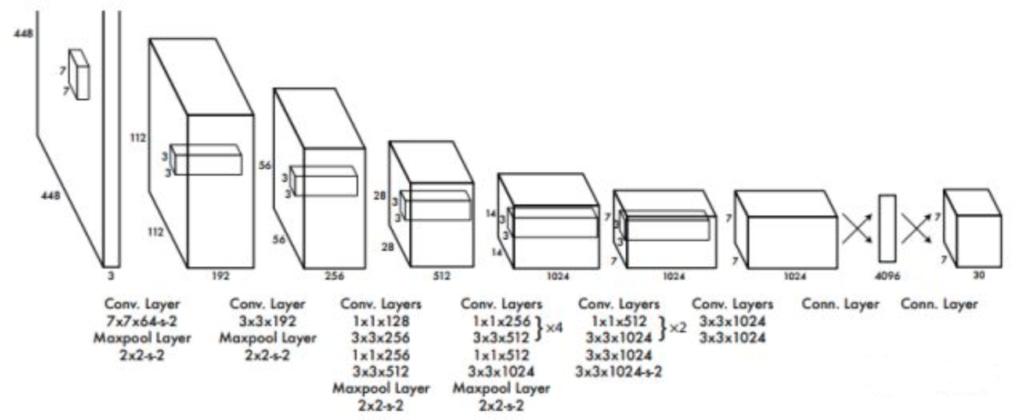
YOLO网络设计遵循了GoogleNet的思想,但与之有所区别。YOLO使用了24个级联的卷积(conv)层和2个全连接(fc)层,其中conv层包括3*3和1*1两种Kernel,最后一个fc层即YOLO网络的输出,长度为S*S*(B*5+C)=7*7*30.此外,作者还设计了一个简化版的YOLO-small网络,包括9个级联的conv层和2个fc层,由于conv层的数量少了很多,因此YOLO-small速度比YOLO快很多。如下图所示给出了YOLO网络的架构。
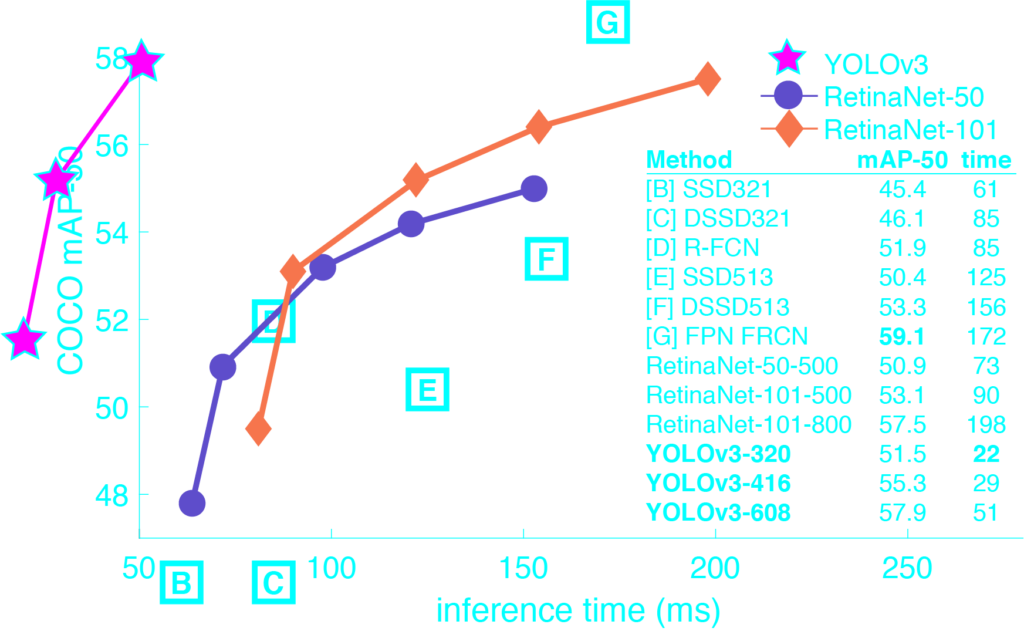
YOLOv3与其他算法的性能对比:
YOLO算法的缺点:
1、位置精确性差,对于小目标物体以及物体比较密集的场景检测效果不好,比如一群小鸟。
2、YOLO虽然可以降低将背景检测为物体的概率,但同时导致召回率较低。

YOLO的论文:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
如何使用
代码结构
下图是darknet源代码文件夹的分布情况:
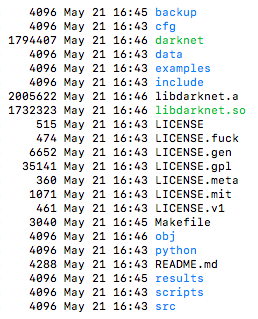
1.cfg文件夹内是一些模型的架构,每个cfg文件类似与caffe的prototxt文件,通过该文件定义的整个模型的架构
2.data文件夹内放置了一些label文件,如coco9k的类别名等,和一些样例图(该文件夹主要为演示用,或者是直接训练coco等对应数据集时有用,如果要用自己的数据自行训练,该文件夹内的东西都不是我们需要的)
3.src文件夹内全是最底层的框架定义文件,所有层的定义等最基本的函数全部在该文件夹内,可以理解为该文件夹就是框架的源码;
4.examples文件夹是更为高层的一些函数,如检测函数,识别函数等,这些函数直接调用了底层的函数,我们经常使用的就是example中的函数;
5.include文件夹,顾名思义,存放头文件的地方;
6.python文件夹里是使用python对模型的调用方法,基本都在darknet.py中。当然,要实现python的调用,还需要用到darknet的动态库libdarknet.so,这个动态库稍后再介绍;
7.scripts文件夹中是一些脚本,如下载coco数据集,将voc格式的数据集转换为训练所需格式的脚本等
8.Makefile文件,文件开头有一些选项,把你需要使用的选项设为1即可
安装
#Mac安装opencv
brew install opencv opencv@2 #前边是最新的v4.1版本,@2是老版本的v2.4
ln -s /usr/local/Cellar/opencv@2/2.4.13.7_3/lib/pkgconfig/opencv.pc /usr/local/lib/pkgconfig/opencv.pc #建立opencv.pc软链
#Centos安装opencv
yum install cmake gcc gcc-c++ gtk2-devel gimp-develgimp-devel-tools gimp-help-browser zlib-devel libtiff-devel libjpeg-devellibpng-devel gstreamer-devel libavc1394-devel libraw1394-devel libdc1394-develjasper-devel jasper-utils swig python libtool nasm -y
wget https://github.com/Itseez/opencv/archive/2.4.13.zip
vim CMakeLists.txt #设置安装位置
set(CMAKE_INSTALL_PREFIX "/home/work/.jumbo/opt/opencv")
cmake ./
make
make install
#检查opencv.pc文件
ll /usr/local/lib/pkgconfig/opencv.pc
#添加path
export LD_LIBRARY_PATH=/home/work/.jumbo/opt/opencv/lib:${LD_LIBRARY_PATH}
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig #指定pkgconfig目录位置
#编辑配置
vim Makefile
GPU=1 #使用GPU
CUDNN=1 #使用CUDNN
OPENCV=1 #使用OPENCV
OPENMP=0
DEBUG=0
#安装
make
#检查是否安装成功
./darknet
检测
#下载训练好的权重文件
wget https://pjreddie.com/media/files/yolov3.weights #完整版 237M
wget https://pjreddie.com/media/files/yolov3-tiny.weights #mini版 34M
#测试对象检测(-thresh参数:对象识别置信度默认>0.25;检测结果输出到out.png)
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0.9 -out out
or #两个命令等同
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0.25
或 使用精简版模型
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg -thresh 0.55 -out out-tiny
#python接口
python ./python/darknet.py #python3运行所有字符串参数增加str.encode("cfg/yolov3.cfg")
运行输出:(注:在mac等非gpu机器上比较慢)
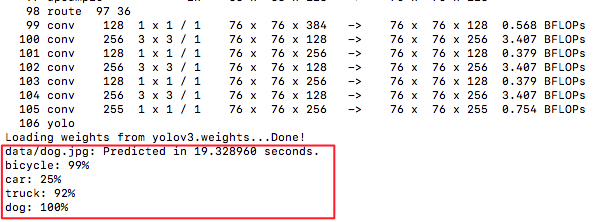
检测效果:out.png

儿子比赛的照片识别效果:
#打开摄像头实时检测(依赖GPU=1 OPENCV=1 make编译;-c参数:指定使用哪个摄像头)
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights -c 0 #这个实时检测非GPU基本跑不动
#检测指定视频文件(-prefix参数:以此参数值为前缀保存处理后的每一帧图片)
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights data/football.mp4 -thresh 0.9 -prefix football -out_filename data/football.out.mp4
*注:-out_filename不好使不知道咋回事,用ffmpeg合成了一下:ffmpeg -i ./football/video-%d.jpg -c:v libx264 -vf "fps=25,format=yuv420p" football.out.mp4
视频对象检测效果:
图像理解:

如何训练自定义模型
下篇单独讲,参考https://pjreddie.com/darknet/yolo/中的 Training YOLO on VOC
参考:
https://pjreddie.com/
https://www.cnblogs.com/CZiFan/p/9516504.html
https://blog.csdn.net/u010122972/article/details/83541978
https://cloud.tencent.com/developer/news/76803
5分钟学会Yolo – How to use YOLO with python
DarkNet-YOLOv3 训练自己的数据集 Ubuntu16.04+cuda8.0
