CAP是什么?
CAP理论,被戏称为[帽子理论]。CAP理论由Eric Brewer在ACM研讨会上提出,而后CAP被奉为分布式领域的重要理论【link1】 。
分布式系统的CAP理论
首先把分布式系统中的三个特性进行了如下归纳:
- 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
- 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- 分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
高可用、数据一致性是很多系统设计的目标,但是分区又是不可避免的事情。我们来看一看分别拥有CA、CP和AP的情况。
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是你想不想的问题,而是始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。

from:http://www.cs.berkeley.edu/~brewer/cs262b-2004/PODC-keynote.pdf
CP without A:如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。

from 同上
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。

from 同上
CAP理论的证明
该理论由brewer提出,2年后就是2002年,Lynch与其他人证明了Brewer猜想,从而把CAP上升为一个定理。
但是,它只是证明了CAP三者不可能同时满足,并没有证明任意二者都可满足的问题,所以,该证明被认为是一个收窄的结果。
Lynch的证明相对比较简单:采用反证法,如果三者可同时满足,则因为允许P的存在,一定存在Server之间的丢包,如此则不能保证C,证明简洁而严谨。
在该证明中,对CAP的定义进行了更明确的声明:
- C:一致性被称为原子对象,任何的读写都应该看起来是“原子“的,或串行的。写后面的读一定能读到前面写的内容。所有的读写请求都好像被全局排序一样。
- A:对任何非失败节点都应该在有限时间内给出请求的回应。(请求的可终止性)
- P:允许节点之间丢失任意多的消息,当网络分区发生时,节点之间的消息可能会完全丢失。
CAP理论澄清
[CAP理论十二年回顾:”规则”变了]一文首发于 Computer 杂志,后由InfoQ和IEEE联合呈现,非常精彩,文章表达了几个观点【link2】。
“三选二”是一个伪命题
不是为了P(分区容忍性),要在A和C之间选择一个。分区很少出现,CAP在大多数时候允许完美的C和A。但当分区存在或可感知其影响的情况下,就要预备一种策略去探知分区并显式处理其影响。
这样的策略应分为三个步骤:
- 探知分区发生
- 进入显式的分区模式以限制某些操作
- 启动恢复过程以恢复数据一致性并补偿分区期间发生的错误。
“一致性的作用范围”其实反映了这样一种观念,即在一定的边界内状态是一致的,但超出了边界就无从谈起。
比如在一个主分区内可以保证完备的一致性和可用性,而在分区外服务是不可用的。Paxos算法和原子性多播(atomic multicast)系统一般符合这样的场景。
像Google的一般做法是将主分区归属在单个数据中心里面,然后交给Paxos算法去解决跨区域的问题,一方面保证全局协商一致(global consensus)如Chubby,一方面实现高可用的持久性存储如Megastore。
ACID、BASE、CAP
ACID和BASE 这两个术语都好记有余而精确不足,出现较晚的BASE硬凑的感觉更明显,它是“Basically Available, Soft state, Eventually consistent(基本可用、软状态、最终一致性)”的首字母缩写。
其中的软状态和最终一致性这两种技巧擅于对付存在分区的场合,并因此提高了可用性。
CAP与ACID的关系更复杂一些,也因此引起更多误解。其中一个原因是ACID的C和A字母所代表的概念不同于CAP的C和A。还有一个原因是选择可用性只部分地影响ACID约束。
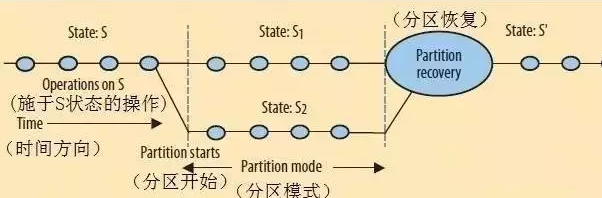
进一步看[分区]之后
用一下这张图[引用自 link 2],在状态S的时候是非分区状态,而分区模式则演化出来了S1,S2,那么问题来了,分区恢复之后,状态究竟是多少呢?有几种解决方案?
1、分区恢复策略:可交换多副本数据类型
注意,能支持此类处理的场景是有限的。
riak_dt 就是这样一种保障最终一致性实现的数据结构,它分为Operation-based CRDTs、State-based CRDTs 2种形态。
riak_dt link参见 link 3。

from:https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type
2、分区恢复策略:回放合并
在分区恢复过程中,设计师必须解决两个问题:
分区两侧的状态最终必须保持一致
并且必须补偿分区期间产生的错误
如上图所示,对于分区恢复的状态S*可以通过未分区时的状态S为起点,然后按顺序[回放]相应的变化事件[以特定方式推进分区两侧的一系列操作,并在过程中一直保持一致的状态。
Bayou[link 4]就是这个实现机制,它会回滚数据库到正确的时刻并按无歧义的、确定性的顺序重新执行所有的操作,最终使所有的节点达到相同的状态。
对于有冲突的情况,比如版本管理软件cvs,存在人工介入、消除冲突的处理策略。
3、有限制处理
有限制处理:[link 2]提的自动柜员机补偿问题,比较形象说明了这个问题。此问题本质上是可用性和一致性的折衷处理。
以自动柜员机(ATM)的设计来说,强一致性看似符合逻辑的选择,但现实情况是可用性远比一致性重要。理由很简单:高可用性意味着高收入。
不管怎么样,讨论如何补偿分区期间被破坏的不变性约束,ATM的设计很适合作为例子。
ATM的基本操作是存款、取款、查看余额。关键的不变性约束是余额应大于或等于零。因为只有取款操作会触犯这项不变性约束,也就只有取款操作将受到特别对待,其他两种操作随时都可以执行。
ATM系统设计师可以选择在分区期间禁止取款操作,因为在那段时间里没办法知道真实的余额,当然这样会损害可用性。现代ATM的做法正相反,在stand-in模式下(即分区模式),ATM限制净取款额不得高于k,比如k为$200。
- 低于限额的时候,取款完全正常;
- 当超过限额的时候,系统拒绝取款操作。
这样,ATM成功将可用性限制在一个合理的水平上,既允许取款操作,又限制了风险。
分区结束的时候,必须有一些措施来恢复一致性和补偿分区期间系统所造成的错误。
状态的恢复比较简单,因为操作都是符合交换率的,补偿就要分几种情况去考虑。
- 最后的余额低于零违反了不变性约束。由于ATM已经把钱吐出去了,错误成了外部实在。银行的补偿办法是收取透支费并指望顾客偿还。因为风险已经受到限制,问题并不严重。
- 还有一种情况是分区期间的某一刻余额已经小于零(但ATM不知道),此时一笔存款重新将余额变为正的。银行可以追溯产生透支费,也可以因为顾客已经缴付而忽略该违反情况。
总而言之,因为通信延迟的存在,银行系统不依靠一致性来保证正确性,而更多地依靠审计和补偿。
“空头支票诈骗”也是类似的例子,顾客赶在多家分行对账之前分别取出钱来然后逃跑。透支的错误过后才会被发现,对错误的补偿也许体现为法律行动的形式。
此前,中行IBM大型机宕机,系统没有第一时间切换到热备或者异地容灾上,直接影响中行的信用卡支付相关业务,直到4小时之后才恢复服务。
有对应的的原因包括日常演练等问题,等更重要的是在[可用性和一致性]之间选择了一致性,4H之后提供服务,备库仍然主要起数据备份的作用。
有限制处理方案是需要冒险滴,为了保障可用性,无法保障数据100%精确,可以折衷提供部分有损服务。
比如取款根据信用是不是能限制一定金额,而存款是Ok的等等。大额对公业务也可以采取具体办法,当然这将在精细化管理服务能力及配套能力上付出更多的IT成本。
有关中行IBM大型机宕机的报道link:
超越CAP?
Nathan Marz:How to beat the CAP theorem
2011年11月Twitter的首席工程师Nathan Marz写了一篇文章,描述了他是如何试图打败CAP定理的: How to beat the CAP theorem
作者表示不是要“击败”CAP,而是尝试对数据存储系统进行重新设计,以可控的复杂度来实现CAP。Marz认为一个分布式系统面临CAP难题的两大问题就是:
在数据库中如何使用不断变化的数据
如何使用算法来更新数据库中的数据
Marz提出了2个基本思路:
1、数据不存在update,只存在append操作。这样就把对数据的处理由CRUD变为CR;同样的,delete操作也可以处理为add一条新记录。
比如 友强取消了对山丘的关注,传统关系型数据库是在关系表删除一条记录,而Marz也可以新增一条关系为[取消]的记录。
2、所有的数据的操作就只剩下Create和Read。把Read作为一个Query来处理,而一个Query就是一个对整个数据集执行一个函数操作。
总结,在有一定时序性,且对实时一致性要求不高的场景下可以选择使用,毕竟在问题解决域多了一把锤子。Query过程中的跨分区函数仍然是一种合并的变种(Merge)!
OceanBase的另类之路
既然更新数据涉及到分区问题,那么能不能把更新放到一个服务器呢[脑洞大开]?然后通过强大的软件+硬件能力一起去保障它!同时已经不修改的数据天然具备可扩展性!这是我粗暴理解OceanBase的基本设计思想。
link5 写道:作为电子商务企业,淘宝和其他公司的业务对一致性和可用性的要求高于分区容错性,数据特征是数据总量庞大且逐步增加,单位时间内的数据更新量并不大,但实时性要求很高。
这就要求我们提供一套更加偏重于支持CA特性的系统,同时兼顾可分区性,并且在实时性、成本、性能等方面表现良好。
OceanBase的逻辑架构简图

关于UpdateServer的性能问题
其实大部分数据库每天的修改次数相当有限,只有少数修改比较频繁的数据库才有每天几亿次的修改次数。另外,数据库平均每次修改涉及的数据量很少,很多时候只有几十个字节到几百个字节。
假设数据库每天更新1亿次,平均每次需要消耗100字节,每天插入1000万次,平均每次需要消耗1000字节,那么,一天的修改量为:1亿 100 + 1000万 1000 = 20GB,如果内存数据结构膨胀2倍,占用内存只有40GB。
而当前主流的服务器都可以配置96GB内存,一些高档的服务器甚至可以配置192GB、384GB乃至更多内存。
TiDB
TiDB 是国内 PingCAP 团队开发的一个分布式 SQL 数据库。其灵感来自于 Google 的 F1, TiDB 支持包括传统 RDBMS 和 NoSQL 的特性。
从下面这篇访谈来看,分布式事务早期版本中,他们参考的是 Google 的 Percolator 的模型。由于该项目还未在线上产品使用,就不具体展开了,有兴趣的朋友参考下面的link6。
1 link:http://www.cs.berkeley.edu/~brewer/cs262b-2004/PODC-keynote.pdf
2 link:http://www.infoq.com/cn/articles/cap-twelve-years-later-how-the-rules-have-changed/
3 link:https://github.com/basho/riak_dt
4 link:http://www.cs.berkeley.edu/~brewer/cs262b/update-conflicts.pdf
总结:
CAP是分布式领域的重要理论,但不代表完全不能有延展的解读和思考。另外[三选二]本身也是有条件成立的,不能简单误读,一切取决于应用场景。如果不加选择按照理论形式无异于刻舟求剑。
作者:于君泽,蚂蚁金服高级技术专家、支付核算技术部负责人,关注方向:高并发、分布式系统、稳定性模式;内建质量、技术型管理。
摘自:https://mp.weixin.qq.com/s?__biz=MzA4Nzg5Nzc5OA==&mid=2651660931&idx=1&sn=93cccfdcc5a474e92ffd673e7cd115ce&scene=0&key=77421cf58af4a65326f9f915849643f2e925037bf94f2bc7a4e46c875cdd89e9277807e12c2ceae05e5a991879bb538d&ascene=0&uin=Mjk1ODMyNTYyMg%3D%3D&devicetype=iMac+MacBookPro11%2C4+OSX+OSX+10.11.5+build(15F34)&version=11020201&pass_ticket=Xj5gTEleI8UL7wuZjEmaeOk1k%2BgtmTMDmWMhC%2Fzjcr6WfwlqgyWnDoZE5WkKImIg
