概述
ssdb是一个大规模持久化kv存储,类似redis,只是存储介质增加了ssd+sata,适合写入redis数据和qps规模较大,数据读取占比较小,想降低redis内存服务器购买成本,同时使读写性能上损失小些。有朋友公司使用了1T+的ssdb,想实现高可用方案,一直比较忙… 这两天终于有空研究了一下,给一个简单的多主水平分片+主从热备+读写分离代理解决方案。
SSDB
SSDB 是一个 C/C++ 语言开发的高性能 NoSQL 数据库, 支持 KV, list, map(hash), zset(sorted set) 等数据结构, 用来替代或者与 Redis 配合存储十亿级别列表的数据。
特点:
1.底层的LevelDB使用LSM存储引擎,相比与关系数据库的B-Tree,写性能更好,而牺牲了部分的读性能。适合写多读少的场景,或读热key相对集中,缓存命中率较高的场景。
2.LSM树整个结构不是有序的,所以不知道数据在什么地方,需要从每个小的有序结构中做二分查询,找到了就返回,找不到就继续找下一个有序结构。在缓存命中率较低时,磁盘读取性能较差。故单个分片容量不宜过大,否则磁盘读性能不可接受。
github:https://github.com/ideawu/ssdb
SSDB中文手册:http://ssdb.io/zh_cn/
SSDB入门基础:https://github.com/ideawu/ssdb-docs/blob/master/pdf/SSDB%E5%85%A5%E9%97%A8%E5%9F%BA%E7%A1%80.pdf
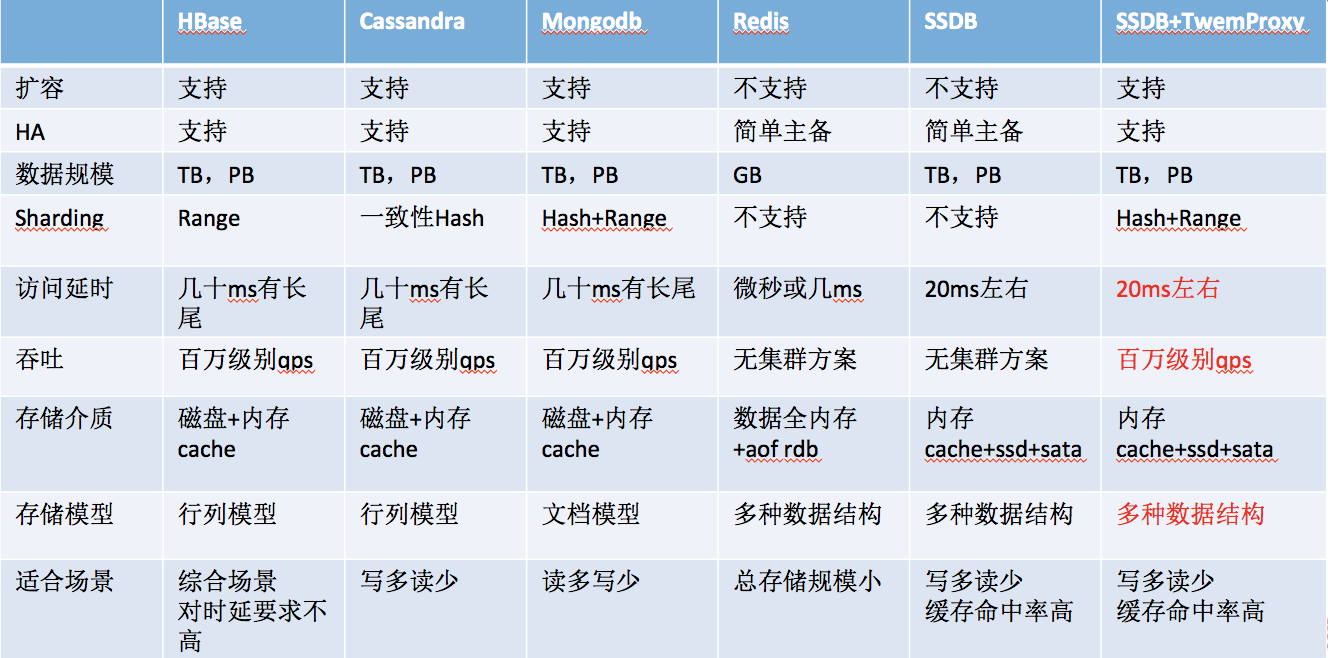
对比:
TwemProxy
twemproxy是搭建分布式集群的重要组件之一,它的分片功能,可以轻松地对redis/mecache集群进行水平扩展。同时对于代码稍加改造,我们就可以得到能读写分离的redis集群,这大大将提高了redis集群的性能。而ssdb兼容redis协议,故它也能用在为ssdb做水平分片。
一个简单的twemproxy+ssdb架构方案:

LVS用于解决大负载时twemproxy可能成为性能瓶颈的问题,各twemproxy配置一摸一样,和任意算法负载。LVS可以用HAproxy代替。
Twemproxy配置ssdb多主hash水平分片,并配置读写分离代理。
SSDB配置1主多从,实现热备和读写分离。
github:https://github.com/twitter/twemproxy/
twemproxy架构分析:https://www.cnblogs.com/onlyac/p/6262096.html
安装
安装SSDB单实例
#安装依赖
su root
yum install autoconf automake gcc+ gcc-c++ libtool jemalloc snappy snappy-devel -y
autoconf -V
#编译安装ssdb
mkdir /home/work/ssdb/
wget --no-check-certificate https://github.com/ideawu/ssdb/archive/master.zip -O ssdb-master.zip
unzip ssdb-master.zip
cd ssdb-master
make
make install PREFIX=/home/work/ssdb
cp ./tools/ssdb.sh /home/work/ssdb/
vim ssdb.sh
ssdb_root=/home/work/ssdb
configs="/home/work/ssdb/ssdb.conf"
#启动ssdb
./ssdb.sh start #[start|stop|restart]
#kv读写测试
./ssdb-cli -h 127.0.0.1 -p 8888
ssdb 127.0.0.1:8888> set k1 abc
ok
ssdb 127.0.0.1:8888> get k1
abc
ssdb 127.0.0.1:8888> del k1
ok
#hashmap读写测试(按key排序)
ssdb 127.0.0.1:8888> hsize h
0
ssdb 127.0.0.1:8888> hset h k1 a
ok
ssdb 127.0.0.1:8888> hset h k2 c
ok
ssdb 127.0.0.1:8888> hset h k3 b
ok
ssdb 127.0.0.1:8888> hscan h "" "" 10
key value
-------------------------
k1 : a
k2 : c
k3 : b
3 result(s) (0.000 sec)
ssdb 127.0.0.1:8888> hclear h
3
#zset读写测试(按value排序)
ssdb 127.0.0.1:8888> zset z k1 2
ok
ssdb 127.0.0.1:8888> zset z k2 0
ok
ssdb 127.0.0.1:8888> zset z k3 1
ok
ssdb 127.0.0.1:8888> zscan z "" "" "" 10
key value
-------------------------
k2 : 0
k3 : 1
k1 : 2
3 result(s) (0.000 sec)
ssdb 127.0.0.1:8888> zclear z
3
#自动启动
cp ./ssdb.sh /etc/init.d/ssdb
sudo chkconfig --add ssdb
sudo chkconfig ssdb on
SSDB安装:http://ssdb.io/docs/zh_cn/install.html
SSDB命令:http://ssdb.io/docs/zh_cn/commands/index.html
phpssdbadmin:https://github.com/ssdb/phpssdbadmin
搭建SSDB主从

#说明
这里以127.0.0.1:8888为主,127.0.0.1:8889为从进行主从搭建模拟
#配置并启动slave从库
vim ssdb_slave.conf #配置master host/port及同步方式
server:
ip: 127.0.0.1
port: 8889
readonly: yes #从库设为只读
replication:
binlog: yes
sync_speed: -1
slaveof:
id: svc_1
type: sync
host: 127.0.0.1
port: 8888
#增加slave configs配置
vim ssdb.sh
configs="/home/work/ssdb/ssdb.conf /home/work/ssdb/ssdb_slave.conf"
#启动slave
./ssdb.sh restart
#检查slave从库同步状态
./ssdb-cli -h 127.0.0.1 -p 8888 #master set
ssdb 127.0.0.1:8888> set k1 abc
ok
./ssdb-cli -h 127.0.0.1 -p 8889 #slave get
ssdb 127.0.0.1:8889> get k1
abc
ssdb 127.0.0.1:8889> info #slave sync_count、last_seq
replication
slaveof 127.0.0.1:8888
id : svc_1
type : sync
status : SYNC
last_seq : 19
copy_count : 0
sync_count : 1
SSDB同步和复制的配置与监控:http://ssdb.io/docs/zh_cn/replication.html
SSDB源码分析 – 主从和多主同步原理解析:http://www.ideawu.net/blog/archives/849.html
搭建SSDB双主(不推荐)

双主mirror主要用于故障快速切换,平时只往其中一个写,当出现故障时, 整体切换到另一个主上面。
SSDB 双主的配置非常简单,只需要将 type 设置为 mirror,然后每个主节点各指向对方即可。
如果是多主, 则每个节点要指向其它 n-1 个节点,以避免在多主都打开写时出现数据丢失的情况。
注意:
1.除非应用层能避免双主同时操作相同 key,否则不能打开双主同时写。
2.不打开多主同写的方案下,主2的作用其实可以用slave代替,以实现master故障后的主切换。
#说明
这里以127.0.0.1:8888为主1,127.0.0.1:8889为slave1,127.0.0.1:8887为主2 进行多主搭建模拟
#配置主2
cp ssdb.conf ssdb_mirror.conf
mkdir ./var_mirror
vim ssdb_mirror.conf #配置与master1相互mirror
work_dir = ./var_mirror
pidfile = ./var_mirror/ssdb.pid
server:
ip: 127.0.0.1
port: 8887
readonly: yes #主2暂时设为只读
replication:
binlog: yes
sync_speed: -1
slaveof:
id: svc_1
type: mirror
host: 127.0.0.1
port: 8888
logger:
level: debug
output: log_mirror.txt
vim ssdb.conf #配置与matser2相互mirror
server:
ip: 127.0.0.1
port: 8888
replication:
binlog: yes
sync_speed: -1
slaveof:
id: svc_2
type: mirror
host: 127.0.0.1
port: 8887
#增加slave configs配置
vim ssdb.sh
configs="/home/work/ssdb/ssdb.conf /home/work/ssdb/ssdb_slave.conf /home/work/ssdb/ssdb_mirror.conf"
#启动双主
./ssdb.sh restart
ps aux |grep ssdb
#检查双主镜像同步状态
./ssdb-cli -h 127.0.0.1 -p 8887 #master2 mirror copy check
ssdb 127.0.0.1:8888> get k1
abc
./ssdb-cli -h 127.0.0.1 -p 8888 #master1 new set
ssdb 127.0.0.1:8888> set k2 xyz
ok
ssdb 127.0.0.1:8888> get k2 #master2 new get
xyz
./ssdb-cli -h 127.0.0.1 -p 8889 #slave1 check
ssdb 127.0.0.1:8889> get k2
xyzSSDB主-主:http://ssdb.io/docs/zh_cn/replication.html
ssdb双主模型配置:https://www.cnblogs.com/reblue520/p/6874558.html
安装TwemProxy
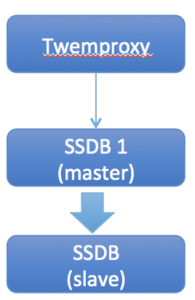
#安装twemproxy
cd /home/work
wget https://github.com/twitter/twemproxy/archive/master.zip -O twemproxy-master.zip
unzip twemproxy-master.zip && mv twemproxy-master twemproxy
cd /home/work/twemproxy
autoreconf -fvi
./configure && make
sudo make install
#注意,twemproxy默认安装到了当前目录
#配置
cp conf/nutcracker.yml ./nutcracker.ssdb.yml
vim nutcracker.ssdb.yml
ssdb:
listen: 127.0.0.1:22121
hash: fnv1a_64 #一致性hash算法
distribution: ketama
#auto_eject_hosts: true
redis: true
server_retry_timeout: 1000
server_failure_limit: 1
servers:
- 127.0.0.1:8888:1 #指向ssdb master1
#启动
./src/nutcracker -d -c ./nutcracker.ssdb.yml
ps -aux | grep nutcracker
#连接测试(twemproxy只支持redis协议,需要用redis客户端测试ssdb)
sudo yum install redis
redis-cli -h 127.0.0.1 -p 8888 #测试连接master1
127.0.0.1:8888> get k1
"abc"
redis-cli -h 127.0.0.1 -p 22121 #测试连接twemproxy
127.0.0.1:22121> get k1
"abc"http://jinnianshilongnian.iteye.com/blog/2186787
TwemProxy水平切分ssdb
这里会先去掉前边的双主mirror方案,使双主之间没有关系,各自作为一个水平分片,分片代理由twemproxy完成。

#搭建两个主ssdb水平分片
vim ssdb.conf #8888端口db
vim ssdb_mirror.conf #8887端口db
注释掉两个文件中replication.slaveof:下的所有配置项并重启,解除两个主之间的相互mirror。
./ssdb.sh restart
#确定两个db已隔离
./ssdb-cli -h 127.0.0.1 -p 8887
ssdb 127.0.0.1:8887> set t1 1
ok
ssdb 127.0.0.1:8887> get t1
1
./ssdb-cli -h 127.0.0.1 -p 8888
ssdb 127.0.0.1:8888> get t1
not_found
#设置twemproxy水平分片
vim /home/work/twemproxy/nutcracker.ssdb.yml
ssdb-write: #读写
listen: 127.0.0.1:22121 #twemproxy监听地址
hash: fnv1a_64 #key值的hash算法
distribution: modula #ketama一致性hash算法;modula根据key值的hash值取模
redis: true #服务器的通讯协议
auto_eject_hosts: true #是否应该根据server的连接状态重建群集
server_retry_timeout: 2000 #server的连接状态检测超时时间
server_failure_limit: 1 #server的连接状态检测连接次数
servers: #server pool(地址:端口:权重 服务器名)
- 127.0.0.1:8888:1 master1
- 127.0.0.1:8887:1 master2
ssdb-read: #只读
listen: 127.0.0.1:22122 #twemproxy监听地址
hash: fnv1a_64 #key值的hash算法
distribution: modula #ketama一致性hash算法;modula根据key值的hash值取模
redis: true #服务器的通讯协议
auto_eject_hosts: true #是否应该根据server的连接状态重建群集
server_retry_timeout: 2000 #server的连接状态检测超时时间
server_failure_limit: 1 #server的连接状态检测连接次数
servers: #server pool(地址:端口:权重 服务器名)
- 127.0.0.1:8889:1 slave1_1
- 127.0.0.1:8890:1 slave2_1 #这个slave2自行搭建不再赘述
#重启twemproxy
ps aux | grep nutcracker |grep -v grep| cut -c 9-15 | xargs kill -9
/home/work/twemproxy/src/nutcracker -d -c /home/work/twemproxy/nutcracker.ssdb.yml
ps aux | grep nutcracker
#测试twemproxy分片效果
redis-cli -h 127.0.0.1 -p 22121 #使用twemproxy ssdb-write写入c1、c2
127.0.0.1:22121> set c1 1
OK
127.0.0.1:22121> set c2 2
OK
./ssdb-cli -h 127.0.0.1 -p 8888 #查询db1
ssdb 127.0.0.1:8888> get c1
not_found
ssdb 127.0.0.1:8888> get c2
2
./ssdb-cli -h 127.0.0.1 -p 8887 #查询db2
ssdb 127.0.0.1:8887> get c1
1
ssdb 127.0.0.1:8887> get c2
not_found
./ssdb-cli -h 127.0.0.1 -p 8889 #查询db1-slave
ssdb 127.0.0.1:8889> get c1
not_found
ssdb 127.0.0.1:8889> get c2
2
redis-cli -h 127.0.0.1 -p 22122 #使用twemproxy ssdb-read读取
127.0.0.1:22122> get c1
"1"
127.0.0.1:22122> get c2
"2"
水平分片验证通过至此,主从+多主水平分片+读写分离代理验证通过。
TODO:
1.可增加zk进行服务注册
2.master故障需要能秒切
3.需增加各环节的故障监控报警
yan 18.11.29 20:01
资料
SSDB各语言SDK:http://ssdb.io/docs/zh_cn/clients.html
备份SSDB数据:http://ssdb.io/docs/zh_cn/backup.html
Linux单机如何支持百万连接数:http://www.ideawu.net/blog/archives/740.html
Redis+Twemproxy安装与使用:http://jinnianshilongnian.iteye.com/blog/2186787
